Dynamo论文阅读笔记
Dynamo: Amazon’s Highly Available Key-value Store
Dynamo这篇论文是2007年出来的,以前读研究生的时候读过,前两天看了一篇NoSQL综述提到了这篇论文,今天重读一遍,简单做些笔记,里面有些东西还只是简单看了下不够深入。
Dynamo系统本身并没有提出新的技术,但是将各种分布式技术融合在一起,构建了一个高性能高可用高可扩展的key-value存储。Dynamo牺牲了强一致性,使用vector clock等方法把数据冲突放在了客户端解决。
Dynamo在Amazon主要用于购物车之类的场景,其需求假设:只需要支持简单的按照key进行读写;不要求强一致性。
System Design
Dynamo的设计特点:增量可扩展(可以一次增加一台机器);节点对称;系统去中心化;异构。
表1是Dynamo用到的技术。
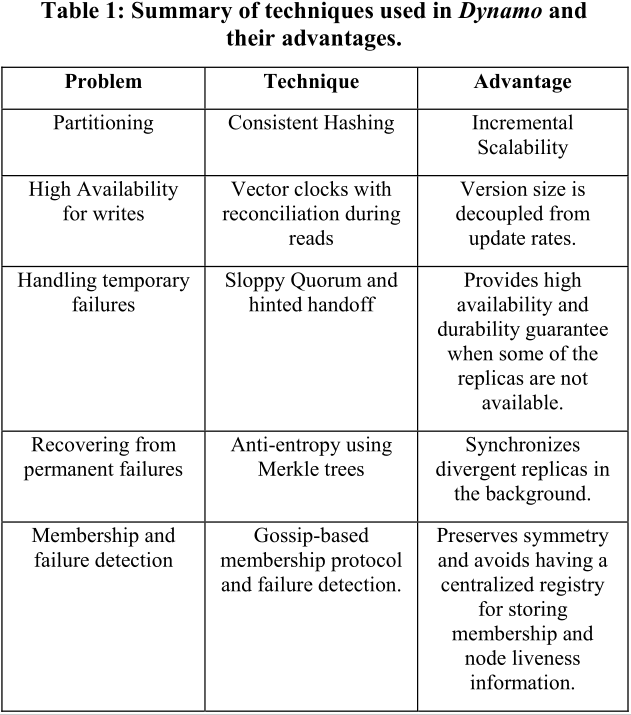
我们逐个看下。
Partition
Dynamo用的是一致性哈希consistent hashing方式来对数据进行分区。
简单的hash分区方式,比如根据hash(key)%N来确定一个key应该落在N个节点中的某个节点,这种方式的扩展性有着比较大的问题。当增删一个节点时,绝大部分数据都需要重新移动。
一致性哈希是将hash range视为一个环,每个节点都被分配一个随机的值,一个数据项先根据key计算hash值,然后在环上顺时针找第一个大于数据key hash的节点,也就是说每个节点都负责服务环上该节点的前驱节点到该节点之间的hash range的key。如图示。
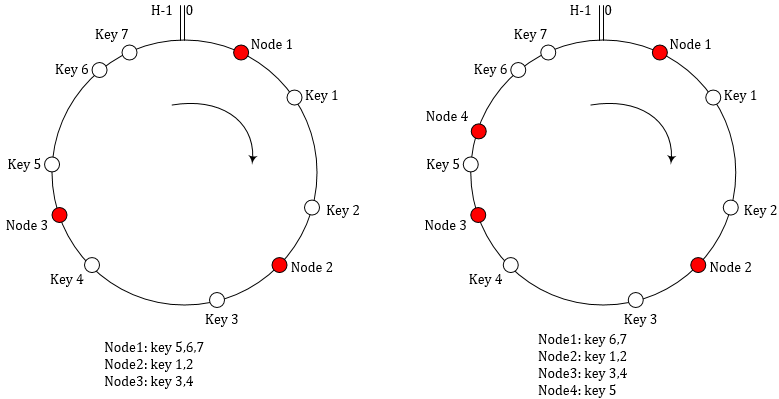
当新增一个Node 4时,不需要移动所有元素,只需要将Node 1上的一些key转移到Node 4上。平均移动数量只有1/N。
这种一致性哈希也有一些问题。首先,节点被分配一个随机的值,可能导致每个节点的负载不均衡。另外,节点可能是异构的机器,不同节点的硬件服务能力并不相同。Dynamo使用了一致性哈希的一个变体方案来减缓这两个问题:每个物理节点都虚拟成若干个虚拟节点,将虚拟节点分配到hash range环上。这个方案的好处是:如果一个节点宕机或者网络断了,其上的负载可以均匀地分散到其他节点上,而不只是给相邻节点带来压力;重新上线的机器也可以从多个已有节点上分担负载;一个物理节点可以根据其硬件性能灵活配置对应虚拟节点个数。
Replication
Dynamo将数据复制N份来提高可用性。首先按照上一节描述的一致性哈希方式将一个key分配到一个节点,该节点负责将这个key复制到环上顺时针下的N-1个节点,相当于每个节点都承担从本节点往前N个节点到本节点之间的hash range,也就是说一个key会被N个虚拟节点服务。考虑到有可能这N个虚拟节点实际上是少于N个物理节点(一台物理节点重复存放没有意义),需要特殊处理一下,如果发现虚拟节点对应的物理节点已经存放了这个key就顺序看下一个虚拟节点。
Data Versioning
Dynamo提供最终一致性,在更新一部分replica之后就可以返回客户端更新成功,系统将更新传播到所有副本。如果有节点宕机,就有可能导致同一个key在各个节点上数据不一致。
Dynamo将数据修改视为数据的一个新版本,系统在某个时刻可能有同一个key的多个版本的数据存在。大部分情况下,旧版本的数据会被新版本的数据覆盖掉,所以多版本也不会造成客户端看到陈旧的数据。但是,当出现宕机和网络分区等情况时,可能出现数据版本分叉的情况,这种情况系统本身无法决定哪个数据版本是新的哪个是旧的。
Dynamo使用vector clock来标注一个数据的版本。vector clock是指一组(node, counter),表示这个版本是哪个节点在该节点的哪个逻辑时钟时刻生成的。Dynamo在写数据时要指定版本,这个版本通常先通过之前的读操作获取。如果读取时发现有并发版本冲突(无法确定哪个版本在前哪个在后),就需要将有冲突的数据及其版本都返回客户端,客户端在写之前,需要自行reconcile这个数据,然后再写入新的数据,如图示。
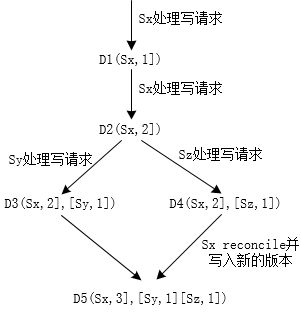
get/put执行过程
Dynamo使用HTTP方式访问。一个请求选择节点时,要么借助load balancer来路由,要么借助partition-aware的客户端库来直接选择这个key所在的N个节点中的一个(这里称作coordinator,通常选环上第一个)。当然,后者会节省不必要的请求路由带来的网络延迟开销,代价是需要链接一个库。
Dynamo使用NRW quorum方式来实现副本之间的一致性。N个副本,写操作至少写W个才返回成功,读操作至少读R个才返回成功,要求R+W>N,这样至少有一个副本上能读到最新的数据。
put执行时,coordinator先生成新版本vector clock并写入本地,然后coordinator将新版本数据和新的vector clock发给其余的所有副本,当其中至少W-1个副本回应写成功之后,则返回客户端写操作成功。
get执行时,coordinator向N个副本请求各自最新的数据,至少读到R个数据后,系统尝试自行根据因果序解决冲突(这时某些副本上的旧数据可以被覆盖成新的),如果解决不了则返回客户端未解决冲突的数据,由客户端来解决冲突。
Handling Failures: Hinted Handoff
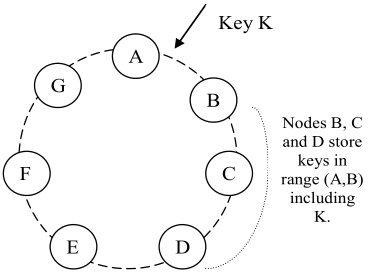
hinted handoff是为了解决临时的failure。如图中,假设A短时间不可用,则请求路由到D,并且会告诉D这些请求是要求D临时代替A存储。D会把数据存到磁盘上独立的地方,当D检测到A恢复后,将这些数据再送还给A。
Handling permanent failures: Replica synchronization
Dynamo使用anti-entropy协议来保持副本之间的同步。为了快速检测副本不一致、减少需要传输的数据量,Dynamo使用了Merkel Tree。Merkle Tree的叶子是各个key的哈希值,树中父节点的哈希值是从其所有子节点的哈希值计算得来。如果两份数据对应的Merkle Tree的根节点哈希值相等,说明数据一致,否则递归看子节点。Dynamo每个节点为它承担的若干个key ranges(一个虚拟节点对应一个key range)中的每一个range都维护一个单独的Merkle Tree。
Membership and Failure Detection
管理员可以通过命令增删一个节点。
每个节点都在本地磁盘上维护集群中所有虚拟/物理节点及各自承担range这一映射关系。当一个节点第一次启动时,它先设置好自己的虚拟节点,本地维护的映射关系暂时就只包含自己。节点之间通过gossip协议传播成员变化并更新本地的映射关系,因此每一个节点都能得知其他所有节点的信息,因而就可以转发请求到正确的节点上。
这种去中心化的维护方式在逻辑分裂场景下会有问题。比如先后添加AB两个节点,AB各自都认为自己是环上的一员,但是不能立刻得知对方也在环上。可以对去中心化做些妥协,选择一个节点作为种子节点,所有节点最终都要和种子节点reconcile membership。