《Access Path Selection in a Relational Database Management System》 1979
SQL语句处理的四个阶段:Parsing, Optimization, Code Generation, Execution。
query block: 由select from where表达的查询块。
单表查询
代价
Access Path Cost公式: cost = page fetches + w * (RSI calls),其中rsi for system R storage interface。
公式是IO代价(主要是读取页面)和CPU代价(System R的CPU主要消耗在storage层)的加权结果,权重w是个经验值。
谓词
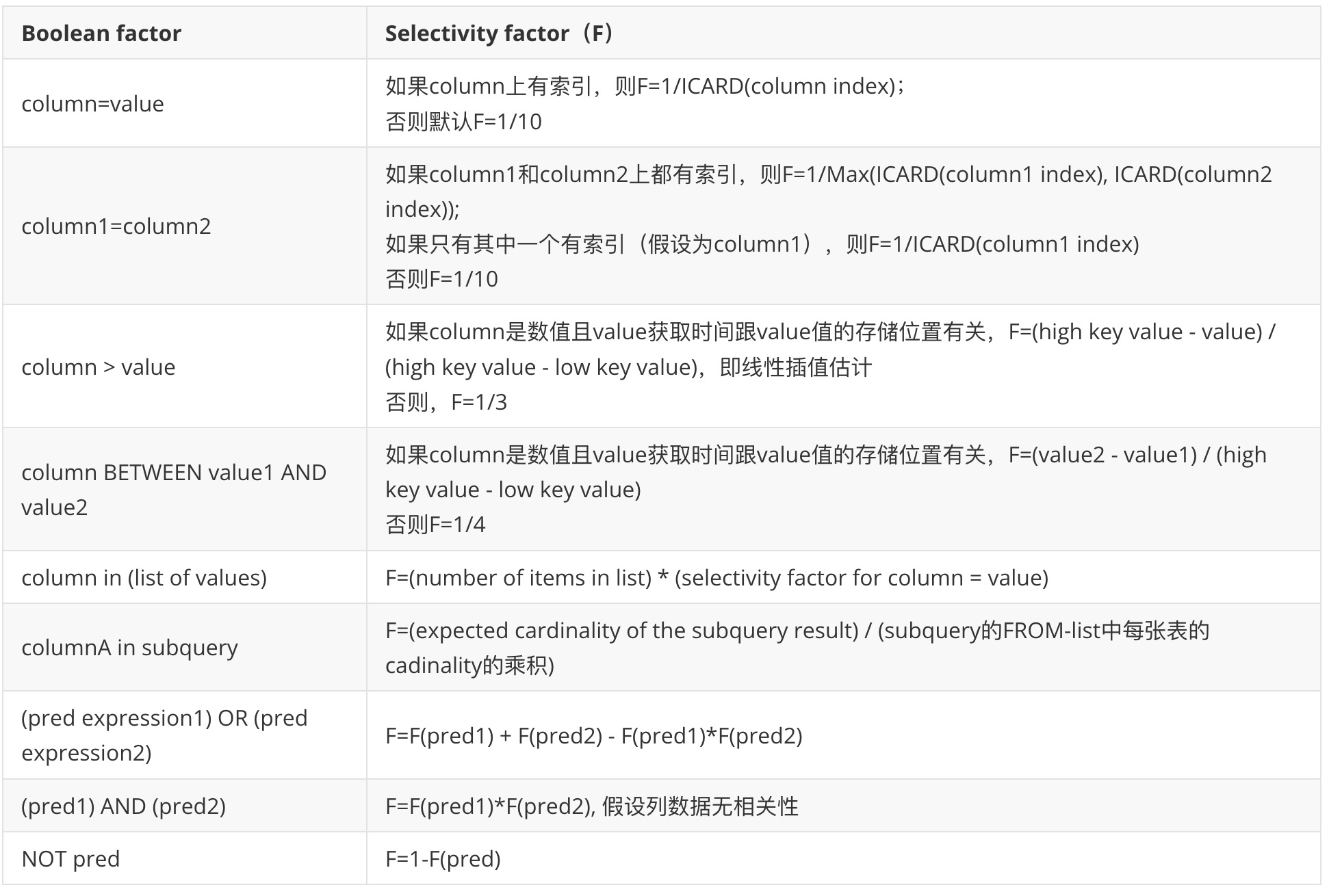
where条件被视为合取范式(conjunctive normal form),其中的每个合取式称为boolean factor,一条记录满足所有的boolean factor才能满足该where合取范式。如果一个boolean factor涉及的所有列都在某个索引中,则称该索引match该boolean factor。
如果存在一个满足某boolean factor的索引,使用该索引则查询更高效。
统计信息
优化器还会查询catalog中记录的统计信息,包括:
- NCARD(T) 表T的基数(cardinality)
- TCARD(T) 表T的page数量
- P(T) segment中有效页面(?)与总页面比例
- ICARD(I) 索引I上唯一键值数量
- NINDEX(I) 索引I的页面数量
使用这些统计信息,优化器将为每一个boolean factor分配一个selectivity factor(记为F),该值粗略地等于满足该条件的记录比例。
以下有几个例子(基本上可以用简单的数理统计知识推算):
单表查询cost取决于 selectivity factors和统计信息。
除了cost之外,优化还受interesting order(query block的GROUP BY或者order by子句中用到的顺序)影响。
将三个因素考虑进来,单表的优化过程就是针对每个access path计算cost,如果这个access path没有interesting order,则还需要加上排序代价,最后找到cost最小的access path。这里排序代价的问题是指:比如用户查询是select * from t1 order by c2,但当前access path是走c3,c1索引扫描,则扫出来的结果还要进行按c2排序,这个sort cost也要算进来;如果当前access path就是按照c2索引扫描,则数据已经是按c2有序,不再需要额外的排序开销。
代价公式(跟具体存储引擎实现关系很大,这里可以简单看看)
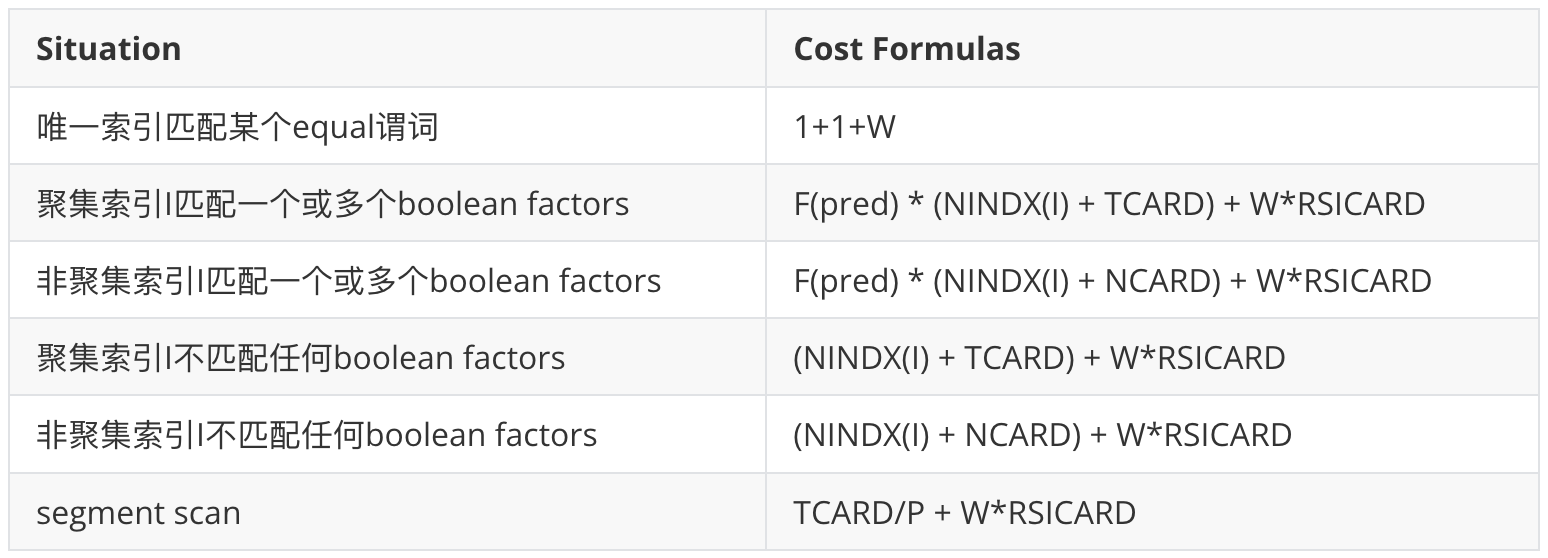
其中,W是Page Fetch和RSI CALL开销的相对权重。
JOINS
join基本概念
outer/inner relation, join predicate, join columns
Join的两个维度:join method, join order
join的两种方法
join方法1 nested loops:outer/inner relation两层循环。
join方法2 merging scan:适用于等值join的情况,两个表都按join column扫描,然后生成join行。如果有多个join谓词,则其中一个作为普通谓词。merging scan的优点事可以避免对inner relation进行重新scan(比如在某个join column值上,outer relation有5条记录,inner relation有10条聚集的记录,则inner relation可以记录下这10条记录中第一条的cursor,这样对5条outer relation的记录,就不需要每条都对inner relation从头扫描了)。
多表join可以视为一系列的单表join。值得注意的是,最前两个表的join不必完成就可以执行和第三个表的join,而且两次join也分别采用各自的join算法。
多表join order
如果有N个表join,则有 N! 个join order,且结果都是一样的,但不同order的开销差异可能巨大。
在找最优order的时候,需要注意到当前K个表已经join完成,则第K+1个表的join不需要关注前K个表是按什么顺序join的。这是很多搜索最优解算法的基础。
join order的一个启发:优先考虑带join predicates的这些join的order,笛卡尔积的计算尽量后延。
搜索树的构造
对于每次join,结果集的cardinality会被保存下来,如果结果集还需要排序,排序代价也会保存下来。最终的优化结果是join order和每个join各自的join method和每个表的access path。另外,interesting order的数量有机会通过等价类来减少。
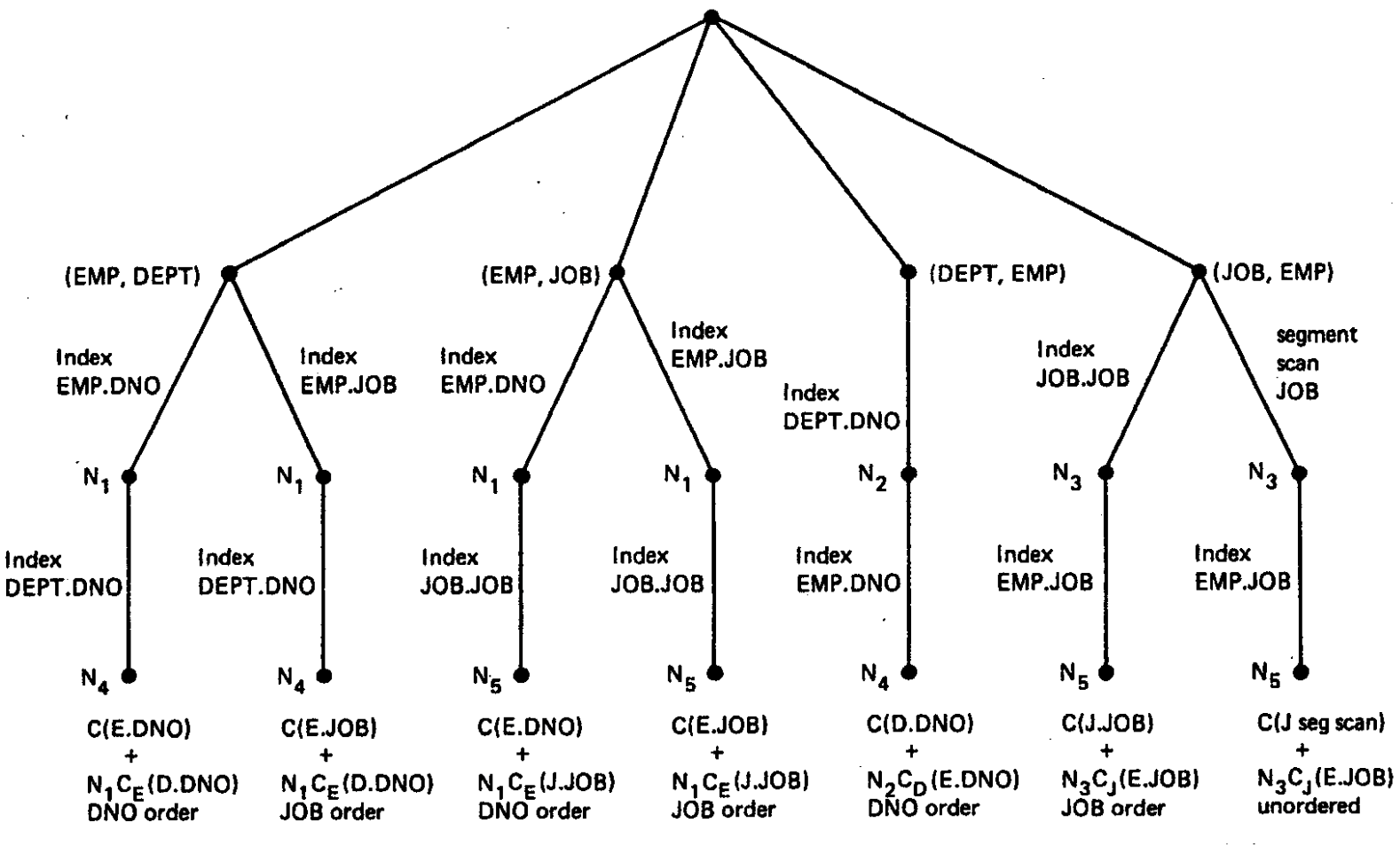
具体构造方法:首先针对每一个单表找到最优的access path;然后针对每一个表和其他表的两两join找到最佳,然后再加第三张表计算,依次类推。
代价计算
设C-outer(path1)是在path1上扫描outer relation的代价,N是outer relation的cardinality,C-inner(path2)是扫描inner relation和apply predication的开销。
则N的计算方式为 N = (截止目前join的表的cardinality的乘积) * (所有已经应用的predicates的selectivity factors的乘积)。
那么,一个nested-loop join的开销为:C-nested-loop-join(path1, path2) = C-outer(path1) + N * C-inner(path2)。
merge sort join的开销类似,但是要计算sort开销。纯merge的开销 C-merge(path1,path2) = C-outer(path1) + N * C-inner(path2)。C-inner(sorted list) = TEMPAGES / N + W * RSICARD。
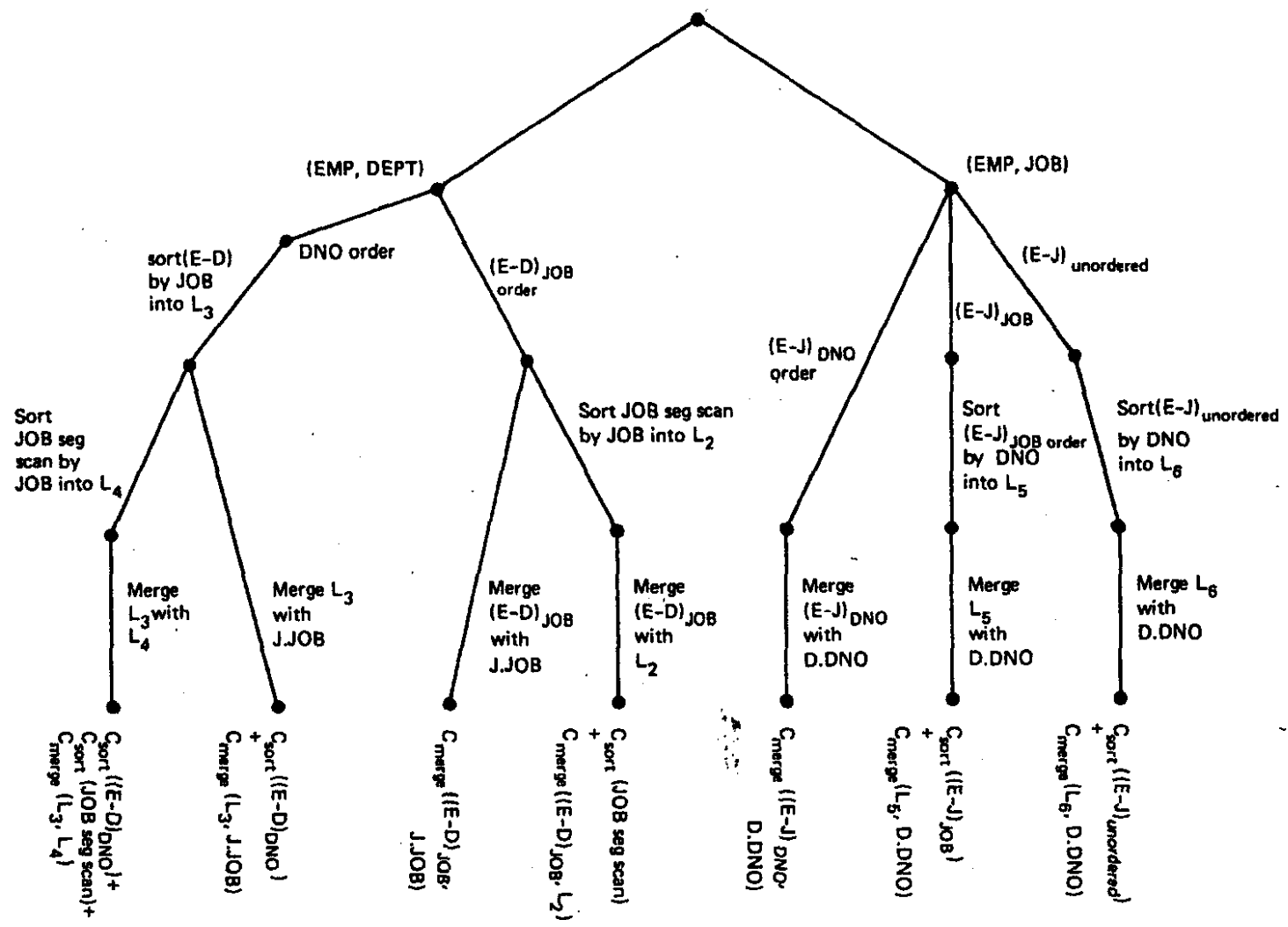
图示
以如下的查询为例
先针对每一张单表构造如下的图示,以下图第一条线段为例,其含义为EMP表的一个access path为通过index EMP.DNO查询,代价为C(EMP.DNO),且基数为N1。
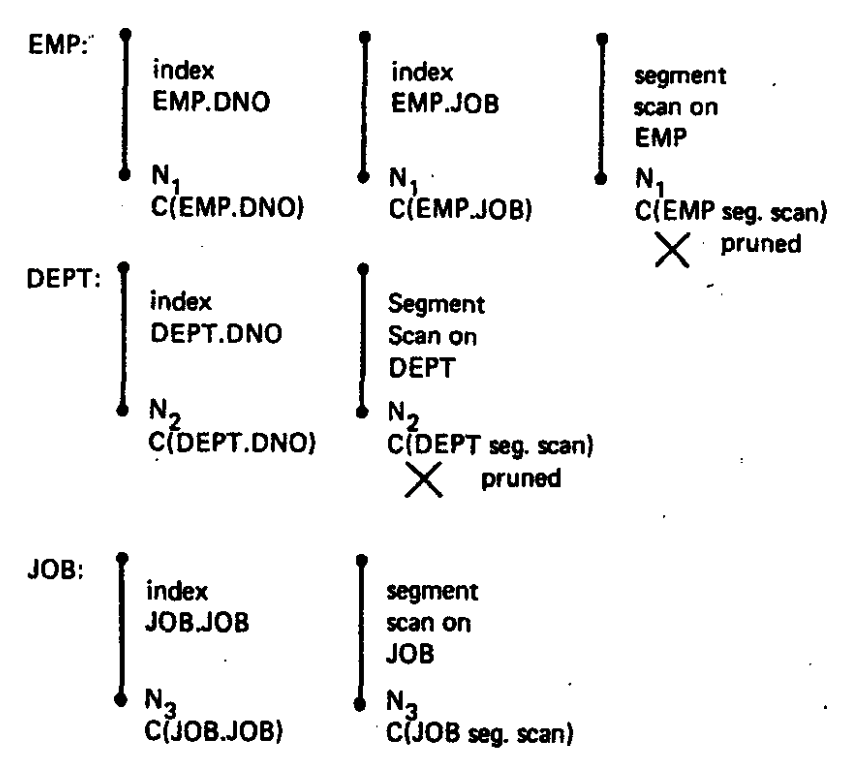
在单表基础上,考虑第二张表的join,再考虑进第三张表,如下两图示。
嵌套查询 Nested Queries
例子:
查询1:SELECT NAME FROM EMPLOYEE WHERE SALARY = (SELECT AVG(SALARY) FROM EMPLOYEE);
查询2:SELECT NAME FROM EMPLOYEE WHERE DEPARTMENT_NUMBER IN (SELECT DEPARTMENT_NUMBER FROM DEPARTMENT WHERE LOCATION = 'DENVER');
查询3:SELECT NAME FROM EMPLOYEE X WHERE SALARY > (SELECT SALARY FROM EMPLOYEE WHERE EMPLOYEE_NUMBER = X.MANAGER);
查询4:SELECT NAME FROM EMPLOYEE X WHERE SALARY > (SELECT SALARY FROM EMPLOYEE WHERE EMPLOYEDD_NUMBER = (SELECT MANAGER FROM EMPLOYEE WHERE EMPLOYEE_NUMBER = X.MANAGER);
其中查询1和2中,嵌套的查询没有和外层查询有关联。这类查询中子查询只需要执行一次。
查询3和4中是有关联的,且查询4是隔了一层查询的关联。查询3的子查询需要对外层每一行进行一次计算,查询4需要针对最外层查询的每一行计算一次。
扫描二维码,分享此文章