DDIA Quick Note
说明
《Designing Data-Intensive Applications》从数据系统角度介绍了方方面面的技术点。
内容上,基本都是一个分布式数据库存储引擎所需要的技术能力,而且很多技术点讲的很详细,不过计算引擎基本上没涉及。
另外书里面也介绍了一些其他的数据系统,也都比较有价值。
Part 1 Foundations of Data Systems
Chapter 1 Reliable, Scalable, and Maintainable Applications
Thinking About Data Systems
数据库、消息队列MQ、Cache等等为什么都被归为data system?
第一,数据处理系统往往根据场景做定制,但不同类型的系统界限会变模糊:比如Redis可以当成MQ、Kafka也可以当成数据持久存储系统。
第二,应用的需求比较多,需要多个系统共同组合成一套系统服务应用。
例如这样一个系统:
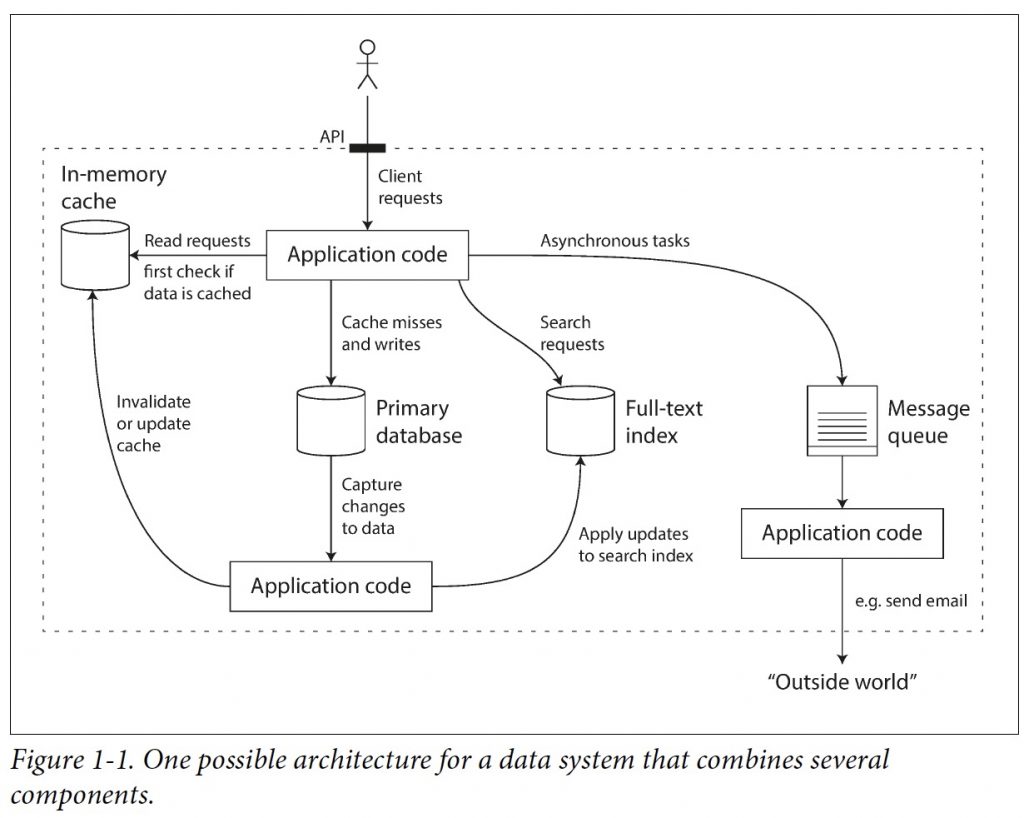
应用开发者要自己对各个子系统做黏合,就是图中的箭头部分,似乎也挺麻烦的,因为要对外(虚线外部)要隐藏整个数据系统被拆解成多个子系统这个事实,就要保持系统间的多个角度下的一致性。
Reliability
fault-tolerant, resilient
硬件故障、软件故障、人为错误。
因为人工配置等原因导致的问题可能比硬件故障导致的问题还多。
Scalability
可扩展性
Maintainability
Operability: Making Life Easy for Operations
运维做什么:
- 监控系统运行情况,出问题时恢复服务
- 跟踪问题原因
- 更新软件或者平台,类似于安全补丁
- 系统之间的互相作用
- 预测未来的问题(容量规划等)
- 部署配置管理等良好实践,编写相应工具
- 复杂的维护任务(应用换平台)
- 定义工作流程,运维操作可预测
- 维持团队对系统的了解
好的可操作性:
- 良好的监控,提供对系统内部状态和运行时状态的可见性
- 自动化,系统与标准工具进行集成
- 不依赖单台机器
- 提供良好的文档和易于理解的操作模型 (If I do X, Y will happen)
- 提供良好的默认行文,但需要管理员自由覆盖默认值
- 进行自我修复,但允许管理员有能力手动控制系统状态
- 行为可预测,最大新都减少意外
Simplicity: Managing Complexity
项目变大后,delightfully simple and expressive code就是很困难的事情。
复杂度complexity的各种症状:状态空间爆炸,模块紧耦合,依赖纠缠,不一致的命名和术语,为了性能加入的一些hack代码,为了解决一些特殊case的work around代码。
工程上控制复杂度是个难题。这个应该怎么做呢?
Moseley和Marks定义的额外复杂度:由具体实现涌现,而非问题本身固有的复杂度。但是问题本身的复杂度又该怎么定义和衡量呢?
消除额外复杂度的经典工具之一:抽象。
complexity refs:
- Frederick P Brooks: “No Silver Bullet – Essence and Accident in Software Engineering,” in The Mythical Man-Month, Anniversary edition, Addison-Wesley, 1995. ISBN: 978-0-201-83595-3
- Ben Moseley and Peter Marks: “Out of the Tar Pit,” at BCS Software Practice Advancement (SPA), 2006.
- Rich Hickey: “Simple Made Easy,” at Strange Loop, September 2011.
Evolvability: Making Change Easy
在组织流程方面,敏捷开发可能会更适应不断变化的环境。
TDD(测试驱动开发)、重构。
语言的边界就是思想的边界。 — 维特根斯坦 1992
Chapter 3 存储与检索
Hash Index
LSM Tree
B Tree
B Tree的一些优化:
- Copy-on-write方式:LMDB(2014)数据库使用COW方案,页面被修改时,不是原地覆盖,而是写到新位置,实际上也产生了页面的多版本。
- 页面上不必存储完整的key:类似于前缀之类信息可以省略等思路。
- 控制页面的物理布局:比如叶子节点在物理上尽量放一块,这个对B树来讲比较难。
- 页面增加额外的指针:例如指向兄弟节点。
- 分形树变体:一些基于LSM思想的变体
其他索引
全文索引和模糊索引
Lucene
数据全放内存
VoltDB, MemSQL, Timesten, RAMCloud, Redis
反直觉的是,内存数据库性能优势并非来自磁盘IO,而是磁盘数据与内存数据的编解码。
NVM
数据仓库
星型模式:以fact表为中心。
列存
列压缩
内存带宽和向量处理
列存储中的排序顺序
写入列存储:B树并不合适,LSM树更适合。内存中是行存还是列存都可以,LSM树将数据写入磁盘,与磁盘数据合并的时候,批量写入列存新文件。参考Vertica。
聚合:数据立方体和物化视图
编码数据的格式
序列化、反序列化
JSON, XML, 二进制变体
JSON比较简单轻量、浏览器支持好。但JSON/XML对二进制支持不好,往往通过Base64转成文本。
Thrift, ProtocolBuffer, Avro
基于模式的二进制编码比JSON/XML的优势:
- 更加紧凑
- 工程过程中容易保证是最新的模式
- 兼容性好
- 静态语言下,可以进类型检查
数据流
数据库的数据流
服务中的数据流:REST与RPC
SOA面向服务的体系结构 / 微服务架构
消息传递中的数据流
Message Broker
RabiitMQ, ActiveMQ, HornetQ, NATS, Kafka
分布式的Actor框架
集成Message Broker和Actor编程模型。
Chapter 5 复制
选主
同步复制与异步复制
多主复制、无主复制
冲突解决
可以在系统内部设定一个应用无关的冲突解决策略,但这种也一定要看应用能不能接受,而且策略本身也往往因为分布式环境的异步网络模型而导致结果也不一定符合应用预期。Dynamo这种可能需要引入上层应用的逻辑来修复数据冲突。分布式环境下追踪数据版本就是很麻烦,毕竟序问题是分布式的根本问题之一。
Chapter 6 分区
KV数据的分区
常见问题:数据倾斜(skew), 热点(hot spot)
分区方式:range分区,hash分区(一致性哈希)
Reblance
请求路由
服务发现
并行查询
MPP
Chapter 7 事务
ACID, 2PL, 2PC, GC, MVCC
Chapter 8 分布式系统的麻烦
故障与部分失效
不可靠的网络
不可靠的时钟
拜占庭故障
Chapter 9 Consistency and Consensus
AB=Consensus。
记录系统(system of record, source of truth),缓存这种是衍生数据系统(derived data system)。
Chapter 10 批处理
MapReduce与DFS
Graphs and Iterative Processing
Pregel处理模型(批量同步并行BSP)
Chapter 11 流处理
有意思
Chapter 12 数据系统的未来
这一章还是值得好好看看。
数据集成
组合使用衍生数据的工具
理解数据流
哪些该先写入,哪些是衍生的,衍生自哪里等等问题。
衍生数据与分布式事务
全局有序的限制、排序时间以捕捉因果序
大型系统维护全局序成本会比较高。
批处理与流处理
Lambda架构
统一批处理和流处理
分拆数据库
组合使用数据存储技术
围绕数据流设计应用
关注衍生状态
面向正确性的设计
数据库的端到端设计
正好执行一次操作
抑制重复
操作标识符
在数据系统中应用端到端思考
强制约束
唯一性约束需要达成共识
基于日志消息传递中的唯一性
多分区请求处理
及时性与完整性
信任但验证
做正确的事情
预测性分析
隐私和追踪