浅析CAP理论
CAP理论是Eric Brewer在2000年前后提出的一个设计上的折中原则,大意是说,一个系统在Consistency、Availability、Partition Tolerance三者之间无法兼顾,必须舍弃一个。CAP理论作为一个设计折中原则,在后面的几年被人误解,因此Eric Brewer在2012年又写了一篇文章,着重解释了CAP的一些误解,一个系统并非一定要预先在CAP中彻底牺牲一个属性,更多的场景下,没有P发生时,CA可以兼得,而在P发生时,可以选择C或A中的一个,并在P结束后恢复。
CAP理论是Eric Brewer在2000年前后提出的一个设计上的折中原则,大意是说,一个系统在Consistency、Availability、Partition Tolerance三者之间无法兼顾,必须舍弃一个。
Eric Brewer是加州大学伯克利分校的教授,同时是Inktomi(2003年被雅虎收购)的联合创始人和首席科学家,现在Google做基础设施建设。跟Micheal Stonebraker一样,也是一位跨学术和产业界的大牛。CAP理论就是Brewer在具体实现系统时总结提炼的设计原则。2002年,Seth Gilbert和Nanncy Lynch就CAP理论给出了较为形式化的证明。CAP理论作为一个设计折中原则,在后面的几年被人误解,因此Eric Brewer在2012年又写了一篇文章,着重解释了CAP的一些误解,一个系统并非一定要预先在CAP中彻底牺牲一个属性,更多的场景下,没有P发生时,CA可以兼得,而在P发生时,可以选择C或A中的一个,并在P结束后恢复。
CAP理论内容
CAP理论:任何一个网络连接起来,有数据共享(networked shared-data)的分布式系统,在consistency、availability和partition tolerant三者中无法兼顾,只能舍弃一个。其中,
- consistency (C):任何时候,从任何副本都能读取到最新的数据,等价于系统只有一个副本(永远保持最新)。
- high availability (A):数据的高可用性。
- partition tolerant (P):容忍分区。
有几个说明:
- 这里说的分布式系统是指有多副本的分布式系统,有些分布式系统例如MPP类型的OLAP系统,本身很少写入,数据也不共享,每份数据完全独立,因此也谈不上CAP折中。
- 这里consistency是指strict consistency,比如有多个副本,某个副本更新完,其他副本也立刻就能达到最新状态。
CAP理论的形式化证明
Theorem 1:在异步网络模型中,针对一个数据对象的读写无法同时保证高可用和强一致。
说明,这里的异步网络模型,就是我们通常理解的分布式系统模型,每个节点都有一个本地的时钟,不同节点的时钟快慢可能不同(即逻辑时钟),网络可能丢消息(即分区)。定理1说的是,在一个可能存在P的系统中,无法同时实现CA。
证明过程:
通过反证法。假设存在一个算法X能够在P下还同时保证CA,我们构造一个返回不一致的请求。
假设系统有两个节点,并且这两个节点网络分区成{G1, G2},G1和G2之间的消息全部丢失。如果一个写操作发生在G1,稍后的一个读操作发生在G2,那么即使读操作是在写操作完成之后才开始,读操作也无法读到前面写操作的数据。
严格一点描述,设数据对象初始为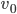 ,设
,设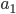 是算法的在处理写操作(该写操作的数据不等于)的执行序列,该写请求发生在G1。因为系统要满足X保证的Availability,因此写操作一定在一段时间之后结束了。设
是算法的在处理写操作(该写操作的数据不等于)的执行序列,该写请求发生在G1。因为系统要满足X保证的Availability,因此写操作一定在一段时间之后结束了。设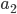 是算法的在处理读操作的执行序列,该读请求发生在G2,同样,因为系统要满足X保证的Availability,因此读操作一定在一段时间之后结束了。因为G1和G2之间没有任何消息通信,因此读操作一定读到的是)。设
是算法的在处理读操作的执行序列,该读请求发生在G2,同样,因为系统要满足X保证的Availability,因此读操作一定在一段时间之后结束了。因为G1和G2之间没有任何消息通信,因此读操作一定读到的是)。设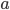 是之后紧跟的执行序列,在中,读请求读不到最新的数据,而读请求是在写请求结束之后才开始的,因此不满足C。
是之后紧跟的执行序列,在中,读请求读不到最新的数据,而读请求是在写请求结束之后才开始的,因此不满足C。
因为证明过中建模语言也不是完全的数学语言,这个勉强算是比较严格的证明。Lamport创造了TLA+这种模型检测语言,如果用这种方法证明,可能严格性更好。
CAP理论的一些误解
关于CAP理论的一些误解:
- 分区很少发生,如果没有发生分区,CA是可以同时达成的。
- CA的选择:不同子系统可以选择不同的策略,同一个系统在不同情况下也可以选择不同的策略。
- CAP三个属性都是连续的值,而不是二值选项。Availability可以是0~100,consistency也可以强弱不同,分区是否发生也并非简单的二值。
经典的CAP解读并没有考虑延迟。CAP的精髓在于当超时发生时,在一段时间内必须做一个根本性的决定(partition decision):是取消后续操作(降低了可用性)还是继续后续操作(可能违背一致性)。二者一定要选择一个,超时无限重试只是在拖延做决定的时间,最终等价于选择了前者。
从编程角度,分区并不是一个全局共识,有些节点认为发生了分区,有些节点可能认为没有。节点在检测到分区之后,进入分区模式,此时在CA之间做选择。具体系统实现时,可以通过超时时间阈值检测分区。
CAP理论的指导意义在于,设计者要在分区发生时,显式处理分区,降低分区对CA的影响。当节点检测到分区时,进入分区模式,限制某些操作,在通信恢复后,开始进行分区恢复。如下图。
如果不发生分区,则状态S是可以被保持一致性的,同时可用性可以保证。当检测到分区,系统进入分区模式,此时就要做决定,允许某些可能导致一致性问题的操作继续执行。系统可能产生了不一致的状态S1、S2。在发现网络通信恢复之后,在退出分区模式之前,要将系统状态重新恢复为一致的状态。
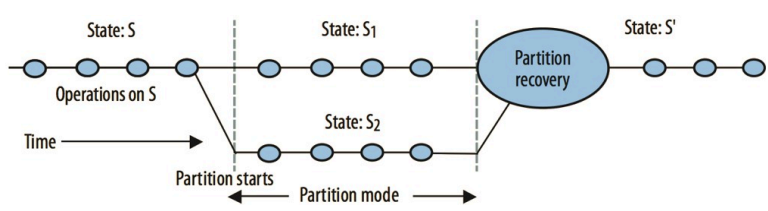
从这个图我们可以看到,问题的困难在于,设计者要思考每一个不变量的维护情况,并有针对性地在Partition recovery过程中将该不变量恢复到一致状态。恢复过程需要对分区模式下做的修改进行追踪,通过版本向量是一个很好的方法,版本向量可以反映操作时间的因果依赖。有研究表明,当我们选择了可用性优先,通常最多只能将一致性恢复到这样的程度。分区恢复时,要做两件事情:两侧的状态最终必须保持一致,必须补偿分区期间产生的错误。而后者往往会影响系统上层业务。