Databricks Lakehouse
《Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics》 CIDR21'
整片文章讲的比较宽泛。
Introduction
第一代数仓:结构化数据,用于决策支持和BI。
第二代数仓:解决存储和计算资源耦合、无弹性、非结构化数据激增等问题,采用了data lakes方案,采用开放格式,数据存储到分布式文件系统,主要代表是Hadoop运动。
第三代数仓,2015年之后,云数仓架构,如S3替代了Hadoop,代表为Redshift和Snowflake。
第三代数仓的主要问题:
- reliability:为了支持data lake和warehouse一致性,需要持续地在二者之间进行ETL,整个链路变复杂,更容易引发质量和性能问题。
- data staleness:warehouse中的数据一般比data lake陈旧,因为新数据可能要花费几天才能完成数据导入或加载。据报道,86%的分析数据是陈旧的,62%的报告经常要等待资源。
- limited support for advanced analystics:用户可能会问一些预测型的问题,比如应该给哪些用户打折?现在机器学习的系统如TensorFlow、PyTorch、XGBoost都不能在数仓上运行良好。这类系统通常不是SQL接口,走JDBC/ODBC接口会很低效,但现在数仓系统也没有直接访问底层数据的能力,只能再加一步ETL。
- total cost of ownership:持续ETL的成本、数据冗余成本、商业数仓数据迁出成本等。
Lakehouse可以解决如下的问题:
- data lake上可靠数据管理:支持原始数据存储,这一点和data lake相同;同时也支持warehouse的ETL/ELT过程来提高数据质量;数据管理支持事务、回滚、零拷贝克隆等。
- 支持机器学习和数据科学类应用:机器学习系统可以直接读取文件,这一点比较适宜lakehouse,另外有些机器学习系统采用了DataFrame抽象层并使用声明式API,这类系统可以从lakehouse的优化器收益。
- 超高的SQL性能:数仓往往在数据格式等方面有很大的自由度,但lakehouse要在大规模的Parquet/ORC数据集上提供足够高的SQL性能,即便如此lakehouse仍然有优化空间,比如增加辅助数据、有限度地调整数据排布。
Motivation
- 首要问题是企业数据用户对数据质量和可靠性要求比较高,湖仓分离的两层架构以来各种数据流水线容易带来问题。
- 商业应用要求更加实时的数据,但ETL等方式往往耗时比较长。
- 现在大量数据都是非结构化的,如图片、视频等,数仓的SQL API对其支持有限。
- 很多用户要部署机器学习和数据科学应用,数仓对这类应用支持很少。
Lakehouse Architecture
lakehouse的定义特征:低成本;直接存取存储;支持传统分析型DBMS特点,如ACID、数据多版本、审计、索引、缓存、查询优化。
lakehouse集合了数据湖data lake的低成本和开放存储优点,以及数据仓库warehouse的强大管理能力和优化能力的优点。难点也在于此:如何高效结合二者的优点。
Implementint a lakehouse system
首先,数据存储在低成本对象存储上,采用标准开放格式(如Apache Parquet);其上实现一个事务型元数据层,用于定义对象和表的关系。这样可以兼得数据存储的低成本和数据的事务级管理。
其次,lakehouse不能修改文件格式,但可以在保持数据文件不修改的前提下,实现cache、辅助数据结构如索引统计、数据排布优化等。
最后,lakehouse既可以加速复杂的AP查询,也可以借助declarative DataFrame API来实现更宽泛的数据管理能力。例如TensorFlow和Spark MLlib可以读取data lake的一些文件格式。
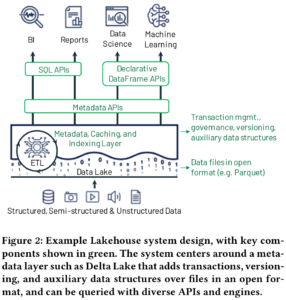
Metadata Layer
元数据层是将S3上的对象存储文件抽象成ACID事务可操作的表对象重要一步。Databricks的Delta Lake、Apache Iceberg、Apache Hudi都是类似功能的组件。
这类组件在实现事务、零拷贝、time travel等管理功能的同时,达到的性能与直接操作原始Parquet等数据的性能相近甚至超越。
元数据层很适合做data quanlity enforcement。比如Delta Lake可以对数据上传到表时做schema检查等。
元数据层很适合做governance。
遗留问题:Delta Lake使用的transaction log(将数据改为支持事务的机制)和数据本身存在同一个存储单元上,好处是二者集中管理,坏处是存储访问延迟高导致TPS低。还有不支持跨表事务。
Lakehouse中的SQL性能
提升性能的几个方法:Caching、Auxiliary Data、Data Layout。
Caching:缓存到计算节点的SSD和RAM中。
Auxiliary Data:文件内部的column min-max统计信息以支持data skipping、Bloom Filter。
Data Layout:改善数据布局对性能提升很明显。Z-order、Hilbert curves。
遗留问题:定义新的格式、更好的缓存策略、更好的辅助数据结果、更好的数据布局;serverless。
Efficient Access for Advanced Analytics
高级分析查询通常用命令式语言编写成库,不能用SQL接口执行。Databricks采用了DataFrame API,兼容Pandas库,适配Apache Spark生态(MLlib、GraphFrames、SparkR)。
遗留问题:较新的"factorized ML" framework将ML逻辑嵌入到SQL join中,这里有一些事情可以做。
Research Questions and Implications
Are there other ways to achieve the Lakehouse goals?
What are the right storage formats and access APIs?
How does the Lakehouse affect other data management research and trends?
略。