《How to Architect a Query Compiler, Revisited》 SIGMOD’16
数据库执行一个查询的流程包括前端语法解析、优化器以及后端解释执行。语言编译器的流程与之类似,除了最后一步会编译成机器码执行,DBMS一般还是解析执行的。
在相当长一段时间内,硬盘IO是主要的性能瓶颈,计划的解释执行有利于移植,因此将解释执行替换成编译执行没有太大必要。但NVM硬件发展和业务对AP型查询需求增多,使得很多时候查询是CPU Bound的,因此将QEP(query execution plan)编译成本地机器码的必要性增加。
学术界对如何架构一个查询编译器有不少争论,有文章认为这个事情很复杂。作者认为编译器圈的人应该负点责任,因为他们没把领域内的一些关键想法、原则和结论解释清楚。课堂上大家只是学习到了各种文法解析的变体、寄存器分配算法,并没有真正实操写过一个编译器,因此没有传达出高效编译器其实很简单这个事实。
对于数据库开发者来讲,肯定没有必要实现一个自己的编译器后端(寄存器分配这些步骤),而是应该生成C代码或者LLVM代码,以此作为接入点对接编译器的后端。因此核心问题是如何从执行计划到中间(C/LLVM)代码。
这篇论文表明,低级代码和编译器多轮编译都不是必须的,提出了一种新的原则指导的方法,并实现了一个原型系统LB2。
Futamura Projections
1970年,Codd在CACM上发表了关系模型数据处理,那时候还是层次模型和网络模型流行的时代。1971年Yoshihiko Futamura发表了论文 Partial Evaluation of Computation Process - An approach to a Compiler-Compiler。前者的洞察是数据可以表达为高级的关系表而不需要涉及任何的存储模型和数据访问策略;后者的基本洞察是编译器和解释器并没有基础性的不同,编译完全可以视作解释器的特化(compilation can be profitably understood as specialization of an interpreter),而且这种特化不需要涉及到任何硬件平台和代码生成策略。
specialization
怎么理解这个洞察呢?
specialization一般是指通用函数在部分特定参数下的调用和简化,也叫做partial evaluation。例如
1 | def power(x:Int, n:Int): Int = |
Futamura的核心想法时将specialization应用到interpreter。一个Interpreter的输入包含要解释的代码和该代码对应的输入数据。这个思路在数据库方面的表现如图。
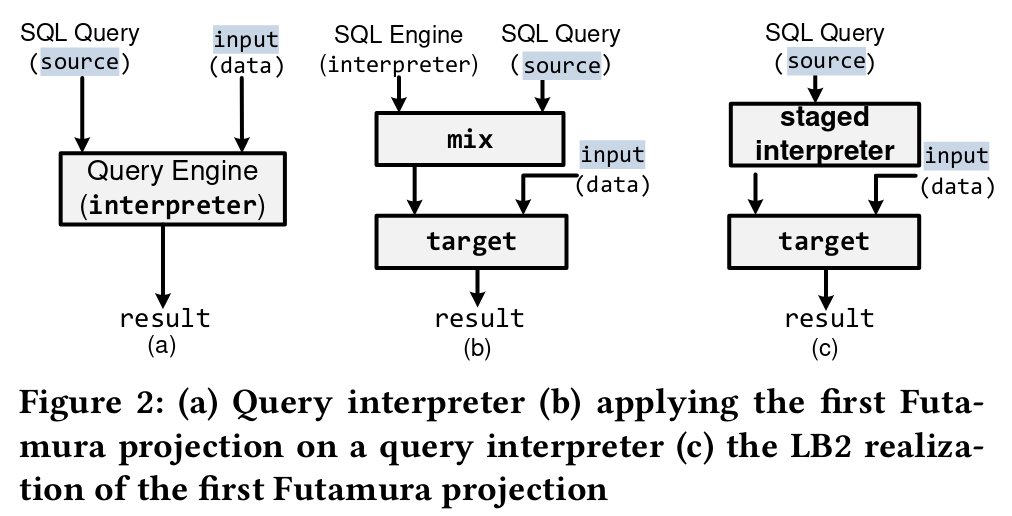
图(a)中是目前解释执行方式,source是指sql语句,不包含参数,类似于prepare statement,input类似于prepare statement的参数。
图(b)是以Futamura思路设计的执行模式,此处mix即specialization或partial evaluation(叫mix是历史原因),这样给定input,就可以直接用mix + data方式计算了,这样性能就会高很多,因为抹掉了 interpretive overhead。图(b)表达的含义换句话说,partially evaluating一个查询的解析器,事实上生成了该查询的编译版本,这就是the first Futamura projection。(This key result–partially evaluating an interpreter with respect to a source program produces a compiled version of that programis known as the first Futamura projection)
Programmatic Specialization
图(b)描述的思路在实践中并不容易实现,需要进一步分析研究更容易实现的思路。
考虑如下的代码,我们假设x是MyInt类型。
1 | def power(x:MyInt, n:Int): MyInt = |
在某个应用中,计算power的时候,传入符号值”in”,则解释执行的最终过程如下(中间步骤参见原文附录B1):
1 | power(new MyInt("in"),4) |
到这里,读者可能已经看懂了这篇论文的核心想法,也即图(c)无mix的版本的思路。图(c)中的staged interpreter实际上就是source中input符号化后的解释执行过程。
非常妙的洞察。
Structuring Query Evaluators
the first Futamura projection本身只是提供了这样一个洞察,但不涉及代码分析和优化。因此后面的问题就是生成优化过的代码。
按照前一章节的思想,specializaion生成的代码和对应的interpreter的代码形状上是一样的。也就是说,如果我们在实现interpreter的时候按照某种特定方式来实现,那么compiled code也就是类似的样子。
接下来论文分析了几种常见的执行模型。
现有的执行模型
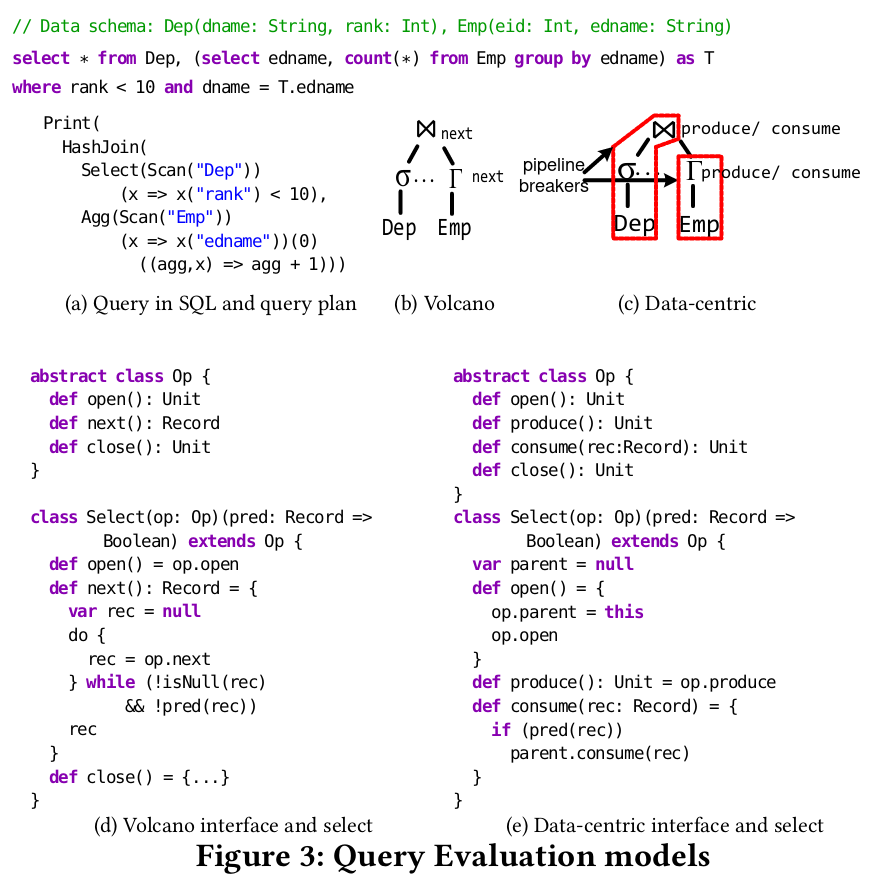
迭代器模型(Volcano模型)
每个算子统一有open/next/close三个接口。执行时从root operator开始调用它的next接口,这会调用后继的operator的next,如此驱动直到底层的操作operator提供一条记录,这条记录返回给调用者,然后operator对这条记录执行自身的code。这种方式称作pull-based。
迭代器模型优点是符合直觉,可以在operator之间进行pipeline。迭代器的缺点是函数调用开销比较大(虚函数多)。
如4(b)表示的 select * from Dep where rank < 10 这条查询的Volcano执行的specialization,可以看到每个operator都会做null check,因为每一个operator本身操作的是动态数据(dynamic data),但实际上只有最底层的operator(Scan operator)才真正需要。
Data-Centric模型
HyPer引入,更适应查询编译,大部分查询编译器都采用了这个模型,如LegoBase、DBLAB、Spark SQL。
Data-Centric模型中控制流是相反的:数据被push到 operator。push模型对数据和代码的局部性更有利。如图3(e),operator包含produce和consume两个主要接口,producer负责获取一条记录,consumer负责执行计算tuple上的计算。这套produce/consume接口实际上比较反直觉,回后面会具体解释其运行过程。
为什么Data-Centric模型更适应查询编译?从Futamura projection的视角看,data-centric模型中,operator内部的控制流并不依赖动态数据(dynamic data),如4(c),每个operator只消费valid的记录,不必重复null check。
Data-Centric Evaluation with Callbacks
Data-Centric模型相比迭代器模型不太直观,因此需要考虑使用另外一套API来达成与Data-Centric相同的编译效果。

前面提到produce/consume运行比较反直觉,这里解释下。如图5(a) 就是push模型,采用了produce/consume的方式。HashJoin包含两个子op,即left和right,HashJoin执行时首先执行HashJoin.produce,这里会先执行left.produce,直到碰到scan或者一个pipeline breaker(需要物化的operator,比如sort或者join),然后此时转而调用其parent的comsume,最后会向上调用到这个HashJoin的consume,这里会将left的所有record都放到hashmap中,完成后,执行流程回到left.produce的结束点,接下来执行HashJoin::produce的下一行代码,即isLeft=false; right.produce,然后又执行到scan,再执行回HashJoin::consume,具体执行图中else分支。由此可以看到,produce/consume运行过程比较复杂,consume实际上是在produce中触发调用的(碰到breaker等情况)。
这种情况生成的代码也会跟breaker有关,如图。
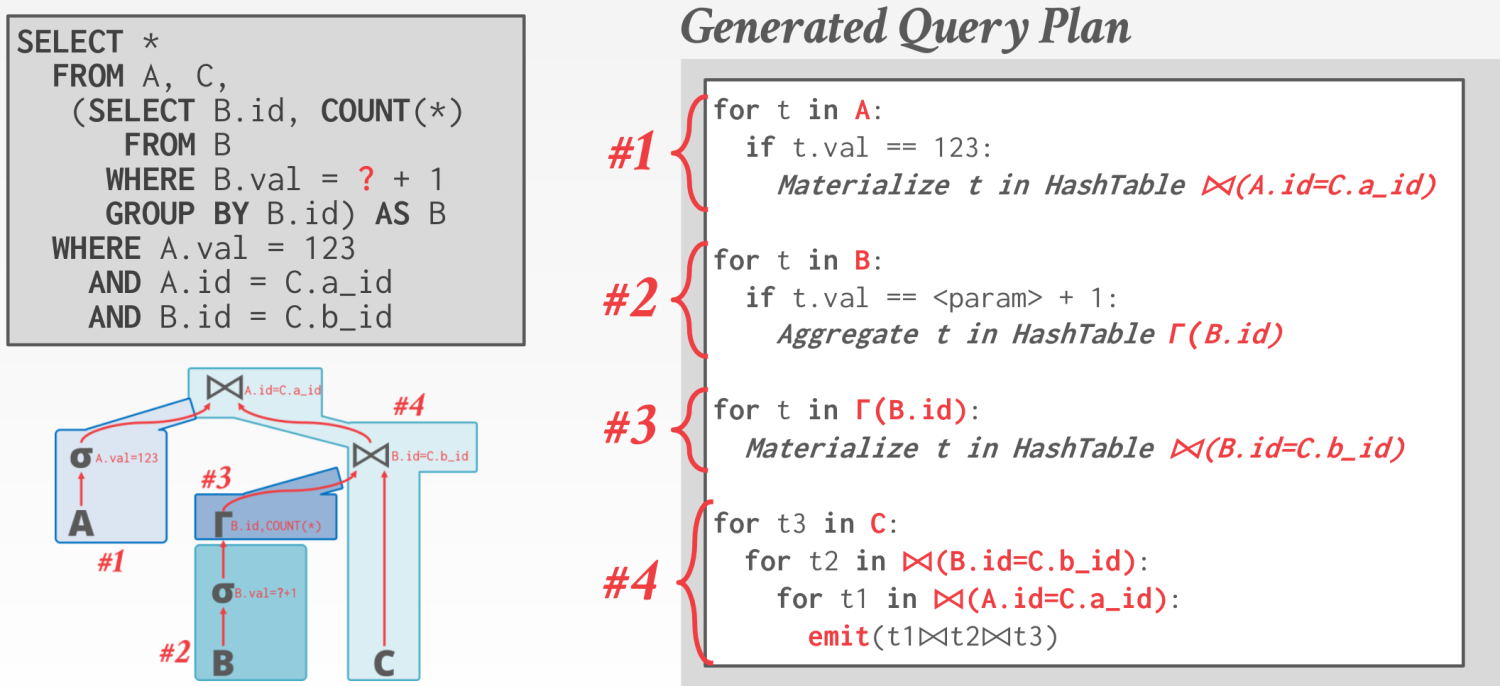
push模型可以看做DFS访问执行计划树,第一次访问调用produce触发准备数据,第二次回来的时候调用consume触发消费数据。
论文这里为了解决这个问题,提出了一个新的push模型:data-centric with callback。如图5(b),exec函数是将produce和consume融合后的函数,其中传入一个回调cb。语义上说,*op.exec(cb)*可以解读为 operator op执行生成结果的逻辑,针对每一行结果,执行cb回调函数。
Building Optimized Query Compiler
前面从原理上讲述了生成代码的原理,接下来看如何j具体地生成高效的代码。首先就是要回答 “ 代码生成逻辑应该放置在哪里? ” 这个问题。
Pure Template Expansion


这个方法的思路就是,直接在op.exec函数中填写对应的代码,如图,代码直接作为字符串。
这方法的缺点:一是代码是自己手写进去的,可能不够优化;二是跨operator的优化做不了;三是把代码以字符串的形式写出来涉及到各种转义等等细节问题。
Programmatic Specialization
相比pure template expansion,将代码生成逻辑下沉到operator的内部成员的数据结构上。

注意到,这里的HashMap还是简单版本的hashmap,我们更想用glibc的成熟的hashmap。
Optimized Programmatic Specialization
代码生成逻辑继续下沉到操作原语层次上。
Lightweight Modular Staging (LMS)
论文提出的LB2执行引擎用的是LMS这套框架…… LMS类似于LLVM。
后面介绍了row/column存储布局、数据结构、数据分区和索引等方面的具体怎么优化成单个代码生成,而且是one pass的。这部分内容比较琐碎。
后面章节给了一张查询编译的演化图:
其他略。
总结
SIGMOD’16 有篇论文名叫How to Architect a Query Compiler,强调了查询编译的困难,本文名叫How to Architect a Query Compiler, Revisited,靶向明显,针对性很强,用非常妙的洞察降维打击,顺便还怼了一把编译器圈子影响力不给力。
论文基于the first Futamura projection对数据库查询编译的产生了新的理解和洞察,这个理解和洞察对于编译器圈子的人或许很容易,但是对于数据库圈的人可能就不太容易想到。
扫描二维码,分享此文章