本文是 Why Functional Programming Matters(为什么函数式编程很重要)的阅读笔记,用相对通俗的语言解读了这篇论文,并对我觉得重要的一些点做了一些解释。
本文是 Why Functional Programming Matters(为什么函数式编程很重要)的阅读笔记,用相对通俗的语言解读了这篇论文,并对我觉得重要的一些点做了一些解释。

最近在搞性能优化,读了一篇挺有意思的相关论文。
Performance of memory reclamation for lockless synchronization
这篇论文测试了几种LockFree数据结构的内存回收性能和简单的分析。
本文是《挑战程序设计竞赛》读书笔记的第三篇,主要涉及图算法,图的搜索,单源最短路和所有点对的最短路Floyd算法,最小生成树算法。文中解释了Roadblocks问题:求出图中指定的起点s和终点e之间次短路(第二短的路径);Conscription招兵问题。
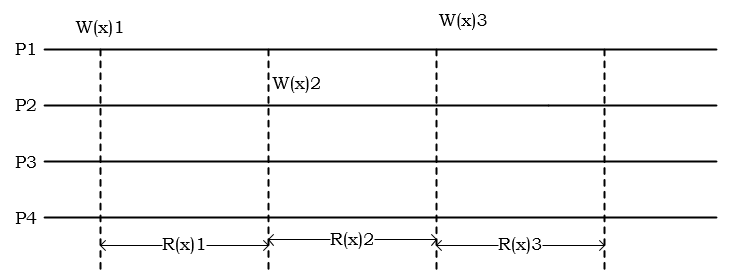
本文讲述分布式系统的一致性模型
Anna KVS官网对Anna的特性总结得非常到位:1. Crazy Fast, 2. Super-Scalable, 3. Flexibly Consistent。这里只关注Flexibly Consistent这一项,讲讲Anna是怎么实现灵活的consistency的。这篇博客算是论文导读,详细内容读者仍要仔细阅读论文原文 Anna: A KVS For Any Scale。
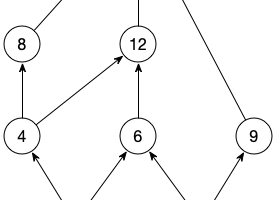
Lattice是什么,基于格怎么实现灵活的多种一致性,漫谈Consistency和Isolation Level。
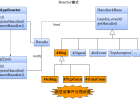
介绍Cwinux中关于Reactor模式的具体实现。