SingleStore - 云原生HTAP
以前的MemSQL,shared-nothing架构的DBMS,分区混部,多副本HA,支持RO副本,支持code generation,支持跨域异步复制副本。另外也支持基于对象存储存放冷数据。
S2DB还可以做到交互式实时洞察和决策、高吞吐低延迟写入和在变动的数据上执行复杂低延迟查询,这在多个专用系统缝合的方案中很难做到。
S2DB的两个设计要点:
- 存储计算分离 Separation of Storage and Compute
- 统一表存储 Unified Table Storage
存储计算分离
S2DB是一个shared-nohting架构的分布式数据库,但同时也可以访问分离的对象存储。
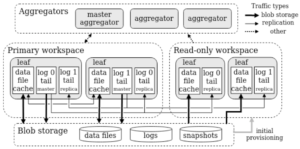
使用对象存储的时候,S2DB的架构跟其他存算分离的系统有一些差异,S2DB并不是把所有数据都存到对象存储系统中,而是会利用好本地存储存放新写入的数据,之后再异步将数据移动到对象存储。这个思路既可以做到冷数据存对象存储,又可以做到事务提交延迟不受对象存储访问延迟拖累。事务的持久化靠多S2DB自身的多副本实现。
Staging Data From Local To Remote Storage S2DB更好地利用了数据冷热和云存储层次(本地内存-本地磁盘-对象存储)。 像Snowflake、Redshift等似乎都没有利用好这种存储层次,它们可能会把数据直接写到对象存储中。 S2DB在这块的一些设计:
- S2DB会将新提交的数据写在本地盘,然后异步推送到对象存储。提交延迟主要是本地盘开销和副本复制开销。
- 新生成的列存data file会异步尽快上传到对象存储,热数据会被缓存到本地盘,冷数据在上传完之后可以删除。
- WAL也会上传到对象存储,但只会上传到已经复制完成的位点。
- 行存做snapshot(即checkpoint)由master partition负责,并且直接写到对象存储。
- 在对象存储中存放历史版本数据,支持PIT恢复,不需要显式执行备份操作。
- 可以从对象存储中构建只读副本作为计算节点,获取snapshot和wal,然后开始从master partition复制后续的wal。这提升了读能力,而且只读副本本身与其他副本有较强的隔离性。
这种充分利用本地盘的思路对写性能提升是非常显著的,但缺点也很明显:
- 高性能的本地持久化和数据复制流程比较复杂,工程实现上实际上跟一个纯shared-nothing架构的产品在这块的差异不大。
- 弹性不足,新增或删除节点需要复制本地存储中还没同步到对象存储中的那部分数据。
- 在关联失效的情况,可能丢数据(比如本地盘和该partition的其他副本所在盘同时失效)。
Capabilities Enabled by Sepearted Storage 独立的存储带来的能力:
- 在对象存储上保留历史数据,实现PITR。
- 创建RO副本很容易,而且RO副本不影响事务提交(不参与日志持久化投票、资源隔离好)。
主要还是存储空间和成本相比本地存储得到很大解放,整体因独立存储带来了一定程度的弹性。
统一表存储 Unified Table Storage
统一表存储的好处是节省了用户操心表存储方式的问题。
表存储格式 统一存储格式为:内存行存+硬盘列存。
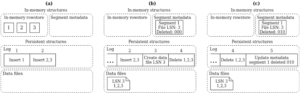
内存行存
- 数据结构:lock free skiplist;skiplist的node作为一条记录;该记录的多版本挂链存放;行锁放到node中;记录按定长处理,变长的字段用指针指出去。
- 写流程:数据写skiplist,并写wal,wal是per-partition,后台定时checkpoint in-memory skiplist并维护对应的log位置。
硬盘列存
数据划分为segment,segment内每一列都按相同的row order存放,并各自压缩存储。压缩支持Bit-Packing、字典编码、RLE编码以及LZ4压缩。segment的元数据(文件位置、编码方式、每列最值、删除标记vector)放在行存表中,并加载到内存。 S2DB表存储方面的一些设计点:
- 列存支持直接根据offset读取一行,而不必解码该segment的所有行,适合TP中常见的点读。
- segment上支持创建sort key,即二级索引。每个segment有自己的局部的二级索引,全局的二级索引采用类似于LSM Tree的方式,新导入数据产生的segment逐渐按层次往下合并,最终保持大约 sort run count = log (segment count) 。
- 对于每个列存表,S2DB都会创建一个写优化的行存表来保存小数据量的写入数据。这部分类似于RocksDB的MemTable,后台会定期将这部分数据转为列存segment。
- 删除是通过在segment meta中标记delete-vector来实现,更新操作也是通过删除旧数据+插入新数据实现。这样可以避免做行数据的合并。
二级索引
二级索引主要是针对TP负载的优化。 一些系统采用的经典方法有:
- Per-segment filtering structure: 每个segment增加局部的bloom filter或者inverted index,如RocksDB、Procella(in youtube)
- external index structure: 外部整体再配个lsm tree索引,将二级索引列映射到主键索引列,如Spanner。
S2DB的二层索引结构 S2DB的二级索引不太一样,它采用的是二层结构加LSM Tree存储的方式。
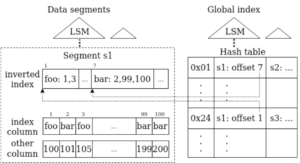
首先是segment内部的局部索引,即图中 inverted index。它记录了index column值和该值在segment中的offset list。因为segment是不可变的,所以这个索引只需要生成一次。 然后还有一个全局的索引,它记录的是index column值到各个segment的inverted index的索引。当前S2DB的全局索引仅支持无序的二级索引,也就是hashtable。当新的segment生成的时候,就生成LSM Tree里面的一层,逻辑上就是一层hashtable,层数多了也会触发compaction合并hashtable。论文中声称未来会支持有序索引,感觉这个就比较麻烦了。
多列二级索引 S2DB会分别单列建索引加多列索引,这样可以兼容index columns subset的过滤,多列索引同时还要支持unique check。S2DB的这块实现看起来也没有什么亮点。
行锁
略
Adaptive Query Execution
HTAP模糊了负载的差异,因此查询引擎更要准确地对存储层接口调用进行合适的排序调度,比如查询的某个filter使用二级索引,另一个filter使用编码执行(encoded execution),这两个filter的顺序取决于selectivity和执行代价。优化器生成的静态计划可能不是最优的,因此S2DB采用了adaptive query execution的方式动态决定数据访问方式。
S2DB中数据访问大致上分三层:
- 找到要读的segment列表
- 在每个segment上执行filter,读取所需的row
- 解码和输出row
Segment Skipping:
依赖全局索引或者segment meta的min/max值过滤掉整个segment。
Filtering:
- regular filter 先decode再过滤
- encoded filter 比如字典编码,可以直接在编码后的数据上执行
- group filter 解码所有过滤列再执行过滤
- secondary index filter
测试数据
TPCC测试结果看,性能与一般云TP数据库性能接近。
TPCH测试结果看,成本与其他云数仓差不多,性能还好一些?
一点总结
S2DB最早是从MemSQL演化过来,一个shared-nothing架构的系统支持了对象存储,从而增强了弹性。S2DB将wal的尾部数据的持久化交给了本地盘,这个设计对TP性能至关重要,尤其是TP事务延迟,但同时也带来了尾部数据可靠性和可用性的其他问题。不过对于S2DB来说这不是一个问题,因为它原来就是shared-nothing架构的,这些问题应该在之前的版本已经解决过了。另外一点是这个设计使得S2DB的弹性不如Snowflake等,S2DB的计算节点并不是完全无状态的,而是有少量的一点状态。我个人认为这个弹性损失没有那么大。
1 条留言 访客:0 条 博主:0 条 引用: 1 条
来自外部的引用: 1 条