浅谈数据库隔离级别
本文介绍了关系型数据库的隔离性。ANSI标准里面定义了Read Committed, Repeatable Read, Serializable隔离级别,Jim Gray等针对ANSI的标准提出了改进,并介绍了Cursor Stability, Snapshot Isolation等隔离级别。
关系型数据库具备事务ACID的特性:原子性、一致性、隔离性、持久性。
原子性是说,事务的操作要么都完成,要么都不完成。一致性是说事务不能破坏数据库的一些约束。隔离性是说,并发事务执行时,如何看到其他事务的执行结果。持久性是说,宕机重启后,数据库状态还能恢复。
在分布式数据库中,原子性通常可以用两阶段提交(2PC)等协议保证。持久性靠持久化的日志文件。一致性和隔离性两个关系比较密切,本文基于经典论文A Critiqueof ANSI SQL Isolation Levels(后简称Critique论文),浅谈隔离级别。
这篇论文的陈述思路是:标准委员会搞了一套标准来定义隔离级别,然而本文作者Jim Gray等大牛表示这个标准有点问题,于是写了这么一篇论文。说标准阐述语义有点窄,还有就是没能涵盖一些彼时比较新的数据库技术,例如Snapshot隔离级别等。
首先是一些名词的定义。
history : 若干并发事务的某个执行序列。
Serializable 的定义:严格定义比较繁琐。如果事务T1的操作op1和事务T2的操作op2作用于同一数据,且至少一个写操作,那么称两个操作冲突。对于并发执行的事务,以操作为点、冲突为边,构造的图称之为依赖图。两个history的依赖图如果具有相同的依赖图和相同的提交事务,那么两个history就是等价的。如果history跟某个串行执行的history等价,那么就称该history是serializable的。
隔离级别的定义
隔离级别定义方式比较混乱。现在回头看的话,大致可以按照如下思路理解:早期基于锁定义的隔离级别;而ANSI SQL标准尝试从实现无关的角度定义了隔离级别;而Critique这篇论文又对标准定义的隔离级别提出了一些改进,而MVCC等数据库技术出现之后,又需要重新补充一些分析和定义。如图示。

本文择其要者,简述一下。
基于锁的定义
锁可以分为读锁、写锁;或者长锁、短锁;或者数据项锁、谓词锁。
其中,长锁指加锁后直到事务结束才释放锁。
谓词锁指对一个谓词逻辑加锁,例如,lock on (age < 10) 这一谓词锁,可以阻止对满足该谓词的元组的修改和增删。
根据不同的加锁策略,可以支持不同的隔离级别。
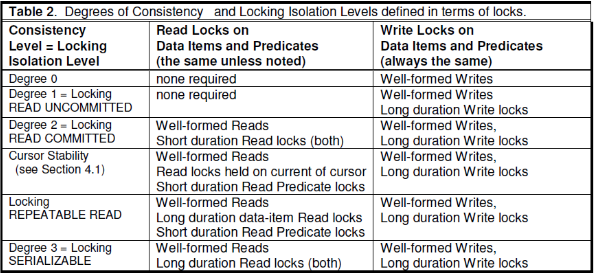
该表比较简单,不再赘述。
另外,两阶段封锁(2 Phase Lock)可以保证serializable。其中2PL指事务加锁和解锁分为两个明显的界限,在前一阶段只加锁,后一阶段只释放锁。至于2PL为何能够保证serializable,读者可以参考教科书。
原始ANSI标准和Critique论文完善的隔离级别定义
ANSI标准尝试定义一个实现无关的隔离级别。ANSI标准是基于表现出来的异常现象(phenomena)来定义隔离级别。这个想法很好,但是后来发现漏洞也有。其一是这种定义是通过自然语言描述,不够严谨;其二是后续有多了MVCC等技术,隔离级别的定义也需要相应改动。
这里,我们直接从完善后的隔离级别定义说起。
首先定义几种异常现象:P0, P1, P2, P3, P4, P4C, A5A, A5B。
P0 Dirty Write
P0的访问模式是:w1[x], w2[x], c1 or a1。
这个访问模式指的是事务T1写了x,然后事务T2写了x,然后T1提交或者回滚。
如果数据库允许P0这种情况发生,可能违反一致性约束。不过这也不算大问题,更为严重的问题是很难在允许这种异常的情况下,通过restore before-image来undoupdate,恢复机制不好搞了。例如:
x=0, w1[x=1], w2[x=2], a1
这个history下,如果通过restore before-image来undo update,可能带来如下问题:
T2记录undo日志的话,要记下(T2改x之前,x=1),但是如果T1回滚,则undo日志就不对了。
基于这个考虑,数据库都不允许P0发生。
P1 Dirty Read
P1的访问模式是w1[x], r2[x], c1 or a1
允许P1发生的话,事务可能读到不一致的数据状态。
例如:
C(x,y): x+y = 100
History: [x=50,y=50], r1[x=50], w1[x=10], r2[x=10], r2[y=50], c2, r1[y=50], w1[y=90], c1。
T2读到了x=10, y=50的不一致的状态。
P1异常被用于区别Read Uncommitted和Read Committed隔离级别。
P2 Non-Repeatable Read
P2的访问模式是 r1[x], w2[x], c1 or a1
P2异常是,T2提交前后T1可能读取到数据可能不一致或者违反约束。
数据不一致History: r1[x=50], w2[x=10], c2 ,r1[x=10], c1
违反约束C(x,y): x+y=100
History: r1[x=50], r2[x=50], w2[x=10], r2[y=50], w2[y=90], c2, r1[y=90], c1
P2可以用于区别Read Committed和Repeatable Read。
P3 Phantom
P3的访问模式是r1[P], w2[y in P], c1 or a1
P3异常是,谓词对应的数据集合在T1读取后被T2修改。
P3用于区别Repeatable Read和Serializable。
P1 ~ P3是Critique paper基于ANSI标准定义的异常情况A1~A3,重新表述而来。P和A对应的差别是,P是更加宽泛的解释,也就是说,P异常描述了更多的history,至于为何将A重新表述为P,主要原因是,A描述下,某些违反约束的history不会被视为异常。
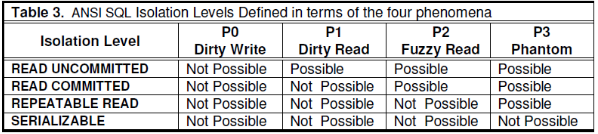
Table3锁定义的隔离级别与T2锁定义的隔离级别,同名隔离级别是等价的。这个结论是通过论述加锁策略排除异常的方式得来的。
后续针对新出现的技术如Snapshot Isolation等,需要扩展上述隔离级别的定义。
P4 Lost Update
P4的访问模式r1[x], w2[x], w1[x], c1
P4的问题是T2的可能会丢失。
P4C Lost Update
P4C是P4类似的一个访问模式,rc1[x], w2[x], w1[x], c1
其中rc1[x]指通过Cursor来访问x。
Cursor Stability隔离级别是在Read Committed的基础上排除了P4C。大致原理是锁定游标锁引用的行,这个实际是比较弱的限制,只是锁定了一行(假设一个游标)。
P4是针对Snapshot Isolation出现的。Snapshot Isolation是一种多版本并发控制方式。大致原理为:每个事务读写各自的快照;快照是Start-Timestamp(某个早于该事务开始的时间)时的已提交状态;写不阻塞读;写事务更新自己的快照,更新可被本事务读取,但不影响其他事务的快照。提交时按照First-Committer-Wins原则提交。First-Committer-Wins是指如果在本事务的执行时间区间 [StartTimestamp, CommitTimeStamp]内,没有更新了同样数据的其他并发事务提交,那么本事务才能提交。这个提交原则保证了Snapshot Isolation不会违背P4。
在MVCC机制下,分析异常情况的方式也有差异。MVCC下,通常会考虑约束违反(Constraint Violation)这类异常情况,分析不一致性(inconsistent analysis)。
A5A Read Skew
r1[x], w2[x], w2[y], c2, r1[y], c1 or a1
A5B Write Skew
r1[x], r2[y], w1[y], w2[x], c1 and c2
A5A是P2的特例。A5A带来的问题是,可能违反约束(见P2)。
由Snapshot Isolation的特性容易知道,Snapshot Isolation可以拒绝A5A。
A5B的情况复杂一些。我们举个例子,假如允许同一个人的两个银行账户x,y出现负值,只要保证C(x,y) : (x+y>=0)为TURE即可。(下例中,每个事务单独保证C(x,y),但history不能保证)
History: r1[x=50], r1[y=50], r2[x=50], r2[y=50], w1[x=-40], w2[y=-40], c2, c1
A5B可能发生在Snapshot Isolation隔离级别下。
Oracle Read Consistency
Oracle使用多版本的大致机制如图:
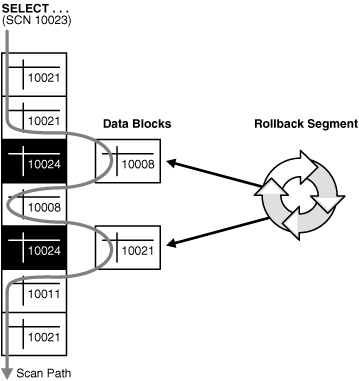
当前事务拿到的快照为SCN=10023,假如该事务扫表,对于第三行,会读取10008那个版本的数据。
Oracle Read Consistency 每条语句执行前重新计算最新快照。因此可以读到语句开始前最新提交的数据。这种机制允许P2。Oracle的提交遵循First-Write-Win,也就是谁先写谁为准,后续要写的事务只能abort。
用户也可以手动设置,使得每个事务执行前计算快照。这两种拿快照的方式分别对应Statement-Level Read Consistency 和 Transaction-Level Read Consistency。
当然,论文里提到的这个Oracle Read Consistency基本等价于Oracle提到的Read Committed隔离级别。Oracle也可以设置为Serializable的隔离级别(非真正的serializable)。
总结
综合上述论述,得到的结论可以归纳为一张表和一张图。
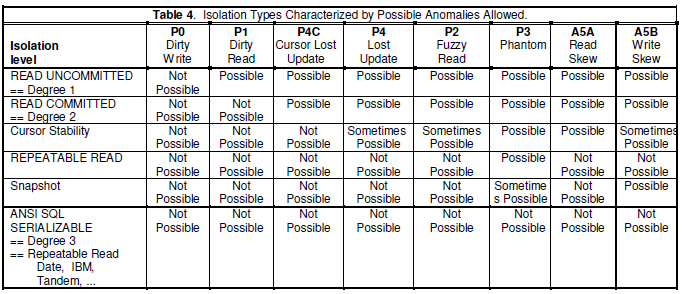
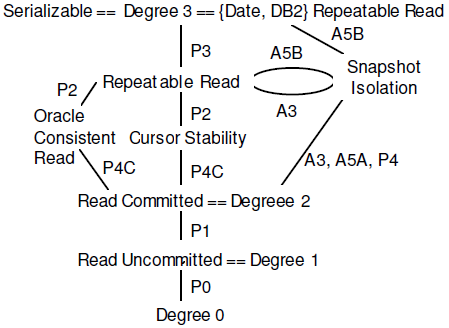
从图中可以看到各厂家宣称的隔离级别名字其实挺混乱的。DB2的Repeatable Read其实就是Serializable,而Oracle的Serializable却不是图上的Serializable,相反地,Oracle的最高隔离级别也不能排除A5B。据说,PostgreSQL在Snapshot Isolation基础上支持Serializable,也有相关的论文介绍相关的技术(SSI)。
1 条留言 访客:0 条 博主:0 条 引用: 1 条
来自外部的引用: 1 条