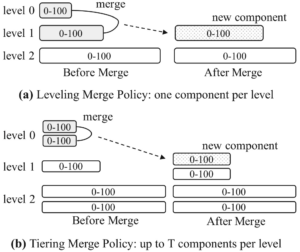
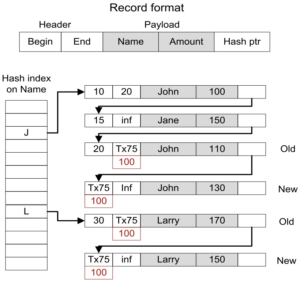
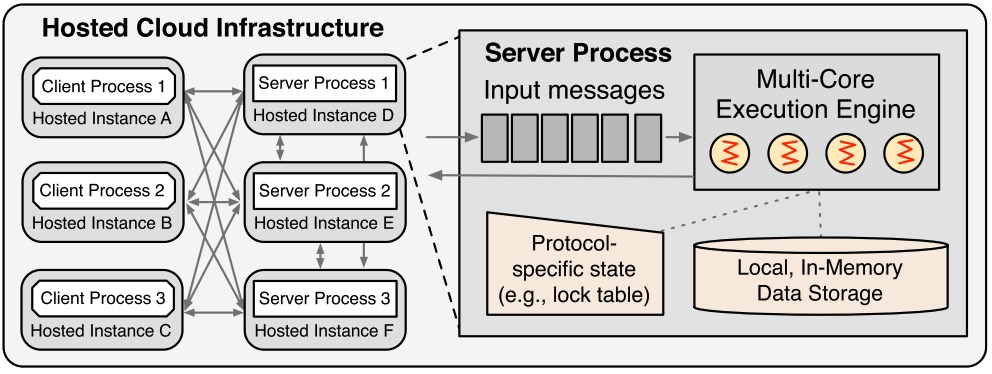
Aurora在SIGMOD18'的论文《Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes》中描述了Aurora关于共识方案的选择和Quorum方案的详细内容,本文这里做一些简单的分析。
Aurora架构背景
在描述Aurora的Quorum方案前,先介绍下Aurora的系统架构。
Aurora是share-storage、一写多读的架构,构建在MySQL(InnoDB)代码库上,当然后来增加了mult...