NoSQL数据库综述和选型 阅读笔记
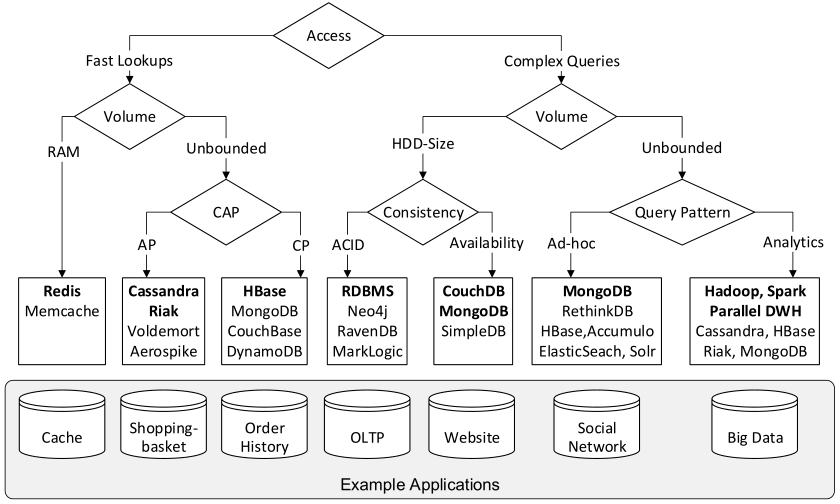
前一阵子看到的一篇比较详细的NoSQL数据库的综述 NoSQL Database Systems: A Survey and Decision Guidance,归类梳理了NoSQL数据库,并提供了选型决策树,非常有价值。
前一阵子看到的一篇比较详细的NoSQL数据库的综述 NoSQL Database Systems: A Survey and Decision Guidance,归类梳理了NoSQL数据库,并提供了选型决策树,非常有价值。仔细阅读了下,发现好多NoSQL系统连名字都没听过,汗。文中图片点击可看大图。
Introduction
传统关系型数据库(RDBMS)提供了很强大的机制来存储和查询结构化的数据。RDBMS支持强一致和事务,可靠性、稳定性非常高。然而最近几年产生了大量的数据缺额无法用传统关系型数据库存储和处理,比如社交网络上产生的用户数据、传感器网络产生的数据。这些数据被称为Big Data。适用于Big Data的NoSQL数据库顺势出现,它们通常都有很好的水平扩展能力和更高的可用性,但同时牺牲的是丰富的查询能力和一致性保证。
High-level System Classification
NoSQL类型各异,这里采用两种分类方式:根据数据模型、根据CAP折中策略。
根据数据模型分类
Key-Value Stores:key-value存储存放的是key-value对的集合,只支持get和set接口。存放的value值对于key-value存储来说是透明的,key-value存储因此被认为是schemaless的。
这种数据模型的优点是简单,数据分区和查询都很容易,也容易做到低延迟和高吞吐。但是这种数据库不支持复杂查询(例如范围查询),数据的分析需要在应用端做。
Document Stores:文档存储是一个key-value存储,但是限制value是半结构化的数据(如JSON文档)。相比key-value存储,文档存储更加灵活,不仅支持根据key取出一个完整的文档,还支持文档的部分字段的查询,聚集查询和全文索引都支持。
Wide-Column Stores:宽列存储,以Bigtable为代表,模型为一个关系型的表,表中有很多稀疏的列。宽列存储更接近分布式的multi-level sorted map:第一级key是row keys,第二级key是column keys。宽列存储的设计支持任意多列,若干列可以合成一个column family。存取时,通常不能一次取出一整行,但是往往能够高效压缩和存取一行的一部分列。所有行是有序存放的(即sorted map),物理磁盘上也是放在一块,高效支持row range scan。数据按照range分区,每个分区称之为tablet,若干tablets分散在不同机器上。
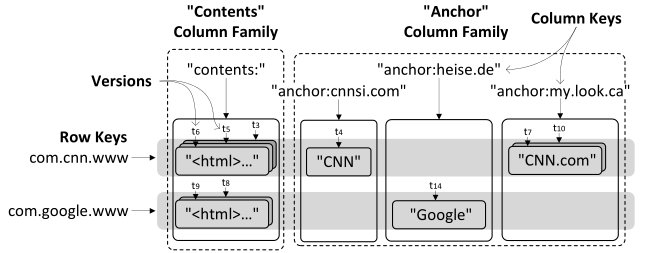
根据Consistency-Availability折中方式分
CAP理论的相关内容可以参见这里。粗略地说,NoSQL数据库要在CAP中三选二,即要么是AP,要么是CP,要么是CA。CAP本身强调的是在面临分区时如何抉择,但是没有描述正常情况下的CA折中。所以Daniel Abadi引入了PACELC。
PACELC:在Partition发生时,在Availability-Consistency之间折中,否则Else在正常场景下在Latency-Consistency之间折中。
不过NoSQL数据库并不是比较容易就归到某个折中下。
Techniques
主要从四个方面Sharding、Replication、Storage Management、Query Processing来分析design space(design space这个名词真形象~)。如图。
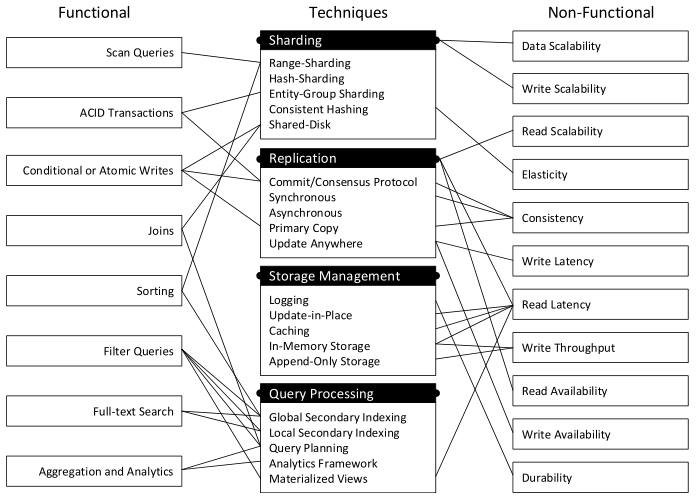
我们逐个看下。
Sharding
传统数据库的分布式方案通常是shared-disk architecture,多个节点连到同一份存储上。NoSQL通常是shared-nothing architecture。
分布方式主要有三种:range sharding、hash sharding、entity-group sharding。
range sharding能够方便地支持scan操作,但是需要一个协调者的角色来管理range到节点的分配,同时还要自动检测热点range并拆分。宽表Bigtable、HBase、Hypertable、文档数据库MongoDB、RethinkDB、Espresso、DocumentDB等都属于这类sharding。
hash sharding针对每个对象,通过对象的主键hash值模除节点数目来确定哪个节点服务该对象。该方式缺点明显,不容易支持scan操作。key-value数据库Cassandra、Azure Tables属于这类sharding。另外的缺点就是当增删节点时,数据需要重新分配位置。consistent hash减缓了这种弊端(关于consistent hash,可以参见这里)。
Entity-group sharding这种方式的主要目的是支持单分区内事务。应用指明或者数据库根据schema推断,来将不同表的部分数据作为一个实体组,例如按照user_id划分的多张表,实体组内数据更新可以原子地持久化,不需要2PC提交来解决分布式事务。G-Store、MegaStore、Relational Cloud、Cloud SQL Server等都是这类。
Repliacation
主要从两个角度看:when,修改什么时候传播到副本;where:修改如何被接受。
从when的角度分成两类:eager(synchronous)将修改到所有副本之后才返回客户端修改成功;lazy(asynchronous)不等修改传播到副本就返回客户端成功,异步地传播修改。
eager方式强一致,但高延迟。lazy方式延迟低,因为允许副本数据分叉(不一致,旧数据可能被读到)。
从where角度分成两类:master-slave(primary copy)只允许master上接受修改;update-anywhere(multi-master)任何副本都可以接受修改。
anywhere方式要求有额外的机制来检测冲突的修改。例如,versioning, vector clock, gossiping和read repair等。
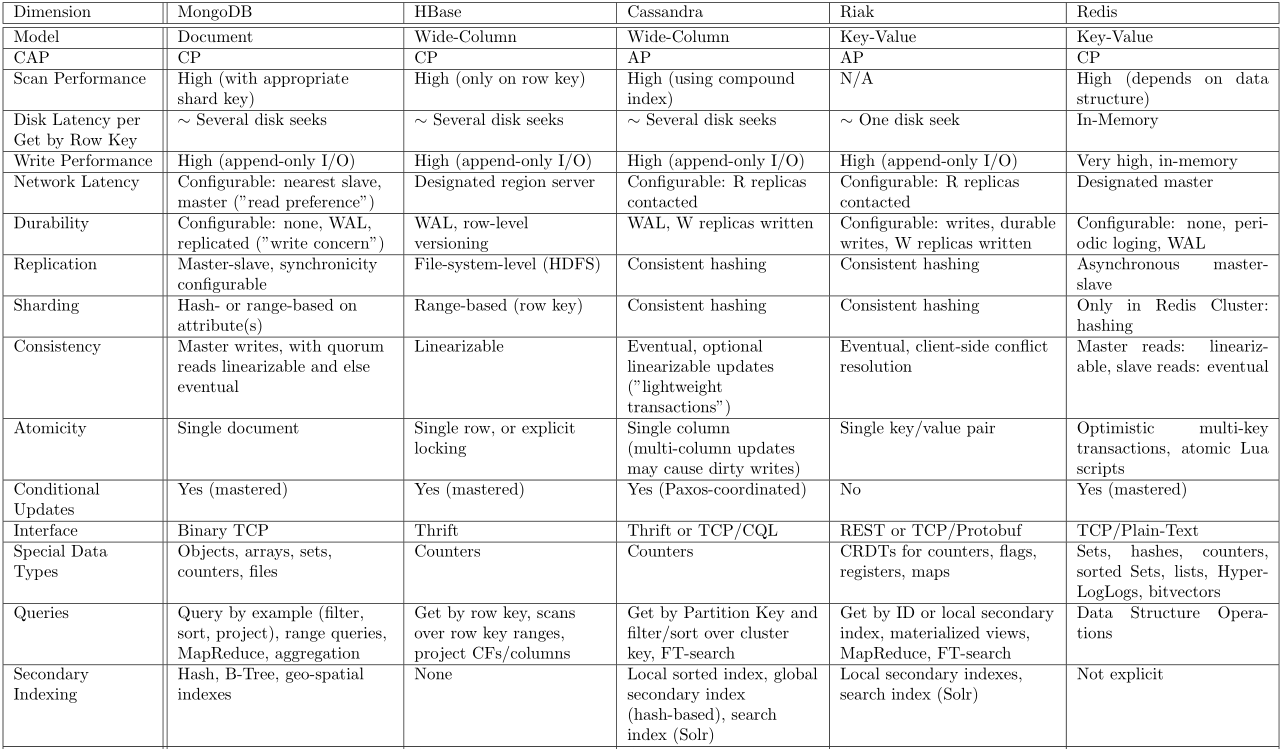
两种分法下的四种组合都是可能的。eager anywhere如分布式关系型数据库megastore;lazy master-slave如HBase、MongoDB;lazy anywhere如Dynamo、Cassandra。还有些数NoSQL数据库把latency-consistency的决定权丢给了客户端。
when-where分法并不全面,比如replica之间的距离等因素无法划归到里面去。Geo-replication在系统规模达到跨地域时也是一个不可忽视的要素。Eager geo-replication如Megastore、Spanner(placement)、MDCC(不了解…)、Mencius(replica轮流做leader)。lazy geo-replciation如Dynamo、Cassandra、Bigtable、PNUTS、Walter、COPS(后面两个个不了解…)。
Storage Management
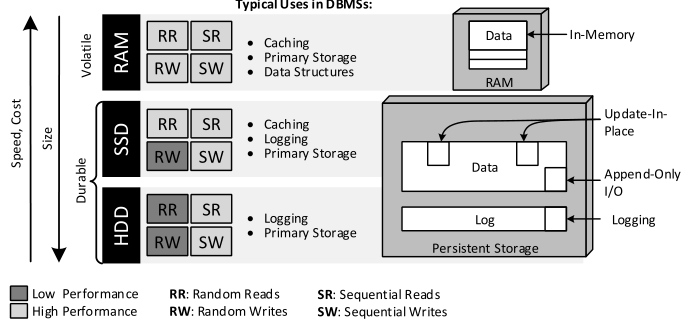
一种提高存储系统性能的方式是构建内存数据库In-memory Database,代价是内存的高成本和抵抗宕机(例如loggging)。内存状态就地修改,logging能够将随机写转化为顺序写。
有些NoSQL数据库持久化的存储也使用就地修改的方式,这会导致比较多的随机写,一种减缓这种随机写的方式是使用LSM树(Log-Structured Merge Tree),Bigtable为其代表。LSM Tree及其变体Sorted Array Merge Tree(SAMT)和Cache-Oblivious Look-ahead Array(COLA)在NoSQL领域应用广泛,如Cassandra、CouchDB、LevelDB、RethinkDB、RockdDB、InfluxDB、TokuDB等。值得注意的是,通过loggging方式将随机写转化为顺序写比较容易,但是如何支持高效的随机读和顺序读挑战比较大,因为这需要一些合适的索引结构,比如CouchDB中的Copy-On-Write的Btree。LSM方式的另外一个问题是垃圾回收(compaction)。
Query Processing
NoSQL数据库的查询能力是跟数据分布模式、提供的一致性和数据模型相关的。
Primary key lookup基于主键的查询在所有NoSQL数据库都是支持。Filter query在range和hash partition都容易做(range partition下通过filtered full-table scans,hash partition下通过scatter-gather模式)。
为了提高效率,可以建索引。不过全局索引很难做,因为全局索引也要分区,这就导致更新操作除了更新原始数据表,还要更新索引表,很容易引入跨很多个分区的分布式事务造成性能问题。有些系统采用最终一致性的索引来避免这个问题,有的系统干脆就不支持全局索引。
Query planning查询计划对于aggregation和join来说是非常必要的,因为如果在客户端做的话,会非常低效。
In-database analytics可以在数据库内部实现如MongoDB、Riak、CouchDB,或者可以通过外部分析品台如Hadoop、Spark、Flink等完成(Cassandra和HBase属于这种)。
Materialized view物化视图也是降低查询延迟的一种方式,物化视图随着数据的更新而更新。物化视图也有和全局索引类似的问题。
NoSQL数据库要支持near-real-time analytic可以通过Lambda Architecture或者Kappa Architecture。Lambda Architecture用流式处理的系统如Storm来补充批处理的系统如Hadoop。
Kappa Architecture只使用流式处理方式,不再使用批处理。
Decision Tree & Conclusion