LSMTree自适应内存管理
Breaking Down Memory Walls: Adaptive Memory Managementin LSM-based Storage Systems(VLDB'21)
内存管理整体架构比较清晰,如图,无需赘言。
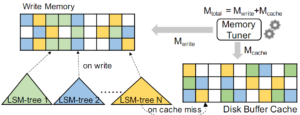
Write Memory内存管理
Write Memory的管理方式见下图。
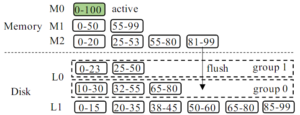
像RocksDB的Write Memory就是一整个memtable,论文给出了另外一个思路,即使是write memory也用leveled方式,如图。Memory也分成M0,M1,M2三层,M0满则merge到M1,同理M1 merge到M2,M2会刷盘。这种方式的内存利用率更好,否则考虑一个很大的memtable对象flush之后,内存释放出来,新的memtable在前一段时间内内存利用率都很低。不过这种方式看起来也有点不必要地复杂了。
L0允许多个layer,一个layer这里叫做一个group,如果新memtable数据flush下来,先去看最老的group能不能直接放进去(并且也要保证其他较新的group没有重叠范围的数据),不行就生成一个新的group。
Partial Flush & Full Flush:略。
Managing Multiple LSM-trees
略
Memory Tuner
论文提出的内存管理框架实际上就两个模块消耗内存,write memory和buffer cache。
论文给出了一种计算最优分配的方法:
首先,设write memory内存配额是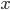 ,则以IO代价函数为优化目标
,则以IO代价函数为优化目标 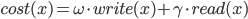 。
。
然后,就是一个简单的数学问题,导数求最小值。
最后,实现一个反馈机制。
一点总结
论文要解决的问题是一个很实际的问题 -- memory wall。
性能的提高,包括内存利用率的提高,稳定性的提升,都对内存跨模块拉平管理提出了要求。但是很多存储引擎的搞法往往都是固定配额这种很不成熟方式。
具体如何实现高效的内存管理,论文给出了一种方法,当然也可以继续沿着这条路走,除了依据理论模型计算的方法外,基于AI的方式应该也是可以尝试的。