《Constructing and Analyzing the LSM Compaction Design Space》 VLDB’21
四个原语
Compaction是LSM-Tree引擎中最重要的环节之一,一方面它主导了LSM-Tree的形状进而影响了LSM-Tree的包括性能、空间占用等对外表现,另一方面它本身要消耗相当的计算和IO资源,容易造成抖动等问题。
但目前业界针对compaction较少有系统的探索,很多系统的compaction策略依赖工程师的个人经验,大量可能的策略未被分析测试。
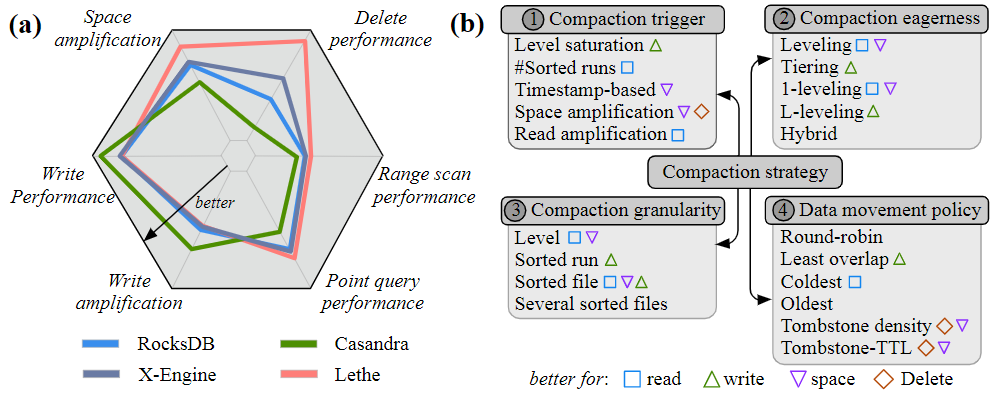
这篇论文旨在构造和分析compaction的design space,力求有一个较为系统的分析。
论文首先识别出了四个原语(primitive),然后据此构建了design space:
- Compaction trigger:什么时候触发
- Data layout:数据的物理存放方式是怎样的
- Compaction granularity:每次移动多少数据量
- Data movement policy:具体移动哪些data block
四个维度下的各自具体例子:
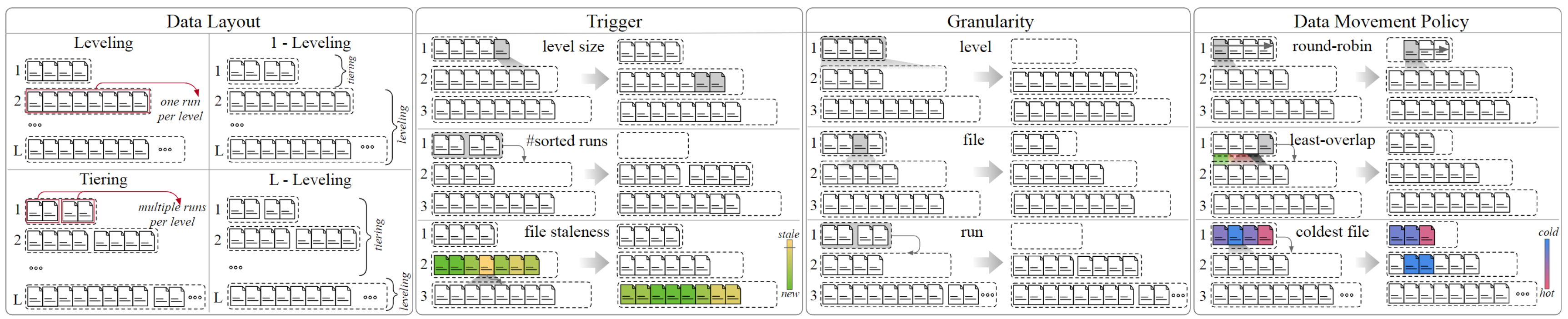
详细一点地说,
Compaction trigger
- Level saturation :level size超过阈值
- #Sorted runs :level内的sort run数量超过阈值
- File staleness :level内文件存在时间超过阈值
- Space amplification (SA) : 写放大超过阈值
- Tombstone-TTL :文件内含有过期的TTL
Data layout
- Leveling :每个level只有一个sort run
- Tiering:每个level有多个sort run
- 1-leveling:L1是tiering,其他level是leveling
- L-leveling:last level是leveling,其他是tiering
- Hybrid:每层都可能是tiering或者leveling
Compaction granularity
- level:相邻两层的所有数据
- sorted runs :level内的所有sort run
- sorted file : 每次compact一个sort run
- serveral sorted files:每次若干个sorted files
Data movement policy (aka file picking policy)
- Round-robin
- Least overlapping parent
- Least overlapping grandparent
- Coldest
- Oldest
- Tombstone density
- Tombstone TTL
Design Space
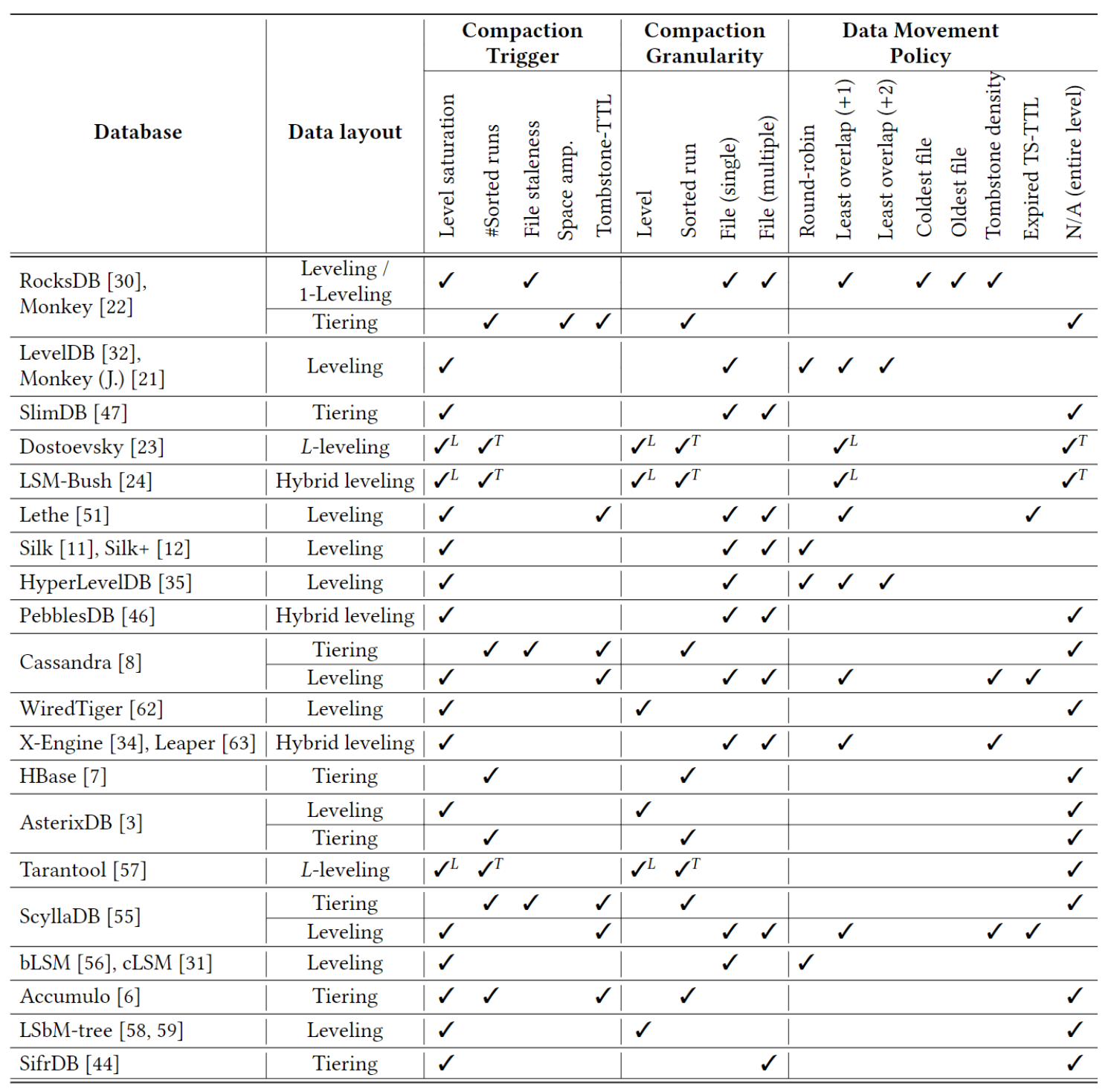
估算下来,space的cardinality有10^4之多。一些典型的例子如图。
测试和分析
关注的性能指标
- Compaction latency
- Write Amplification
- Write Latency
- Read Amplification
- Point lookup latency
- Range Lookup Latency
- Space Amplification
- Delete Performance
实验目标
- compaction对性能的影响
- workload对compaction的影响
- compaction和tuning的互相影响
测试分析结果
O for observation, TA for key takeaway.
Data Loading测试:
O1 :compaction带来大量的data move。
O2 :partial compaction降低了data move但带来了更多的compaction count。
TA I : compaction的粒度越大,则compaction次数越少,但总的data move量越大。
O3 :full compaction的平均compaction延迟最高,tiering的长尾延迟最高。
TA II :tiering可能导致比较长的write stall。
Querying the data
O4:point lookup在tiering下延迟最高,full level下最低。
TA III :point lookup延迟很大程度上不收data movement policy影响。
O5 :read amplification受Block Cache和文件结构影响比较大,tiering下最高。
O6: 混合负载有更高的长尾延迟
在compaction过程中同时施加point query,写的长尾延迟会变大,论文给出的原因一是点查需要访问磁盘IO读取index block造成IO写饱和,二是查找过程中会memtable的flush会延迟[?]
但在compcation过程中触发查找有助于warmup block cache。
TA IV: Compactions help lookups by warming up the caches. ?
O7: Insert Distribution Influences Point Queries.
TA V:For skewed ingestion/lookups, all compaction strategies be-have similarly in terms of lookup performance.
O8: For Higher Update Ratio Compaction Latency for Tier-ing Drops;LO+2Dominates the Leveling Strategies.
TA VI:Tiering dominates the performance for update-intensiveworkloads.
O9: Optimizing for Deletes Comes at a (Write) Cost.
O10:TierScales Poorly Compared to Leveled and HybridStrategies.
O11: For Smaller Entry Size, Leveling Compactions are MoreExpensive.
O12: Compactions with Tiering Scale Better with Buffer Size.
论文给出的一些compaction建议
- 熟悉你的系统的lsm compaction,不要当成黑盒,要有所作为
- 避免worst choice
- 最好能够适应workload
- 探索新的compaction策略
总结
首先,论文所做的测试结果和分析的价值
测试结果可能并不能真正反映compaction策略对整体性能的差异。
- 测试环境测试case等都很难做到非常全面,比如BlockCache大小等等各种参数设置
- 就某个测试结果来说,具体分析compaction是如何影响整体性能,找到根因也并不简单,可能会产生一些不见得正确的结论。
- 就某个compaction策略来说,方案设计和具体代码实现甚至可能是两码事。
其次,compaction本身及compaction的影响,除了上述四个原语包含的维度,可能还有数据复用程度等方面可以深入考察。
最后,尽管论文并没有很好地解决compaction的问题(事实上这个问题应该也很难解决好),但论文解决黑盒的、策略性的问题的思路是非常值得学习并应用的。
扫描二维码,分享此文章