以史为鉴:数据模型变迁史
这两天看了篇数据模型的论文,What Goes Around Comes Around。这篇论文是2005年Stonebraker和Hellerstein两位泰斗写的,讲的是数据库的数据模型35年的变迁历史,另外论文还总结了一些经验。
这是一个非常有趣的话题,能够让我们更多地去从市场和产品角度看问题,尤其是考虑到不断迭代的甚至是越来越快地迭代的数据库技术。
数据模型Data Model的9个历史阶段:
- Hierarchical(IMS): 1960年代末到1970年代
- Network(CODASYL): 1970年代
- Relational: 1970年代到1980年代初
- Entity-Relationship: 1970年代
- Semantic: 1970年代末到1980年代
- Object-orientied: 1980年代末到1990年代初
- Object-relational: 1980年代末到1990年代初
- Semi-structured(XML): 1990年代末至今(注2005)
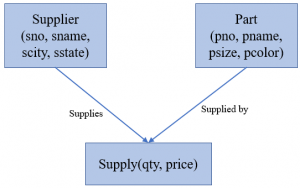
在讲述这几个模型前,先描述一个具体的应用(供货):
供货商 Supplier (sno, sname, scity, sstate)
产品 Part (pno, pname, psize, pcolor)
供应关系 Supply (sno, pno, qty, price)
IMS Era
IMS发布于1968年,使用的是hierarchical数据模型。
IMS感知record type,一个record type有多个字段名及其字段类型,并且有某个字段集合作为该record type的key。record type被组织成一棵树,每个record都有自己的唯一的parent record type。
用hierarchical数据模型来描述供货商应用的话,有如下两种方式。
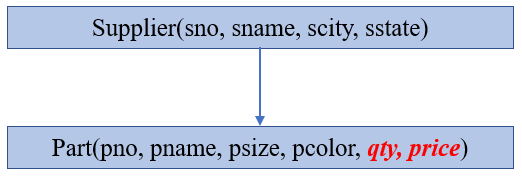
可以看到这两种方式都有问题:
问题1:信息被重复了,重复信息可能导致潜在的不一致性。例如左边的方式下,一个Part可能在多个Supplier下重复。
问题2:存在性依赖parent。例如,左侧方式下,如果某个Part暂时没有Supplier提供,那么数据模型里面就无法存放这个Part了。
IMS使用的是DL/1操作语言。每条record都有一个hierarchical sequence key(HSK),HSK是将从树的根节点到当前节点的key的拼装。在这种树型级联结构下,所有的record被定义了一个大小顺序(按照深度优先并从左到右遍历产生的顺序)。DL/1中有get next, get next within parent等操作接口。
例如,按照上文左侧图的模型,如果要获取sn=16的Supplier的所有红色Part,查询语句可以这样写:
|
1 2 3 4 |
Get Unique Supplier(sn0=16) Until Failure do Get next within parent(color=red) EndDo |
IMS支持了四种物理存储方式:
- Stored sequentially
- Indexed in a B-tree using the key of the record
- Hashed using the key of the record
- Physical sequentially(if not root record)
物理存储方式会影响DL/1的功能支持,纯sequentially的存储方式不支持随机insert,适合灌数据后做OLAP分析。hash存储方式不支持按顺序get next。
这里提到了两个independence :
physical data independence:指的是不管数据库采用什么物理存储方式和优化调优手段,数据库应用不应该感知到。
logical data independence:例如增加新的record type是否容易。
IMS上学到的一些经验:
Lesson 1: physical and logical data independence很重要。
Lesson 2: 树形数据模型很受限。
Lesson 3: 树形数据模型下,很难提供一个复杂的结构组织。
Lesson 4: IMS是一次一记录(record-at-a-time)的方式,这种方式要求使用者手动做优化,这往往都比较困难。
CODASYL Era
1969年CODASYL(Committee on Data System Languages)发布了CODASYL系统。CODASYL是采用network data model。每个record可以有多个parent。network data model包含named record type和named arc(CODASYL称之为set)。
CODASYL有一个限制是,只能有二元关系。如果一个应用需要三元关系,就要拆解成多个二元关系,例如一个婚礼包括新娘新郎神父三个参与者,这个三元关系就得拆解成婚礼-新娘,婚礼-新郎,婚礼-神父三个二元关系。
CODASYL也是record-at-a-time的数据操作语言。一个查询可以这样写:
|
1 2 3 4 5 6 7 |
Find Supplier(sno=16) Until no-more { Find next Supply record in Supplies Find owner Part record in Supplied_by Get current record Check for red color } |
跟IMS相比,CODASYL在迭代时,要记录最后一次访问的record、record type、set type。
相比IMS,CODASYL牺牲了复杂度,但能支持non-hierarchical的数据。
CODASYL中数据的局部性比IMS差,因此在物理存储上效率可能更低,同样的原因,故障恢复可能会更加复杂。CODASYL的load工具也无法有通用的优化策略,只能靠用户自己。
Lesson 5:network比hierarchical更灵活,但更复杂。
Lesson 6:在loading和recovering上,network比hirrarchical更复杂。
Relational Era
1970年Ted Codd提出了关系模型。Ted Codd提出关系模型的原因是当时IMS的程序员花了大量时间在处理logical or physical change。因此Codd尝试提供一个data independence更好的模型。
关系模型有三个方面的特征:
- 将数据存放到表中。
- 使用高级DML语言,每次取出一组记录set-at-a-time。
- 对物理存储方式不做假设。
简单的数据结构更容易实现更好的logical data independence,而使用高级语言更容易提供更好的physical data independence。关系模型非常灵活,IMS中遇到的existence dependency问题(一定要有parent)在关系模型里面很容易处理。
Codd后面有提出了多个更复杂的关系模型,最初的模型使用的是比较严谨正式的关系运算和关系代数(Codd是数学家)。
Codd的关系模型引起了大讨论。一边是Codd为代表的学术派,另一边是Charlie Bachman为代表的实践派。
Codd方认为:
- 像CODASYL这么复杂的玩意,一定不是好东西。
- CODASYL的数据独立性难以让人接受。
- Record-at-a-time的编程范式不好优化。
- CODASYL和IMS即使是在表达常见的场景下(例如上文所述婚礼场景)也不够灵活。
Bachman方认为:
- COBOL程序员在理解这种新式的关系语言的时候大概率要跪。
- 很难把关系模型实现的比较高效。
- CODASYL也能实现表达table呀,关系模型其实吧也没啥。
Codd和Bachman在1974年SIGMOD和同年RUST上大辩论了一番,原论文作者Stonebraker和Hellerstein作为吃瓜群众也在观战,两人表示辩论双方都没把自己的立场梳理清楚,因此双方根本也没听对方说了啥……
过了几年,两个阵营完善了自己的立场。
关系模型阵营说
- Codd是个数学家,他提的语言偏形式化,但SQL和QUEL这种就很容易让搬砖码农接受了吧。
- System R(1976)和INGRES(1976)都高效地实现了Codd的想法,并且查询优化器甚至能够跟最好的码农手工的查询计划相媲美。你看都有实用系统造出来了,还有什么好说的呢。
- 这些实用系统的physical data independence很好啊,关系模型在logical data indepence上也比CODASYL强。
- set-at-a-time语言比record-at-a-time让码农更有生产力。
CODASYL阵营说:
- set-at-a-time的语言我们也有,比如LSL,它能提供更完整的physical data independence和可能更好的logical data independence。
- 网络模型好好整整也可以很靠谱,没那么复杂。
后来微机时代来临,VAX小型机市场暴涨,其上安装的是Oracle和INGRES,另一边CODASYL被IBM用汇编重写了一遍之后可移植性太差,最后小型机市场中关系模型与VAX携手共赢了。但在大型机市场,IBM在VM370和VSE上的Sysmte R卖的不好,转而卖IMS,最终关系模型在这里基本消失匿迹。然而在当时,大型机才是数据库市场的主流。
1984年市场剧变,IBM推出了DB2与IMS并肩推销,最终DB2凭借新技术和易用性赢得了市场。IBM成了市场大佬,同时也给这场论战画了句号:关系模型胜出,SQL语言也成为了事实标准。
一个必须要提到的事情是当时IBM在IMS之上套一层关系接口是很自然的。这个架构下,新应用使用关系模型,旧的应用还可以使用久的IMS接口,优雅地将用户迁到了新技术上。IBM也尝试在IMS上实现SQL接口,但最终因模型问题失败,IMS复杂的逻辑数据模型使导致困难缠身,最终迫使IBM转向双产品推销策略。

旷日持久的大论战最终结束,总结起来,对结局影响最大的三件事情(市场、工程、技术因素都有):
一是 VAX小型机在市场上的胜利,
二是 CODASYL的移植性问题,
三是 IMS逻辑模型的复杂性。
关系模型这个时代带来的一些经验:
Lesson 7: set-at-a-time语言很好,提供了更好的physical data independence。
Lesson 8: 简单的数据模型的logical data independence更好。
Lesson 9: 技术论战往往被市场定论,通常跟技术优劣关系不大。
Lesson 10: 查询优化器能够和最好的record-at-a-time的程序员相媲美。
Entity-Relationship Era
70年代中期,Peter Chen提出了entity-relationship(E-R)模型。简单地说,数据库被视为一组实体的集合,一些对象对另外一些对象有依赖。实体有attribute,用于描述实体,实体之间有relationship。ER模型通常可以用方块和箭头示意图描述。
ER模型在数据库schema设计上非常有用,通常先构造一些实体,然后正规化。正规化包括第二范式、第三范式、BC范式、第四范式,Project-Join范式。但正规化是基于函数依赖来做的,函数依赖对很多DBA来说并不好理解。ER模型有一些设计工具逐渐流行开。
Lesson 11: 函数依赖对普通开发者来讲并不好理解。
R++ Era
Zaniolo提出在关系模型上再加上几个要素来扩展:
- set-valued attraibutes:属性是一个特定集合,可以定义新的数据类型,加到关系模型里面。
- aggregation(tuple-reference as a data type):foreign key如果用tuple reference可能会更好。
|
1 2 3 |
Select Supply.SR.sno From Supply Where Supply.PT.pcolor = “red” |
- generalization:

The Semantic Data Model Era
把现实语义引进来。
略。
OO Era
1980年代中期,兴起了一波面向对象数据库(OODB)的热潮,社区指出了关系模型和像C++这种OO编程语言之间的不匹配(数据库有自己的数据类型,应用要在C++和数据库之间来回转换数据)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Struct Part { Int number; Char* name; Char* bigness; Char* color; } Example_part; Define cursor P as Select * From Part Where pno = 16; Open P into Example_part Until no-more{ Fetch P (Example_part.number = pno, Example_name = pname Example_part.bigness = psize Example_part.color = pcolor) } |
考虑如果有一种持久化语言(persistent programming language),这种语言中的变量可以直接代表数据库磁盘或者内存中的数据,并且数据库查找方法也是使用这个语言的一些结构来完成。例如Rigel语言:
|
1 2 3 |
For P in Part where P.pno = 16{ Code_to_manipulate_part } |
这种语言比嵌入SQL的方式更清晰,但是编译器要感知DBMS的功能。考虑到各种不同语言和数据库系统,这必然带来不少问题。此外编程语言领域的专家一直就拒绝语言本身去关注IO,更不用说语言本身去关注具体的数据库系统了。最终这些70年代的学术研究最终也没有走入商业市场,而丑陋的嵌入式方式大行其道。80年代中期,C++日渐流行,持久化语言又死灰复燃,一批创业公司推出了一些持久化语言系统。这些系统尝试在C++基础上,将C++数据结构都视为可以持久化的对象,并将关系引入C++语言。OODB社区将市场定位成工程领域数据库,如CAD应用,因此对事务和查询的支持比较弱。工程领域数据库市场本来就不大,当时兴起的数据库厂商又很多,僧多肉少,最终这些厂商要么失败要么转方向了。
究其失败原因,有如下几条:
- OODB厂商提供的系统避免了用户写load/unload程序,但这个卖点上,客户并不愿意花大价钱。
- 缺乏标准,不兼容。
- 因为和数据库绑的太紧,细小的改动都要重新link整个应用。
- 编程语言不统一,如果你的系统有一部分不是C++,那就无法使用持久化语言。
另外,持久化编程语言因为将对磁盘数据的操作的逻辑都放在业务应用进程,因此几乎没有对数据的保护,这相比CODASYL是一个倒退。
Lesson 13: 不解决痛点的产品难以被市场接受。
Lesson 14: 没有语言专家支持,持久化语言毫无出路。
Object-Relational Era
OR模型是因为INGRES要处理地理信息而引入的。地理信息系统GIS有一些自己独特的查询特征。例如查询落在矩阵(X0,Y0,X1,Y1)的那些坐标点之类的查询需求,还有一个notify parcel owners问题,当California的一个区(假设是矩形)的划分有变化时,要通知到附近所有的业主(财产所占区域跟该区有交集的业主)。这些查询本质上是个二维的查询,而Btree实际是个一维的索引结构,而且这种查询的坐标比较表达式有点散乱,容易写花眼。
OR模型给SQL引擎增加了:user-defined data types/ operators/ functions/ access methods。有了这些自定义功能,用户可以自定义一些抽象类型如一个区域,并定义其上的操作(例如两个区域是否有交集)等。存储过程stored procedures也可以被视为某种形式的udf。存储过程能够显著减少一个交互事务业务访问数据库的次数。
OR模型踉踉跄跄几年最终还是获得了一些商业上的成功,找到了自己的市场定位,例如OR可以高效实现数据挖掘UDF,被用于支持XML处理。OR在市场上的一个障碍是缺乏标准,例如,各厂商都有自己的定义和调用UDF的方式,很多厂商支持Java UDF,但偏偏微软不支持。
Lesson 14:OR的主要益处是将代码放入数据库,支持user-defined access method。(原文多了一个Lesson 14)。
Lesson 15:新技术的广泛应用离不开标准化或者业界龙头力推。
Semi Structured Data
半结构化数据有两个基本点:schema last和complex network-oriented data model。
Schema Last
之前描述的数据模型都要求预先定义schema,而在半结构化数据模型下,不需要预先定义,所以数据一般需要自描述。举几个自描述的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Person: Name: Joe Jones Wages: 14.75 Employer: My_accounting Hobbies: skiing, bicycling Works for: ref (Fred Smith) Favorite joke: Why did the chicken cross the road? To get to the other side Office number: 247 Major skill: accountant End Person Person: Name: Smith, Vanessa Wages: 2000 Favorite coffee: Arabian Passtimes: sewing, swimming Works_for: Between jobs Favorite restaurant: Panera Number of children: 3 End Person: |
不同记录可以有不同的属性,不同字段的同名属性的实际含义也可以不一样。这叫semantic hetergeneity。
XML Data Model
XMLSchema和XQuery是目前XML-base data的标准。
Lession 16:schema-last是个小众市场。
Lession 17:XQuery与OR SQL差不多,只是语法上有些不一样。
Lession 18:XML并不能解决semantic heterogeneity。
Full Circle
数据模型发展也是兜兜转转,一直都有讨论争辩。为了避免历史重演,就要站在前人肩膀上思考。
后20年提出的这些数据模型,其实大都是更早的一些模型的重复发明,真正新的想法,大约只有这两条:
- Code in the database(from the OR Camp)
- Schema last(from the semi-structured data camp)