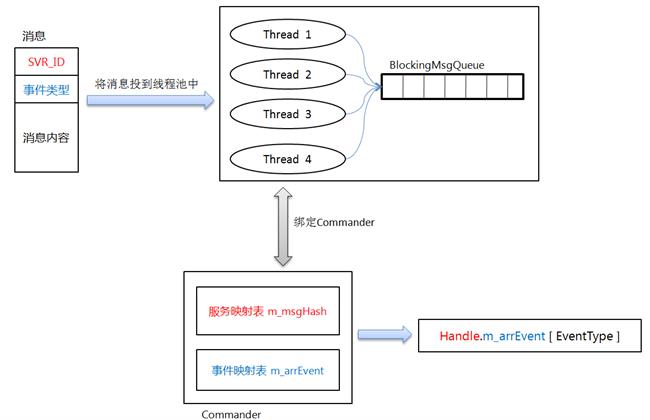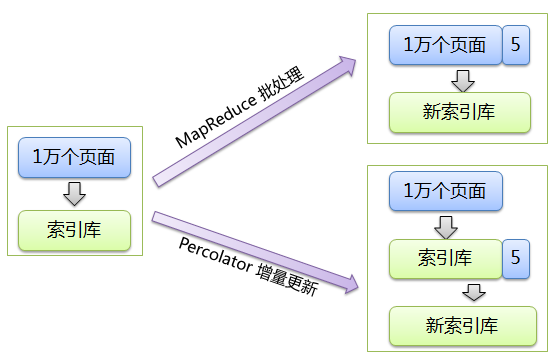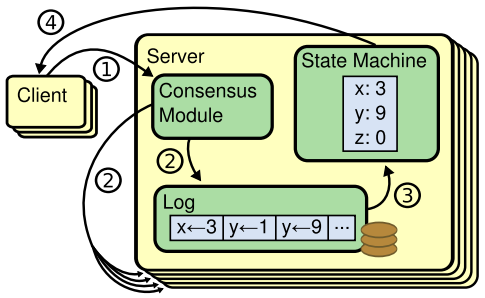
原文:https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/top-down-microarchitecture-analysis-method.html
现代CPU一般都采用了流水线、硬件线程、乱序执行、指令级并行等技术来高效利用CPU内的各种资源。但有很多软件和算法在实现上并不能很好地利用好CPU,比如非常常见的链表会带来间接地址访问,影响硬件预取的效果,导致读数据的时候流水线...