分布式并发控制算法评估
An Evaluation of Distributed Concurrency Control(VLDB17')
这篇工作主要是比较并评估了6种in-memory分布式数据库的并发控制计算法。
System Overview
论文在Deneva系统上做分布式并发控制算法实现和测试。
Architecture
Deneva架构:shared-nothing
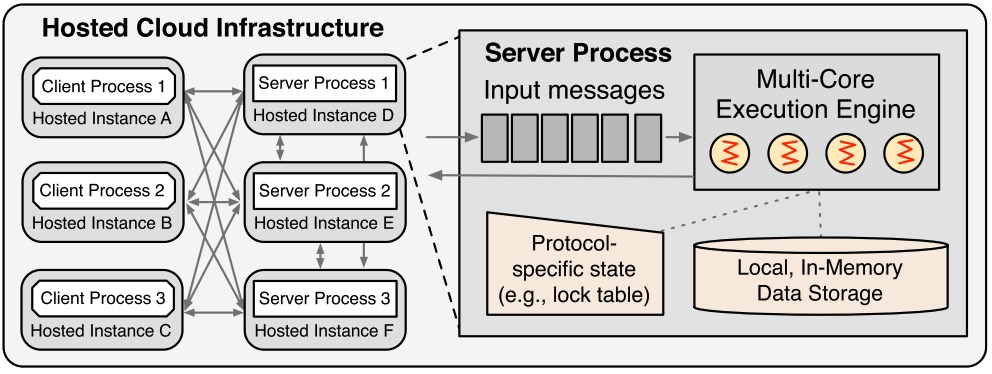
Env Model
所有的事务都使用存储过程,有些协议只能执行确定事务(需要提前知道访问哪些行)。
数据按consistent-hash分布,client上配置location信息。
存储引擎是个纯内存的hashtable。
Transactin Protocols
Two-Phase Locking
strict 2PL :commit后才释放锁。
各个2PL实现的主要差异在如何处理死锁,论文介绍了两种思路:
- NO_WAIT:prevent deadlock,锁加不上就abort(真暴力)。
- WAIT_DIE:事务排序打破循环依赖。
Timestamp Ordering
给事务分配时间戳,时间戳用来给事务定序。
Optimistic
Optimistic Concurrency Control (OCC)
Deterministic
使用一个中心节点来给事务预先定序,类似于Calvin。
并发请求发给sequencer,然后sequencer收到后打包定序(按epoch打包,每个epoch比如5ms),然后发给对应的若干server,server上有scheduler负责行锁、执行之类的逻辑,执行时依赖预先定义好的序。
Calvin只能处理one-shot事务,要求事先知道要读写哪些行。这是一个很大的限制。
Two-Phase Commit
原子提交。注:Calvin不需要,因为它只有一个全局日志流,具体参考Calvin的论文。
OCC的时候,prepare阶段做validation,原因是参与者回应协调者的prepare yes就意味着将来可以提交,所以必须要先过validation。
Evaluation
实验环境:Amazon EC2(8核32G),网络 1ms RTT。
benchmark:YCSB、TPCC、PPS(Product-Parts-Supplier)。
测试结果(single-partition)

Calvin因为是预先定序的,所以线比较平稳。
测试结果(multi-partition)
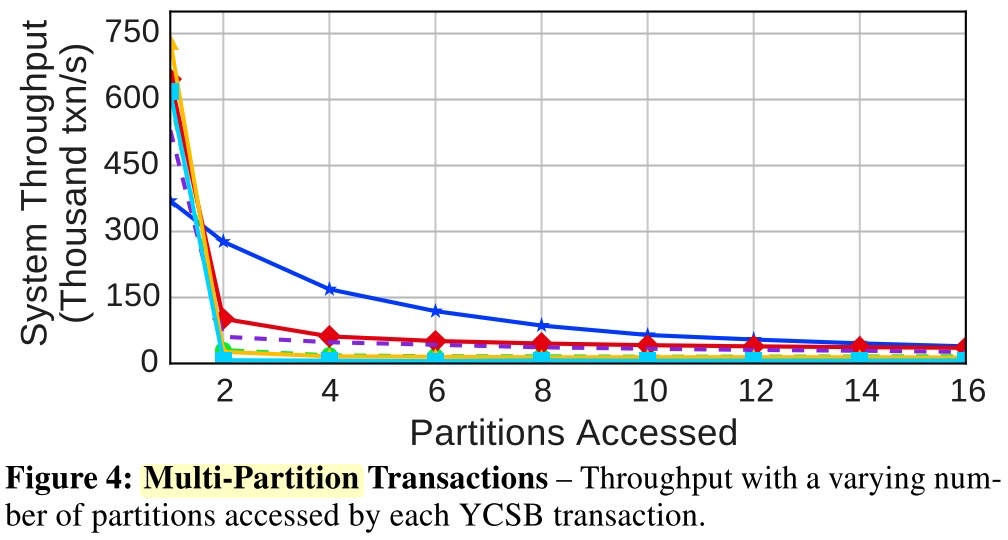
基本上单partition变多partition时,都会因为网络交互导致骤跌plummet。Calvin因为预先定序无2PC,所以影响小一些。
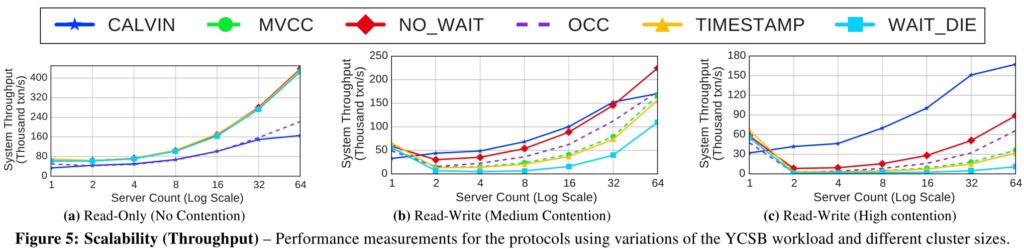
RO测试:Calvin是因为scheduler的瓶颈,OCC是因为为了validation阶段准备的复制数据的开销。
RW测试:除了Calvin,其他变化趋势都差不多。
论文还对scalability的开销做了breakdown:
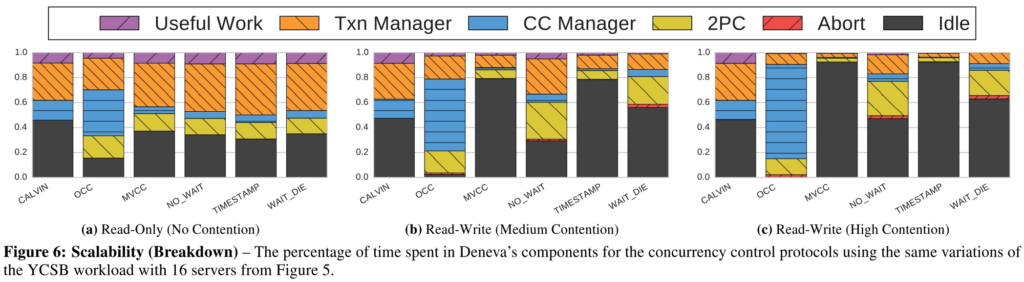
图6b/c和图6a相比,MVCC和TIMESTAMP的idle时间变多,原因是需要buffer一些事务以等待order小的事务先提交。
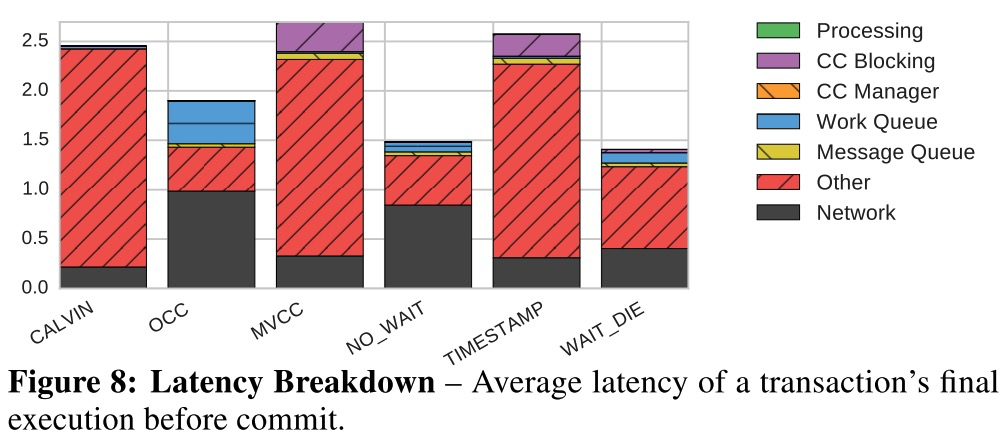
OCC:the worker threads spend over 50% of their execution time in the validation phase of OCC
Other也太多了,不知道延迟花到哪里去了。
Discussion
解决扩展性瓶颈的方法:
- 提升网络
- 换用数据模型,减少分布式事务
- 换编程模型,不一定要serializable。
一点总结
- 分布式并发控制跟单机并发控制的区别没怎么讲
- 只测试了serializable的情况
- 解决方案略显trivial
1 条留言 访客:0 条 博主:0 条 引用: 1 条
来自外部的引用: 1 条