Calcite是Apache旗下开源的、支持多种数据源、提供查询处理/查询优化/查询语言的基础软件框架。
Calcite的三个特点:
- 标准SQL: 工业级的SQL parser, validator, JDBC Driver
- 查询优化器:将查询表达为关系代数,计划生成,基于代价的优化
- 数据源适配:融合第三方数据源
SIGMOD18上的Calcite总结论文《Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources》。
Introduction
Calcite框架组成
- 模块化可扩展的查询优化器,内置几百种优化规则
- 强大的查询处理器,可以处理多种查询语言
- 可扩展的适配器架构,可以支持多种异构数据源,甚至可以跨源做计划优化
Calcite与数据引擎的功能边界划分
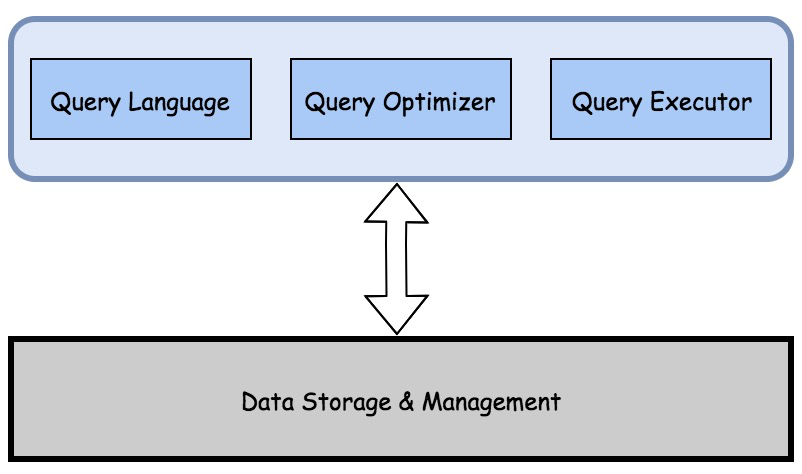
Calcite的优势
- 开源友好:Apache旗下
- 多种数据模型:关系型、半结构化、流式、地理空间
- 跨系统支持:可以跨不同数据源做查询优化和查询执行
- 稳定:久经考验
- 支持SQL:支持标准SQL和多种SQL方言,支持JDBC
Related Work
Orca
Orca是一个模块化优化器,用于Greeplum和HAWK中。
将查询优化和查询执行引擎解耦,中间通过Data eXchange Language交互。
SparkSQL
SparkSQL在Spark基础上扩展支持了SQL查询执行,也可以支持多种数据源。跟Calcite相比,优化过程缺少动态规划方法来避免陷入局部最优。
Algebricks
Algebricks是一个查询编译器,但不需要感知数据模型。高级语言会翻译成Algebricks的逻辑代数,然后生成一个针对Hyracks后端而优化的优化任务。Calcite也支持类似的模块化方法,但Calcite还支持CBO。
Garlic
Garlic支持异构数据源,但不支持跨数据源的优化,只能依赖各个数据源上分别优化。
FORWARD
FORWARD支持SQL++,一种SQL的超集。
SQL++支持半结构化数据模型和关系模型的集成。在这一点上,Calcite是通过在计划生成阶段将半结构化数据表达为关系模型来实现集成的。FORWARD的方法是将多种联合查询拆解成各自的查询计划,然后执行结果在FORWARD引擎中合并。
Architecture
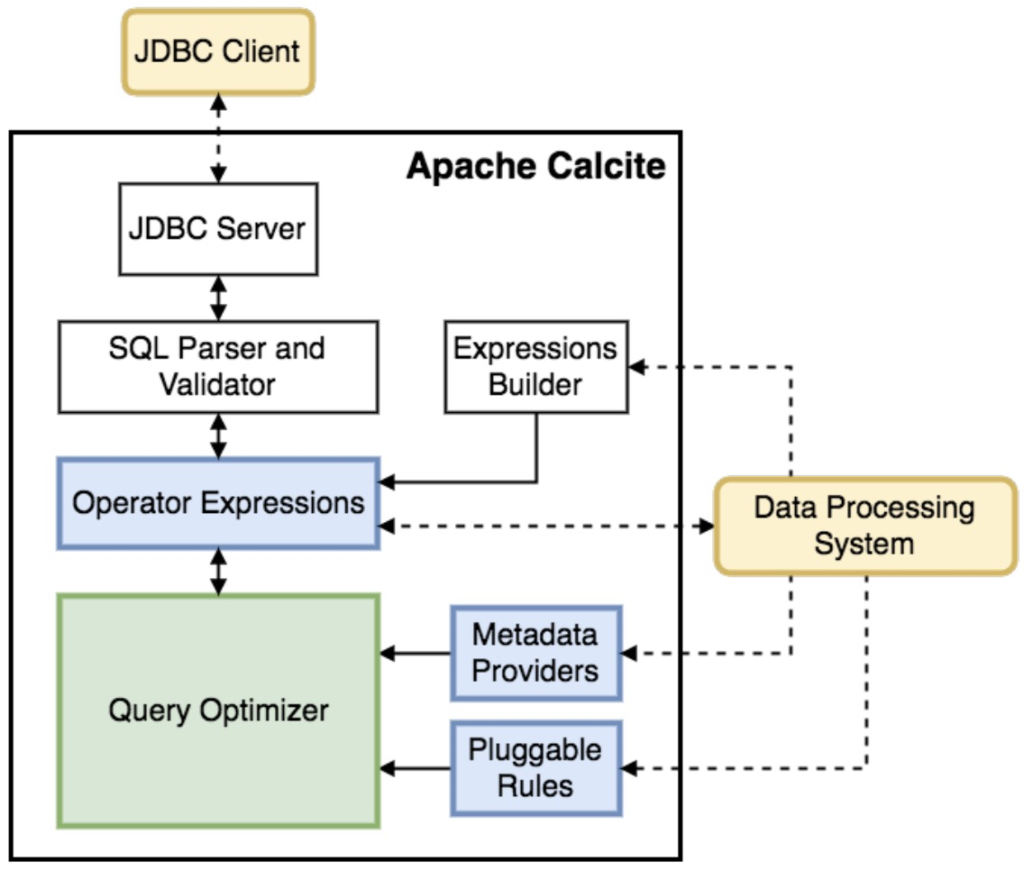
Parser & Validator
Calcite包含一个SQL Parser和Validator,这个模块将SQL解析为a tree of relational operators。因为Calcite不包含存储层,所以解析过程中依赖的schema信息是通过一个adapter层来封装的。
Optimizer
Calcite包含的优化器部分,可以支持本就支持SQL的系统,如果系统SQL比较弱,比如Hive,虽然支持SQL,但是Hive的优化器很弱。Hive把SQL解析成语法树之后,Calcite可以反过来再恢复成SQL语句,然后再优化。也就是说,Calcite可以直接嵌在不含优化器的SQL系统里面。
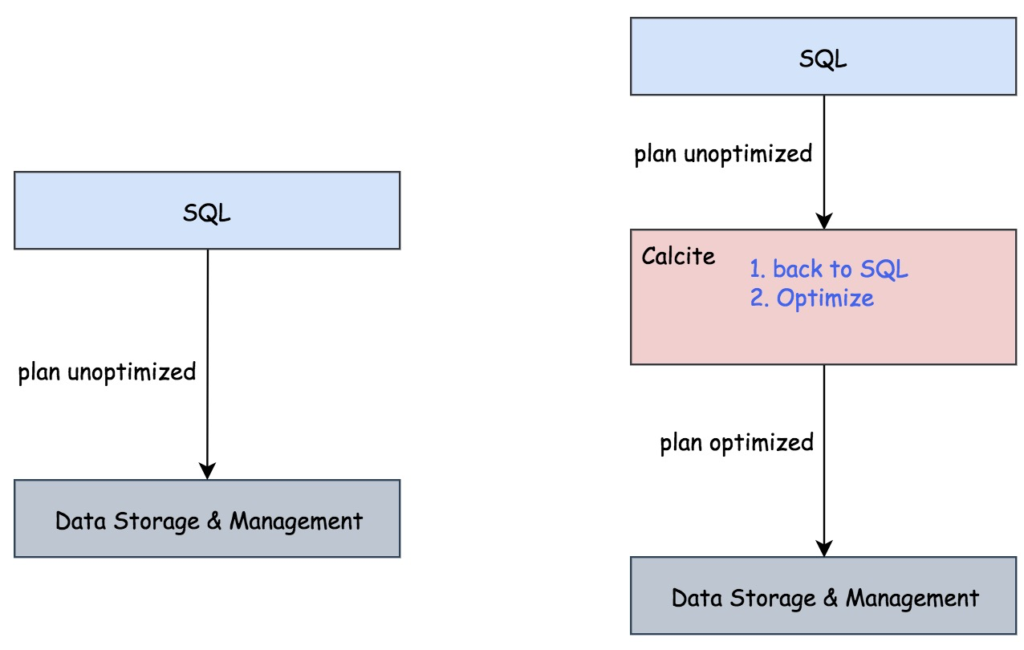
Calcite的优化器也可以对接其他系统的parser,Calcite内置了一个relational expressions builder接口。举个例子:
Apache Pig的某个脚本:
1 | emp = LOAD 'employee_data' AS (deptno, sal); |
等价的表达式为:
1 | final RelNode node = builder |
Query Algebra
关系代数处于Calcite的核心地位。
Operator
除了常见的filter, project, join等operator,Calcite还引入了能表达更复杂操作的operator,例如window。
Traits
有些设计里,逻辑执行计划和物理执行计划是不同的实体。在Calcite中,二者是统一的实体,只是会在这个实体上增加一个traits来描述物理属性。
traits能够让优化器评估多个候选的计划。优化过程中,会先给关系表达式指定一些traits,如果需要换另外一种物理实现,可以实现关系表达式的converter接口来指示如何把traits从一个物理实现的值转化为另外一种物理实现的值。
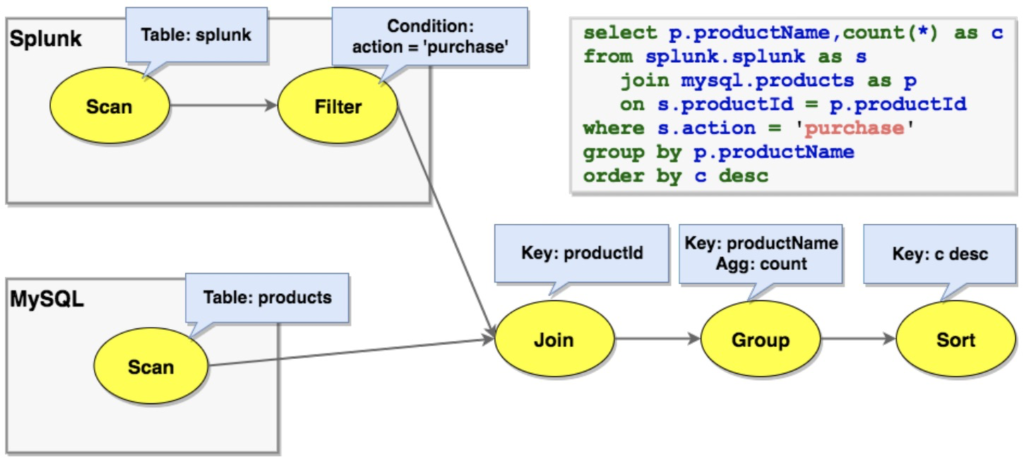
除了ordering, grouping, partitioning这类的traits之外,Calcite中还有一个特殊的traits叫calling convention,它代表了数据源的操作接口,通过这层抽象来实现跨数据源的优化。如下例中,splunk上的scan是按splunk convention,products的scan是按jdbc-mysql convention。如果用Spark来存放splunk表,那么join就会转化成使用spark convention。
Query Processing And Optimization
优化器是Calcite的核心部分,优化器在代价模型指导下,不断地应用优化规则,生成更好的执行计划。优化器的各个组件都是可以扩展的,用户可以添加自己的relational operator, rule, cost model, statistic。
Planner rules
Calcite有几百条优化规则,用户可以在这个基础上添加适用于自己系统的新规则。
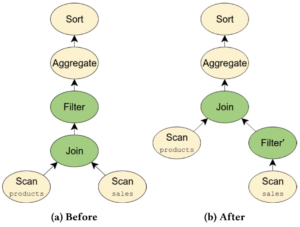
例如如下的查询会使用FilterIntoJoinRule规则优化。
1 | SELECT products.name , COUNT (*) |
Metadata providers
Metatadata给优化器提供信息,例如,Calcite里面默认的metadata provider可以提供诸如子表达式的整体代价、返回的行数和数据量、执行表达式时可能的最大并行度等信息。
用户可以使用Calcite的相关接口来实现自己的metadata provider,提供更多的元数据信息。用户的metadata provider作为java源代码提供出来,Calcite使用一个轻量级的Java编译器Janino编译并实例化新的metadata provider。实现上,Calcite还会缓存Metadata的查询结果。
Planner engine
Calcite有两个planner引擎:cost-based planner engine, exhaustive planner。
cost-based planner engine
跟Volcano算法类似,使用动态规划算法。一开始每个子表达式都对应自己的一个等价集合,子表达式不断应用规则,扩大或者合并等价集合。若要获得全局代价最优的计划,则每个子表达式需要从等价集合中采用各自局部最优的那个计划。
exhaustive planner
不断尝试将所有规则应用到最初的计划上,直到不能再应用任何规则。这个方法不需要代价作为指导。
Materialized views
物化视图是通过预计算来降低整体开销的一种思路。
在Calcite中,后端的数据引擎提供物化视图的能力,优化器可以使用这些物化视图来做rewriting。
具体有两种rewriting算法:view substitution, lattices。
view substitution
将原来操作原始表的关系代数子树替换为使用物化视图的等价子树(scan operator和物化视图定义都注册到planner里面)。
lattices
前提是数据源已经被组织成Cube。Cube是数据分析(比如BI)里面比较常见的概念,它是数据的一种组织方式,本质上类似于关系代数里面讲的范式。
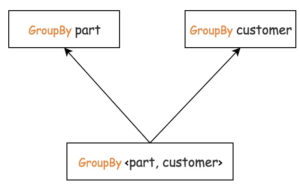
在这种前提下,物化视图可以更好地被利用,比如原始表是每日营业额,有个物化视图是月度营业额,那么查询年度营业额就可以用这个物化视图。这里lattice也还是代数系统里面讲的那个偏序关系,比如已经有了一张表/视图来表示GroupBy <part, customer>,那么GroupBy part和GroupBy customer都可以使用它。如图(我们只关注图的形状,箭头方向的含义是可以取反定义的)。
Extending Calcite
Semi-structured Data
Calcite支持多种复杂的列类型,比如ARRAY, MAP, MULTISET。
以mongodb为例,一个存放了城市邮编信息的文档,可以通过如下方式创建视图来转化为关系表:
1 | SELECT CAST(_MAP['city'] AS varchar(20)) AS city, |
其中,**_MAP** 是Mongodb的adapter提供的数据抽象。
有了这种view over semi-structured data,剩下的就完全是关系表的处理方式了。
Streaming
Calcite扩展了SQL语法来支持流式数据,例如增加了STREAM关键字,思路上主要是要借助窗口这样的概念来完成流式数据向常规表数据的模拟转化。
所谓流,就是源源不断地进来数据。比如Orders是一个流,可以执行如下的查询:
1 | SELECT STREAM rowtime, productId, units |
因为流是源源不断的,所以查询不会不断地输出新的数据。
基于流的这个性质,查询往往需要借助窗口这样的概念来实现特定的查询目的。
1 | SELECT STREAM rowtime, productId, units, SUM(units) |
此外还有其他各种窗口函数,如 Tumbling Window、Hopping Window、Session Window等。
同样,stream-to-stream join也要表达为基于隐式的窗口函数来做join。
Geospatial Queries
Calcite将GIS对象如point, curve, polygon都统一抽象成GEOMETRY类型。Calcite支持Open GIS Simple Feature Access规范。
查询Amsterdam这个城市所在国家的查询大致如下:
1 | SELECT name FROM ( |
Language-Integrated Query for Java
LINQ4J
Industry and Academia Adoption
Embedded Calcite
内嵌了Calcite的系统:
- Drill: Dremel上的查询引擎,数据模型是JSON文档,语言类SQL++
- Hive: MapReduce之上的SQL接口层
- Apache Solr: 全文索引分布式查询引擎,架在Lucene之上,JSON API,借助Calcite提供SQL接口
- Apache Phoenix和Apache Kylin: HBase之上的一个查询层
- 其他: Apex, Flink, Samza, Storm
地球上的数据系统可真不少……
Calcite Adapters
Cassandra, Pig, Spark, Druid, Elasticsearch, JDBC, Mongodb, Splunk等。
扫描二维码,分享此文章