REMIX: Efficient Range Query for LSM-trees
LSM-Tree引擎的scan操作是一个引擎固有的短板,其根源在于相比基于B+Tree的引擎如InnoDB的数据全局有序,LSM-Tree的数据有序性差,它由多个sort run组成,因此scan的时候需要对多个sort run进行merge。
考虑如下的情况,比如做一次全表扫描,扫描过程中对若干sort run进行了merge。但再有一次全表扫描时,还是需要进行一次merge。两次merge进行的操作是完全一样的,因为这些sort run都是静态数据。
REMIX sorted view
那么如何降低scan的开销呢?
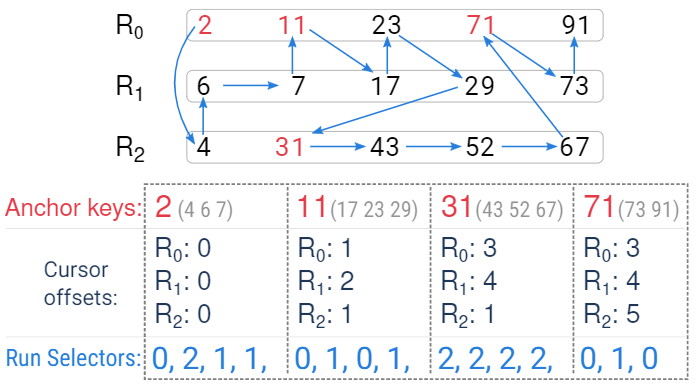
将若干sort run的sorted view用图示的方式持久化下来,用于这些run上的高效查找和scan。
具体地,有序key列表分成若干segment,每个segment记录segment内最小key作为anchor key,同时记录cursor offsets 和 run selectors,cursor offsets记录每个run在该segment内的第一个key在run内的offset,run selectors用于记录segment内的runs merging输出次序。
有了这样一个数据结构,如图在这三个run上从target_key=17开始查找并继续迭代的话,成本就很低了。
首先seek 17时,在anchor keys上用二分查找最后一个小于17的segment,得到Segment 2 (11所在segment),然后在segment内用二分查找17(后详)。
然后iterator next时,只需要基于cursor offsets和run selector顺序返回即可,无需再做key compare。
那么segment内如何二分查找呢?考虑以下的情况。
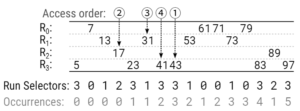
首先,run selectors是已有的信息,假设另外存在occurrences信息,occurrences[i]的含义为segment内第i-th个key在其所在run内是第几个。例如sorted view中第6个key=41,那么occurrences[7]表示key=41是所在run=run_selectors[7]=R3的第2个(0起)。因此找key=41则在R3上迭代2次。
注意到occurrences包含的信息量完全包含在run selectors中,并且可以通过SIMD高效地临时计算出来。
sorted view空间开销
设segment里面有D条key,每个cursor占S字节,H表示run数目,则每个key平均多占用的空间为
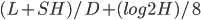 字节。
字节。
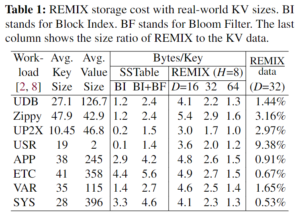
从实测的数据看,空间占用还是完全可以接受的。
重建sorted view
LSM-Tree会将MemTable数据刷到磁盘,所以sorted view数据要像compaction一样后台重建。
注意到,一个sorted view作为一个run,整体和一个新刷下来的sstable文件做一二路归并就可以创建新的sorted view。
RemixDB
基于上述索引方式,加上宏观上partition的结构,构造的一个DB。
没有新东西,略。
总结