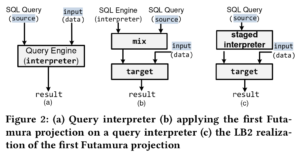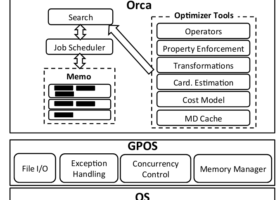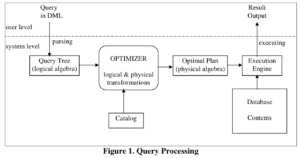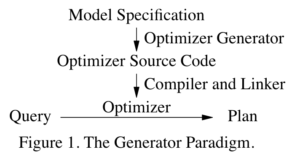
《The Snowflake Elastic Data Warehouse》 SIGMOD 16'
Snowflake具备如下的特点:
纯粹的SaaS体验:用户将数据放到云上,然后可以通过snowflake对他们的数据进行查询。
关系型:支持SQL和ACID
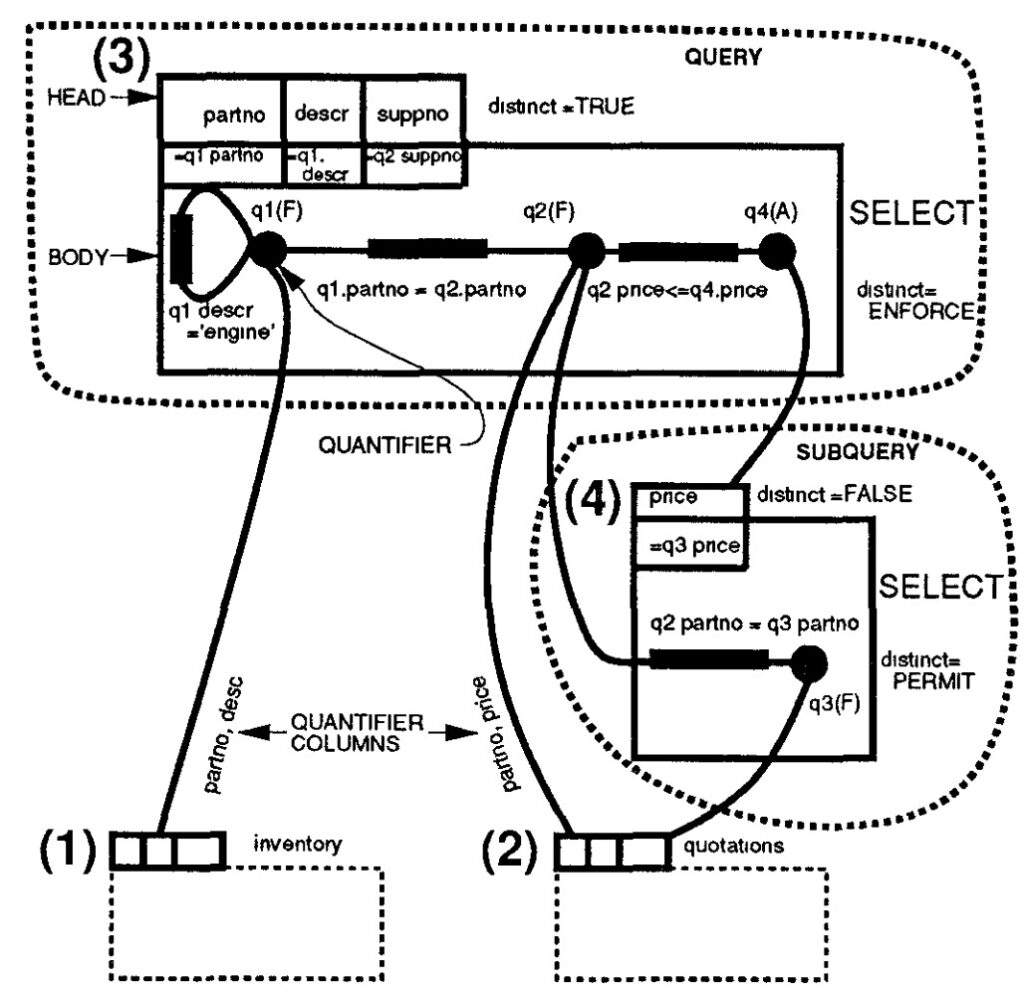
办结构化:内置函数和SQL扩展来支持对半结构化数据的访问,自动schema discovery和列式存储
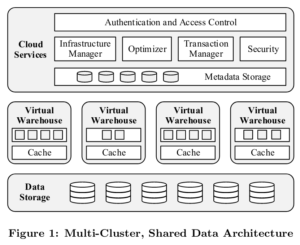
弹性:存储和计算资源可以独立无缝弹性,不影响数据可用性和当前查询性能
高可用:容忍node、cluster和data cent宕机...