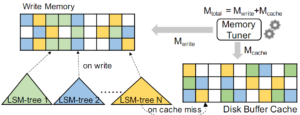
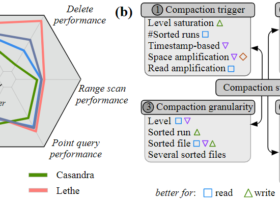
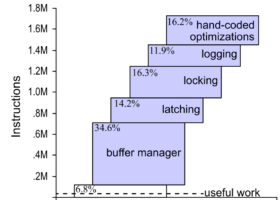
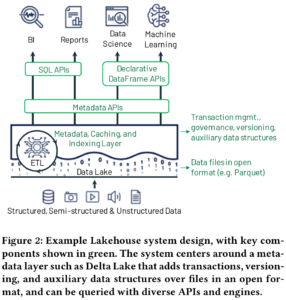
互斥锁 ib_mutex_t
typedef FutexMutex ib_mutex_t;
UT_MUTEX_TYPE(TTASFutexMutex, GenericPolicy, FutexMutex); 这个宏定义展开是
typedef PolicyMutex<TTASFutexMutex<GenericPolicy>> FutexMutex;
PolicyMutex是个mutex框架,具体实现依赖模板参数MutexImpl。
1234567891011121314151617
templat...