数据库系统组件
读了Architecture of a Database System这篇经典论文,挑了些不太熟悉的内容做了笔记。
论文内容基本上谈不上是在讲架构吧,基本上就是罗列了下有哪些组件,而且内容基本上针对原来传统数据库的。
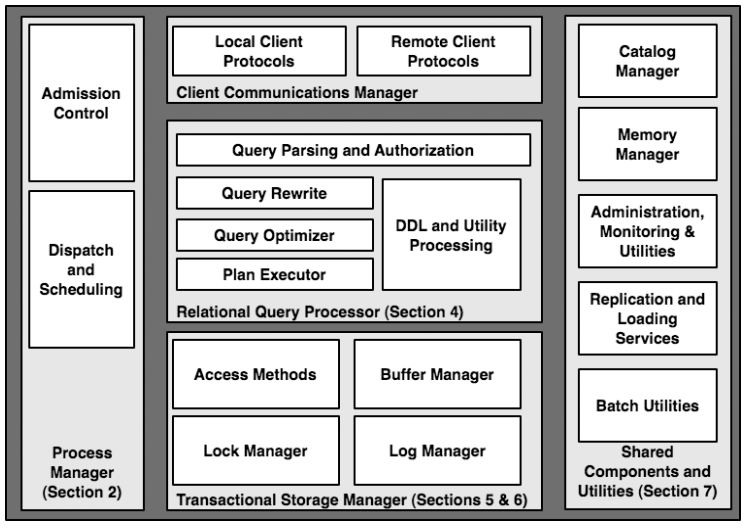
主要包括几个组件:
Client Communication Manager
Process Manager
Relational Query Processor
Transaction Storage Manager
Shared Components and Utilities
Client Session Manager
- 两层:Client – Database
- 三层:Client – WebServer – Database
- 四层:Client – WebServer – ApplicationServer – Database
Process Model
- Process per DB worker: DB2, Oracle, PostgreSQL
- Thread(OS/DBMS thread) per DB worker: DB2, MySQL, SQL Server
- Process Pool: Oracle, SQL Server
Parallel Architure: Processes and Memory Coordination
- Shared Memory: DB2, Oracle, SQL Server
- Shared Nothing: DB2, Informix, Tandem, NCR Teradata, Greenplum
- Shared Disk: Oracle RAC, RDB, DB2 for zSeries
- NUMA(No-Uniform Memory Access): almost disappeared
Relational Query Processor
Query Parsing and Authorization
Parser的主要工作:
- 检查query是否正确
- 解析名字和参照
- 将query转为optimizer使用的内部数据结构
- 验证用户权限(或者生成验证权限所需信息,推迟到执行阶段再验证)
给定SQL Query之后,先解析FROM语句中的表名,通常要规范成server.database.schema.table(前缀按需),此外要处理table alias。之后调用catalog manager来检查表在system catalog注册过,通过catalog中的信息来判断query中的参照是否合法。同时,获取列类型之后,还可以做类型推断,解决表达式计算过程种可能的重载函数决议。
Query parse之后,接下来是权限验证,判断用户是否有合适的权限:对表的增删改查、user defined function使用权限、参照对象的权限。有些权限检查可以在parse阶段做,比如讲salary列设置为-1,这种constraint-check就可以在parser阶段完成。不过有些权限检查是更低级别的检查,例如检查依赖具体的一行数据的值,因此要推迟到执行阶段才能做这类检查。
Query Rewrite
Query parse并检查通过之后,进入rewriter模块。Rewriter接收一个parser的输出,并输出同样类型的内部结构。Rewriter可以作为一个独立的组件或者作为optimizer的第一步。
Rewriter的主要工作:
- view expansion: 将视图展开。从catalog提取view的定义,将view替换为对应的查询,替换指向该view的参照。如果视图里面还有视图,可递归处理。
- 常量算数计算:例如R.x < 10 + 2 + R.y重写为R.x < 12 + R.y。
- 谓词重写: 针对WHERE子句中的谓词和常量进行重写。例如:
- NOT c1 > 1000 => c1 <= 1000
- c1 < 75 AND c1 > 100 => false
- 水平分区的数据,可以按照分区规则尝试分区剪枝
- 传递规则: R.x < 10 AND R.x = S.y 蕴含着 S.y < 10
- 语法优化
- 冗余join消除: 例如 SELECT Emp.name, Emp.salary FROM Emp, Dept WHERE Emp.deptno = Dep.dno可以消除Dep表。
- 子查询展开和其他启发式重写:大部分optimizer是针对单个SELECT-FROM-WHERE查询块,因此rewriter有时候需要将嵌套查询转为单个查询块(该过程称为query normalization)。
Query Optimizer
查询优化器负责将查询的内部表示(rewriter的输出结果)转为一个高效的执行计划。查询计划可以被视为一个数据流图,表的数据通过数据流图执行处理。
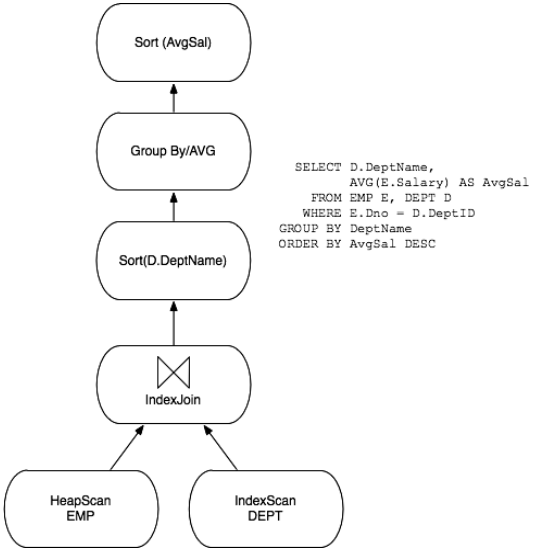
优化器首先使用一些既有的技术处理SELECT-FROM-WHERE查询块,完成后再增加算子处理GroupBy、OrderBy、Having、Distinct。
执行计划有多种表示方式。一早的时候,System R是将执行计划直接编译成机器码(后来商用时换成了可解释的形式)。Ingres会生成可解释的查询计划结果。目前商用数据库产品基本都是用某种中间格式表示执行计划,但是具体使用的抽象层次不一样。
除了Selinger那篇关于优化器的经典论文之外,很多系统进行了多种扩展:
- Plan space:
- Selectivity estimation:
- Search Alogrithms:
- Parallelism:
- Auto-Tuning:
A Note on Query Compilation and Recompilation
Query Executor
两种执行方式,一种是将执行计划编译成低级的操作码再执行,一种是执行器收到的是数据流图(dataflow graph),递归调用operator的过程。这里关注第二种方式。
大部分执行器都采用了iterator模型。
|
1 2 3 4 5 6 7 |
class iterator { iterator &inputs[]; void init(); tuple get_next(); void close(); } |
一个迭代器的inputs是数据流图中的某条边,所有的operator(数据流图中的节点)都是迭代器对象。这些迭代器对象可以是filescan、indxscan、sort、nested-loops join、merge-join、hash-join、duplicate-elimination、group-aggregation。一个迭代器对象可以是另外一个迭代器对象的输入,每个迭代器对象都是独立的。
迭代器模型的一个重要特点是将数据流和控制流耦合起来了。get_next()执行结束后,就有一行结果返回。这个模型非常适合单线程执行,但如果要支持并行执行,这个模型也不需要大改,并发执行和涉及网络的部分可以封装成exchange iterator。
迭代器模型下的执行期数据存储:tuple descriptor(schema信息)是迭代器对象预先分配好的,该迭代器对象的多个输入流和一个输出流都各自有一个tuple描述。实际数据存放在buffer pool,可以使用引用计数或者直接copy出来的方式获取该tuple。
更新语句与只读查询语句类似,只是在流水线最后多了一个更新的operator。
Access Method
Access Method是指访问磁盘数据结构的routine,通常包括堆文件和索引。
主流的商业数据库都实现了B+tree索引,有些还实现了R-tree索引等。PostreSQL还支持可扩展的索引Generalized Search Tree(GiST),并实现R-tree来索引多维数据,RD-tree来索引文本数据。IBM UDB V8系统引入了Multi-Dimensional Clustered(MDC) Index来支持多维数据上的范围查询。有些几乎只读的数据仓库会使用bitmap等索引方式。注:2017年最新的研究已经开始使用机器学习来做索引了(learned index)。
Access method的最基本的api即迭代器的API。init()接口用于接受查询参数(查询条件,search argument, SARG),get_next()用于返回满足条件的行或者没有满足条件时返回NULL。SARG之所以会被下压到access method层,一是B+tree等需要查询条件来查询,二是条件下压有助于避免不必要的数据往上吐。
所有的数据库都需要某种方法指明表中的一行。一种直接的想法是直接使用row ID(RID),RID代表该行在磁盘上的位置。这种方法直接,方便读取,但不适合数据移动(比如行size变大或者B+tree分裂),比如二级索引通过RID来指向表中该行,当表中这一行移动时,要修改指向这行的二级索引行成本很高。另外一种方法是二级索引中不记录RID,而是记录主键值,通过索引查到主键值然后回表查原始行,这种方法牺牲了查询性能,但避免了行移动带来的问题。
Data Warehouse相关的几个问题
数据仓库通常用于决策分析,数据通常经过ETL(extract, transform, load)处理,然后几乎全是只读查询。
Bitmap索引
B+tree是针对插入删除优化的索引方式。数据仓库因为是只读查询,对于类似性别等列的值,可以用位图存放(行数固定,每行对应一个bit),可以极大节省空间。另外,位图有时候也可以加快条件and的判断,例如sex=‘F’ && state=‘California'之类的查询可以直接使用bit的与操作判断。位操作有大量的技巧可供使用。
Fast Load
以前业务是晚间无修改,管理员可以趁晚上进行数据重新ETL。但现在很多业务要24小时在线,更新过程如果加写锁,可能影响读查询。MVCC(multi-version concurrent control)可以提供历史快照,减少写对读的影响。
Materialized View
数据仓库中有一些跨表的join查询,有时候会存为视图,为了加速查询,有些系统会提供物化视图,将视图作为一个真正的物理表存放,这样查询时可以直接查询物化视图从而避免join。
物化视图如何维护freshness: 可以实时更新,也可以周期性地重建。
OLAP和Ad-hoc Query Support
Optimization of Snowflake Schema Queries
Storage Management
DBMS有两种方式访问存储:直接与块设备交互或者通过OS文件系统交互,具体哪种方式会影响数据库对存储的空间和时间两方面的控制能力。
Spatial Control
直接控制落盘会比通过OS更好,因为数据库更知道自己的workload的情况。不过目前业界发展趋势是容器化,数据库的容器化这个方向貌似还是有争议。
Temporal Control
主要就是Buffer。
Transactions: Concurrency Control and Recovery
事务主要包括四块:
- lock manager for CC
- log manager for recovery
- buffer pool for staging database IOs
- access methods for organizing data on disk
ACID
事务的四大特性,Atomicity, Consistency, Isolation, Durability。教科书上讲的比较清楚了。
Locking and Latching
Lock更像是数据库概念下的锁,例如行锁,表锁。
Latch更像是数据结构层面的锁,类似于信号量。
Isolation Level
可以参考Jim Gray的经典论文。
Log Manager
就是ARIES这套理论(wal, redo, undo)。
Shared Components
Catalog Manager
存放user, schema, table等元数据。
Memory Allocator
数据库一般自己管理内存,尤其是涉及到云数据库的租户内存,内存超卖等问题。
Replication Service
目前高可用的数据库一般把replication内置到存储引擎的log manager模块中,通常用Paxos多副本方式保持高可用(可用性要求不高的话可以用主备模式)。