Intel CPU自上而下的微架构性能分析方法
原文:https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/top-down-microarchitecture-analysis-method.html
现代CPU一般都采用了流水线、硬件线程、乱序执行、指令级并行等技术来高效利用CPU内的各种资源。但有很多软件和算法在实现上并不能很好地利用好CPU,比如非常常见的链表会带来间接地址访问,影响硬件预取的效果,导致读数据的时候流水线冒泡(停顿)。
本文描述的自上而下的微架构性能分析方法可以用来识别这类问题。
现代CPU的流水线实际上相当复杂。简单地说,流水线从概念上分为前端Front-End和后端Back-End。前端负责取指和译码(将指令翻译成微操作uOps),uOps被灌到后端(这个过程被称作allocation)。后端负责监控uOps的数据是否可用,如果可用就在可用的执行单元上执行这个uOps。uOps完成时会把结果写回CPU寄存器或者内存,这个过程被称作retirement。通常大部分指令都会走完整个流水线然后retire掉,但是有些推测执行的uOps在分支预测失败的时候会直接中途cancel。
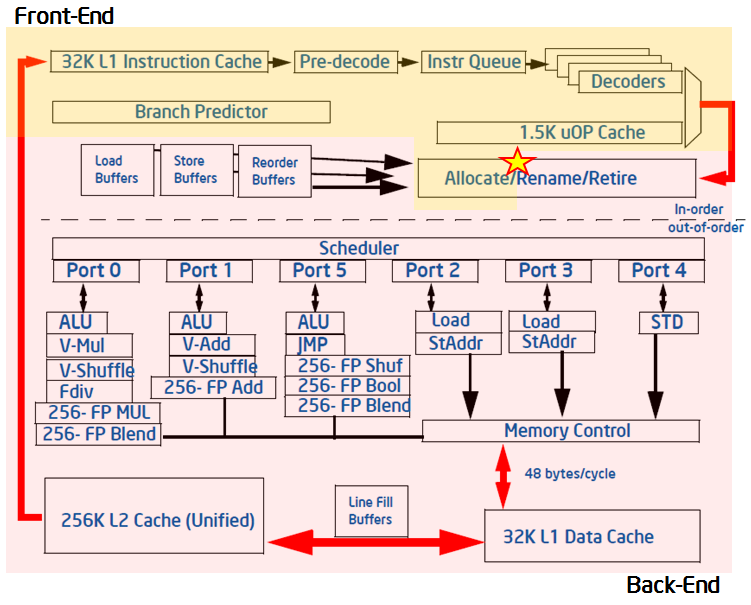 较新的Intel微架构流水线前端每个节拍可以allocate 4个uOps,后端可以retire 4个uOps。Pipeline slot代表能够处理一个uOps的硬件资源。Top-Down分析方法假设每个CPU Core在每个节拍都有4个slot可用,Core内有PMU监测slot的使用情况,监测发生在allocation point,即图中星号位置。
较新的Intel微架构流水线前端每个节拍可以allocate 4个uOps,后端可以retire 4个uOps。Pipeline slot代表能够处理一个uOps的硬件资源。Top-Down分析方法假设每个CPU Core在每个节拍都有4个slot可用,Core内有PMU监测slot的使用情况,监测发生在allocation point,即图中星号位置。
如果一个节拍内slot是空的(发生了stall),则需要判断是前端没供给得上还是后端没来得及消费。如果时前端没给slot供给得上uOps,即是Front-End Bound;如果前端供给没问题,但没法将uOps递交到后端,即是Back-End Bound,这通常是因为后端资源不足导致的;如果前端和后端都有问题,这种情况归结到Back-End Bound,因为前端问题解决了还是会卡到后端。
如果流水线没有stall,确定瓶颈就需要看uOps是否最终retire了。如果确实reitre了,情况归结为Retiring,否则可能是分支预测失败或者self-modify-code的原因导致流水线被清空(flush),这种情况归结为Bad Speculation。
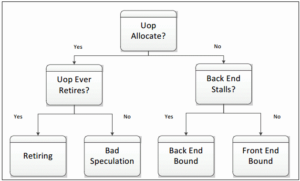
之所以监控在allocation point (图中星号位置) ,是因为front-end和back-end之间是生产者消费者模型,allocation point是连接二者的地方,容易判断是两侧的哪一侧的问题。
Intel VTune可以用于分析识别瓶颈类型。
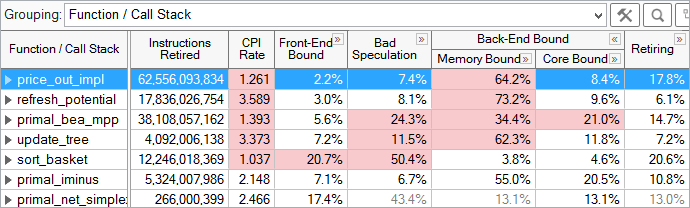
如图可以看到每个函数的瓶颈归类,数越大表示瓶颈越显著,其中红色表示需要关注的点。
微架构调优方法论
- 首先关注热点函数
- 使用前述Top-Down方法评估该函数执行是否高效
- 如果函数执行不高效,则根据瓶颈类型识别问题所在
- 优化该问题
- 针对各个热点函数,重复上述1-4,
Back-End瓶颈优化
Back-End瓶颈属于比较常见的一类,可以继续细分为memory bound和core bound,细分依据是执行单元的利用率。详细的指标可以参考 https://www.intel.com/content/www/us/en/develop/documentation/vtune-help/top/reference/cpu-metrics-reference.html
Memory bound的情况有比如cache miss、memory access。core bound的情况有比如除法指令要占用多个节拍,如果有多个除法指令就会争夺同一个除法部件。

针对memory bound的情况,Intel VTune工具可以进一步显示是哪个层次的存储瓶颈,包括从L1 cache到内存设备的各层。针对core bound的情况,Intel VTune可以显示Divider和Port Utilization两列情况,其中Divider指除法部件利用率,Port Utilization可以进一步展开看到各个port的利用率。
Front-End瓶颈优化
Front-End瓶颈可能来自 JIT代码和解释性代码,这类代码需要临时动态生成;带有分支跳转的代码和指令数比较多的代码也可能引起这类瓶颈。这类瓶颈一般可以通过优化代码段大小,编译器PGO等来优化。
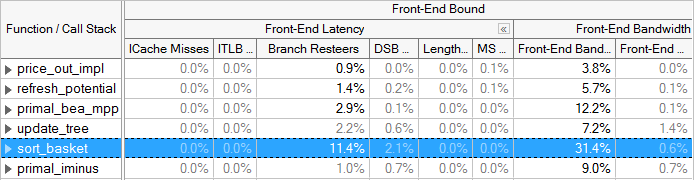
Intel VTune里面展示了Front-End Bound的两个方面:Front-End Latency和Front-End Bandwidth,前者反应多少节拍内没有uOps供应,后者反应有多少节拍内uOps没灌满4个。
Bad Speculation类型优化
这类问题指流水线干了一些没有用的活,这些指令最终都不能retire因而导致流水线白跑了,另外就是需要重新加载有用的指令也要耗时。
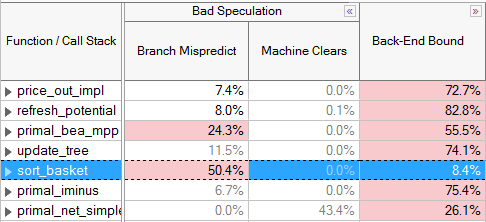
这类问题主要就是分支预测失败导致。一般可以通过PGO来提高分支预测成功率,减少间接跳转分支等。
Retiring类型优化
一般retire高表示有用的指令都在提交,这是个好事。但是这不代表没有优化空间了。
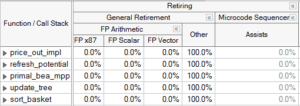
举个例子,CPU在执行一些很小的浮点数计算的时候,不能直接用浮点部件计算,需要执行一段特殊的uOps代码,这个过程称为FP Assists。FP Assist会显得前端供应很充足,但对于计算来讲效率其实比较低,属于是“低价走量”的情况。这种可以通过编译时制定DAZ/FTZ来优化。