《LB+Trees: Optimizing Persistent Index Performance on 3DXPoint Memory》(VLDB20’)
这是个设计非常巧妙的数据结构,这里简单描述下核心内容,读者可以直接读原文,行文非常清晰。
Abstract
3DXPoint的有些硬件特性,跟常规NVM差不多:
- 3DXPoint的访存粒度是64字节Cache Line
- 3DXPoint比DRAM慢2倍,比SSD快几个数量级
- 3DXPoint的写比读慢
- 使用clwb/sfence等特殊指令将数据从CPU Cache持久化到3DXPoint会导致一个数量级的降低
3DXPoint的一些独有的特性:
- 一个cache line里面写一个word还是多个word不影响写性能,但写多个line比写一个line性能差。
- 3DXPoint内部数据带宽是256字节
- 访存局部性:访问数据多的时候,性能会下降,3DXPoint内部应该还有一层自己的cache。
LB+Tree的三个性能提升方法:
- Entry Moving:尽量让节点的第一个cache line空出来。
- Logless node split:使用NAW原子写来实现logless的节点分裂
- Distributed headers:对于multi-256B的节点,传统方式是将header放到整个节点的头部,LB+tree是将header分散到每个256B block上。
Background
安装
两种安装3DXPoint的方式
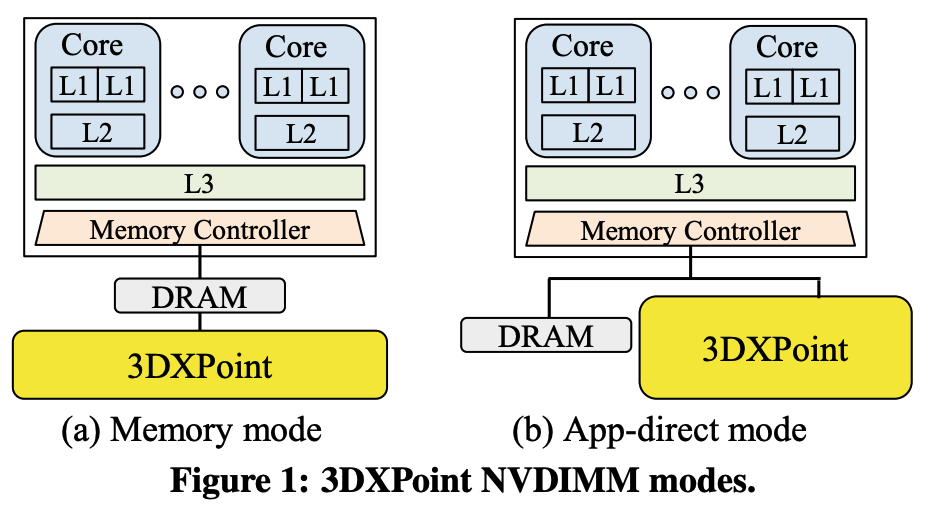
Memory Mode:将DRAM视为3DXPoint的缓存。好处是应用不需要修改,坏处是DRAM不支持持久化,再就是从3DXPoint load数据慢,
App-direct Mode:在3DXPoint上安装文件系统,使用PMDK将3DXPoint的文件mmap到进程虚拟地址空间,OS访问3DXPoint要绕过page cache。
指令
persist op = clwb + sfence
clwb: Cache Line Write Back 将cache line数据写回内存。
sfence: store fence,此指令前的所有store指令对其他CPU可见。
持久化
四种持久化的模式:
- logging:WAL,记录<地址、旧值、新值>
- shadowing:COW方式
- PMwCAS:多字的CAS指令
- NVM atomic writes(NAW)
NAW
8字节刷NVM是原子的。
NAW SECTION
是指代码段(类似于critical section),如果本次写请求只涉及一个used line和多个空闲line,那么先在空闲line操作,然后执行一组clwb和一个sfence来持久化used line。
这样的操作是可以保证原子的,这个结论称为NAW SECTION PERSISTENCE。
如果是多个状态D1,D2…Dk要改,基本上就是类似于2PC的方式。D1上用一个比特ongoing表示多个状态切换是否完成,然后D2..Dk需要将各自的状态切为可提交可回滚的状态,然后用NAW改掉ongoing比特。
已有的NVM上B+树优化
几个优化思路:
- 内存B+树需要注意cache friendly
- 叶子节点上key可以乱序,使用bitmap来指示空槽,乱序可以减少数据移动
- 叶节点里面key乱序,但提供一个有序的间接数组来支持二分查找
- 非叶子节点存放在DRAM上
3DXPoint上程序设计原则
- 降低写的line数目,而不是降低写的line内word数目
- 节点大小设为256字节的倍数
- 避免使用log,用NAW
LB+Tree设计
结构:
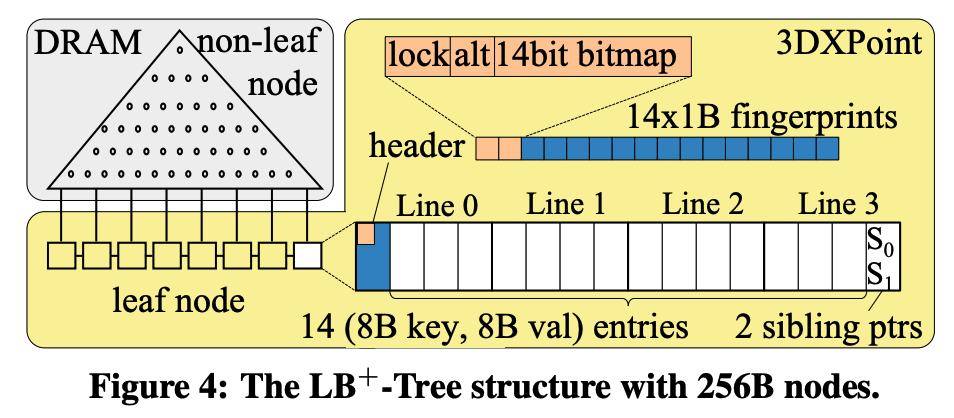
LB+Tree使用了HTM,HTM事务内不能使用clwb之类的指令,因为HTM靠缓存本地CPU修改来实现原子性。LB+Tree用lock比特来解决这个问题。
Search

Delete
不涉及node分裂合并。只改bitmap即可。所以只用一个NAW就能实现。
降低insert开销
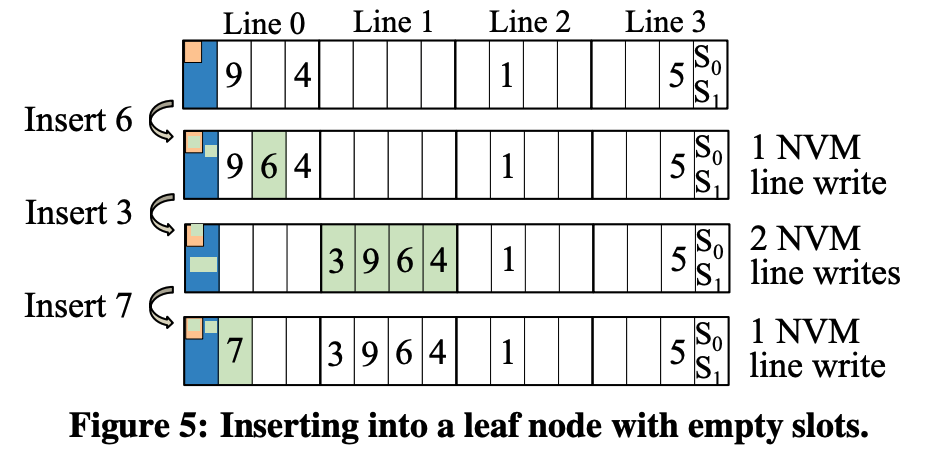
基于 ‘一个cache line里面写一个word还是多个word不影响写性能,但写多个line比写一个line性能差’ 的特性,因为每次插入必须要改header,所以尽量将新key插入line 0。如图5,insert 3的时候,将line 0腾出来。
logless节点分裂
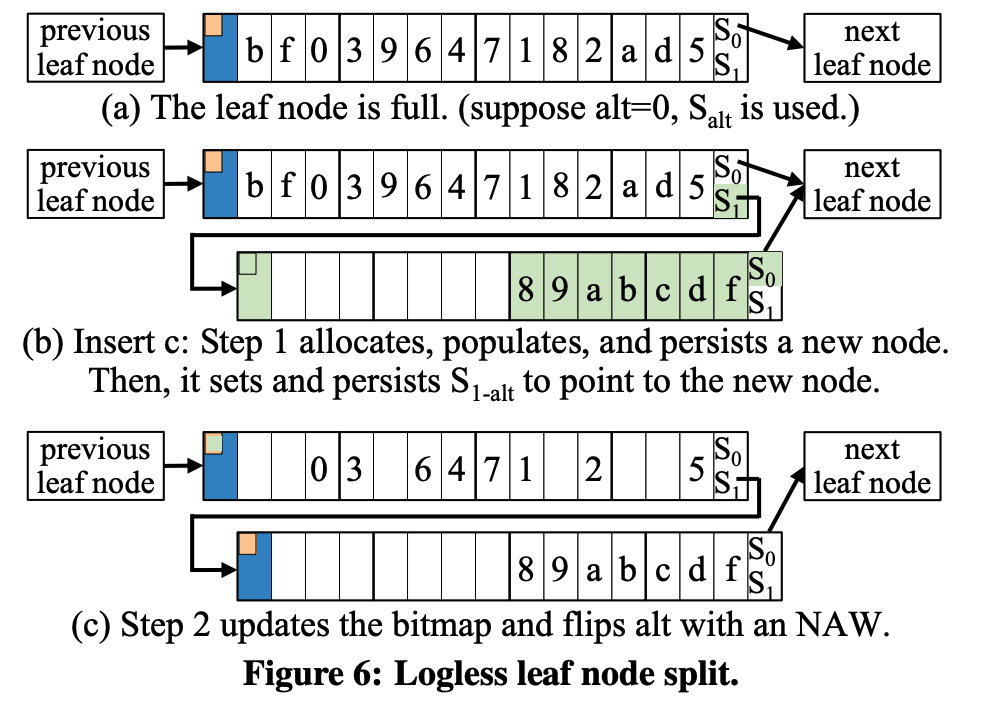
Multi-256B节点
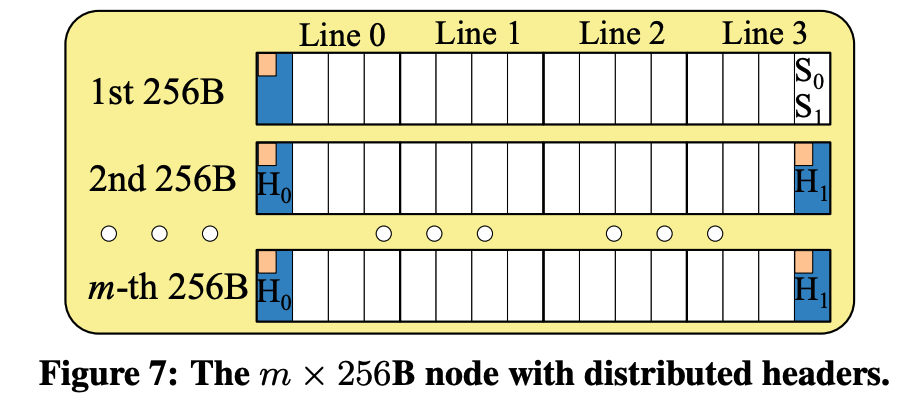
alt除了指示S0/S1,同时还指示了2~m的H0/H1,这m-1个H0/H1的切换是一体切换的。
扫描二维码,分享此文章