LSM-based storage techniques: a survey (VLDBJ 2020)
This paper aims to serve as a guide to the state of the art in LSM-based storage techniques for researchers, practitioners, and users.
LSMTree引擎在业界已经有了很多的落地。很多NoSQL系统如Bigtable、Dynamo、HBase、Cassandra、LevelDB、RocksDB、AsterixDB底层都是LSMTree引擎。RocksDB在Facebook的实时数据处理、图处理、流式处理、OLTP等场景都有应用。阿里云RDS中,用户也可以选择InnoDB或者是X-Engine,其中X-Engine就是优化后的LSMTree引擎,高压缩省成本。
LSM-tree basics
Today’s LSM-tree
LSM Tree基础
LSMTree的结构大家可能都已经比较熟悉了,这里再简单描述下。
LSM包含一个active memtable,请求将数据(记录的后镜像)写入顺序的wal持久化,并将数据写入active memtable,active memtable是一个内存索引结构,可以用skiplist或者B+树,当active memtable写到一定大小(或者其他条件)时,将active memtable切换成immutable memtable,并生成新的active memtable,immutable memtable将来刷到磁盘,生成磁盘索引结构,可以是sstable(sorted string table)或者磁盘B+树。磁盘上允许有多层sstable。每层结构(包括memtable)在这里都叫做一个component,点查询只需要从新到旧逐个查即可,范围查询则要同时查找所有的component,使用一个优先级队列做reconciliation。随着磁盘上的component越来越多,查询性能会越来越差,磁盘浪费也会越来越严重(因为删除是标记删除,空间并没有回收),所以需要引入merge来将多个component合并成少量的component。
Merge有两个典型的策略:Leveling Merge Policy和 Tiering Merge Policy。
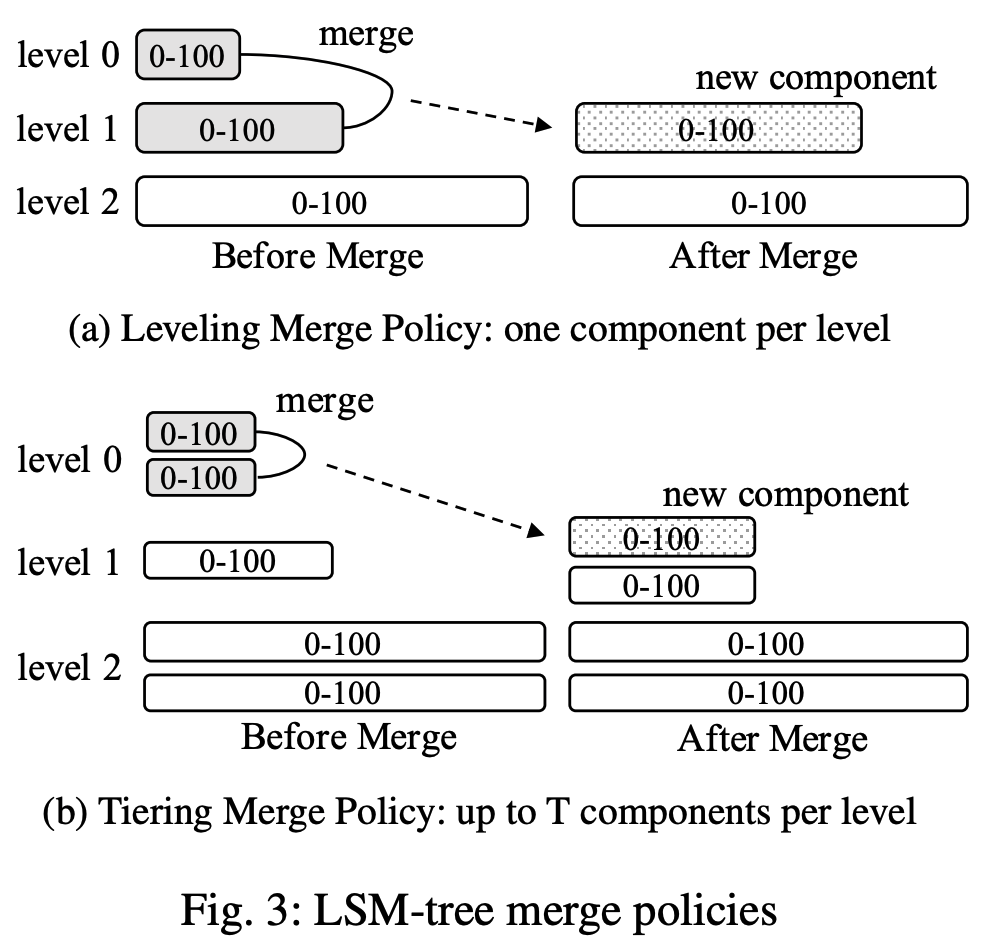
- Leveling Merge:每层维护一个component,层之间数据量比例为T。
- Tiering Merge:每层维护最多T个component,满T个就整体合并成下一层的一个component。
两个merge policy粗略地相比,leveling merge policy维护了更少的层,因此查询性能好,tiering merge policy减少了merge的频率。
一些经典的优化手段
优化一:Bloom filter
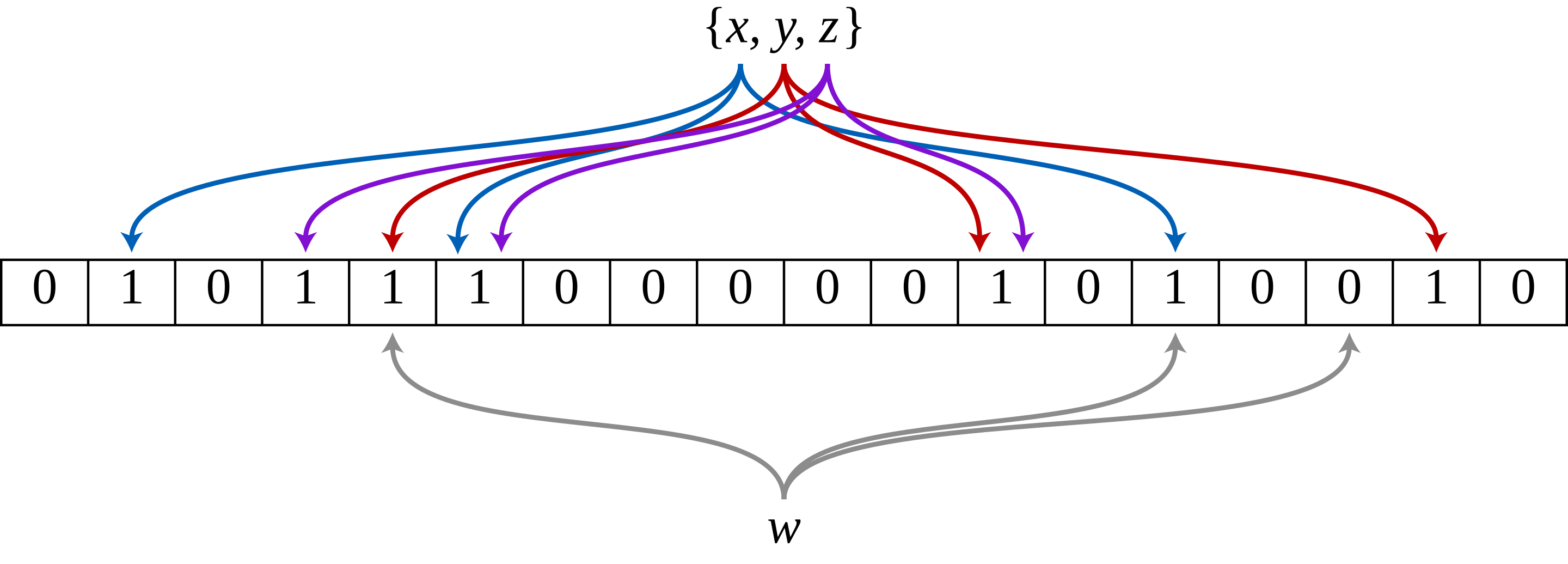
Bloom filter是个非常经典的优化。
从数据结构上讲,bloom filter支持插入一个元素和查询存在性,为了优化性能占用,bf维护一个bit vector,插入一个元素x时,使用若干hash function将x映射到多个bit位,然后置位。查询元素w的存在性时,同样检查w对应的若干bit位,判定是否全为1。bloom filter存在false positive,即实际不存在,但判定为存在。但bloom filter的false positive rate可以足够低,代价是要多一些存储空间,计算公式为: ,其中k是hash function个数,n是元素的个数,m是比特位数目,k取 时,false positive rate最优。
应用bloom filter时,bloom filter可以常驻内存,它对点查询的优化非常显著,因为能够显著降低不必要的IO次数。
优化二:Partitioning
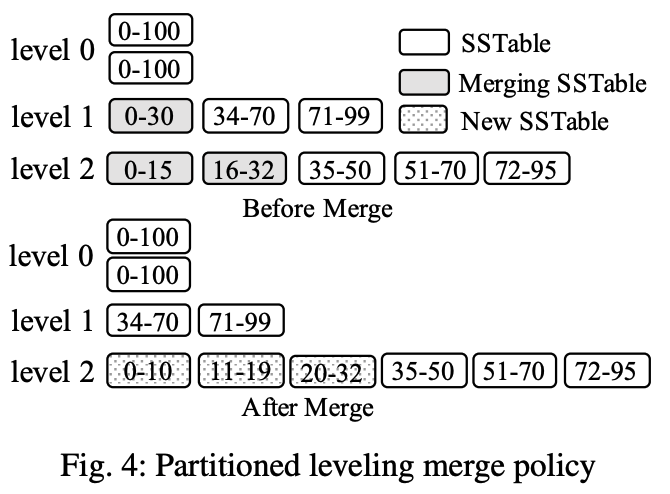
Partition也是非常有效的优化。Partition的基本原理是将每层的component按照range划分成多个分区。
这样带来的好处很多:
- merge操作可以打散成多个小的merge操作。更精细的merge能够使merge的耗时和临时空间占用更加可控。
- 对于顺序插入(每次都是插入更大的key,例如业务存储按时间排序类型的数据)和skewed update的情况,有可能大部分分区不需要merge,只需要merge少量的分区。
注意到,partition优化和merge policy是正交的,但是工业界基本上只有leveling merge policy用了partition优化。
并发控制和recovery
并发控制部分主要涉及两方面,一个是事务多版本,一个是flush和merge的并发。
事务多版本可以参考本博客的其他博文,flush和merge的并发因为要涉及修改component元数据信息,需要谨慎地处理任务间同步。
Recovery简单地说包括两部分,一个是磁盘上的sst component恢复,主要是sst的元数据部分恢复,另一个是事务wal恢复。
sst元数据恢复本质上看元数据的管理方式,通常partitioned的LSM都维护了元数据的变更历史manifest log,恢复manifest log即可。
wal的恢复也比较简单,将wal数据写入memtable即可,因为LSM通常不维护undo,当然这就要求flush下去的数据必须是已经结束的事务。这个设计对大事务不利,因为大事务执行过程中可能要写超过memtable大小的数据量,但业界也已经有了比较好的解决方案。
Cost Analysis
这里只考虑未partition优化的LSM-Tree,几个参数及含义如下:
- T:size ratio
- L:总的层数
- B:每个page里的行数
- P:memory component的page数目
假设workload的insert和delete相当,长时间运行时仍维持L层数据量。
则memory component的行数为$B\cdot P$,第i层行数$T^{i+1}\cdot B\cdot P$ 。设总共$N$行,则最后一层的数据量为$N\cdot\frac{T}{T+1}$(这个是大致数值,按说要按等比数列推算,这里是依据层间数据比率算的粗略的值)。反过来,N行数据可能要有$L=\lceil log_T(\frac N{B\cdot P}\cdot \frac T{T+1})\rceil$ 层。
write cost (write amplification)
衡量指标:一个写请求的数据,直到数据最后被merge到最底层时,平均的IO次数。
leveling merge从memory component merge到最底层过程中,每层需要T-1次(本层满),因为该记录是同page内其他记录等价的,所以平均的IO次数是$O(T\cdot\frac LB)$。
tiering merge中,每层每个page最多只会被merge一次,所以总共T次,page内每个记录平均IO次数是$O(\frac L B)$。
point query cost
点查询受bloom filter优化点影响很大。
在没有bloom filter的情况下:对于leveling平均是$O(L)$,对于tiering平均是$O(T\cdot L)$。
在有bloom filter的情况下:
- 如果该key确实不存在,则每层触发一次IO的概率是bloom filter的false positive rate,设bloom filter的配置是总共M比特和N条记录,则概率为$O(e^{-\frac M N})$。
- 对于leveling平均IO次数是$O(L\cdot e^{-\frac M N})$
- 对于tiering平均IO次数是$O(T\cdot L\cdot e^{-\frac M N})$。
- 如果该key确实存在,则至少触发一次IO,因为bloom filter的false positive rate远小于1,所以leveling和tiering都是$O(1)$。
range query cost
range query cost比较特殊一点,考虑查询结果只有一条和查询结果是全部记录(例如全表扫描)的两个极端例子,一条结果的查询取决于层数,全表查询取决于对底层数据量(最后一层包含了绝大部分记录)。
具体地,设总共访问了s行,则如果$\frac s B > 2L$,则称为long query,其代价:leveling为$O(\frac s B)$,tiering是$O(T\cdot \frac s B)$,如果$\frac s B < 2L$,则称为short query,其代价:leveling为$O(L)$,tiering是$O(T\cdot L)$。
space amplification
指标为记录总数除以唯一记录数,等价于是重复率的倒数。
最差的情况是:
- 对于leveling,最底层的数据是无重复,但前L-1层都是对最底层的重复(update),因为最底层数据与前L-1层占比大约为T:1,所以space amplification大约为$O(\frac{T+1}T)$。
- 对于tiering,最底层的T个component都是重复的,所以space amplification大约为$O(T)$。
上述结果的汇总:

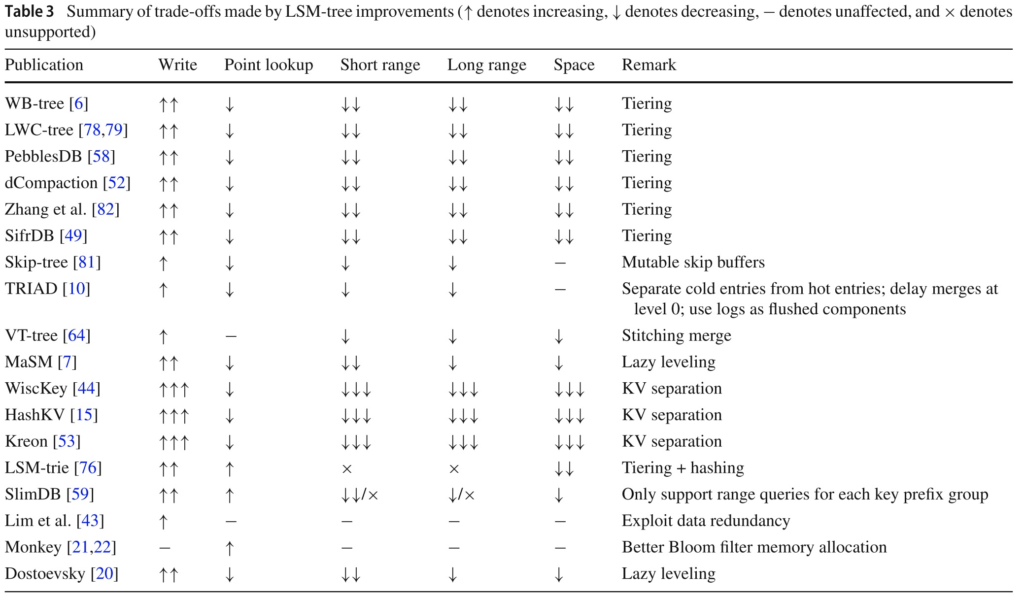
LSM-tree improvements
LSM-tree优化的分类
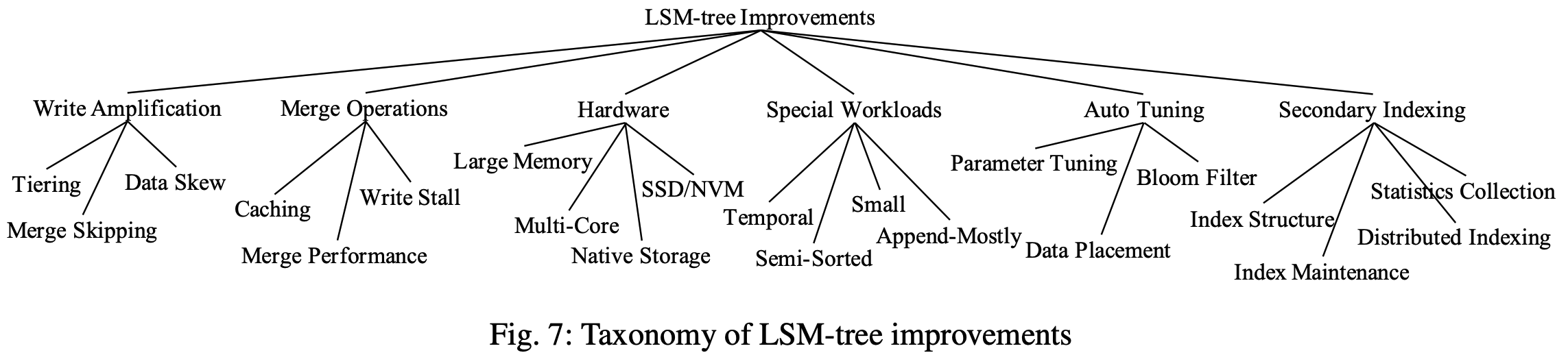
LSMTree的几个问题:
- 写放大:尽管事务wal顺序写然后写memtable,避免了B+树这类in-place的修改,但merge操作还是引入了一些写放大。
- Merge操作:merge操作对LSM性能影响很大,merge会导致buffer cache miss,还可能导致写停顿。
- 硬件:LSM写流程可以充分利用hdd的顺序IO,目前硬件环境发生了变化,大内存、多核、NVM等,有一些研究是针对新硬件下的LSM优化。
- 特殊的workload:针对特定workload的优化。
- 自动调优:RUM猜想说读&写&空间放大三者只能尽量优化其二,但LSM的调优选项有点多,例如内存分配、merge policy、size ratio等。
- 二级索引:如何低代价维护二级索引。
根据这几个问题和对应的优化,目前学术界大致的工作可以总结如图。
降低写放大
tiering
**WriteBuffer Tree(WB-tree) **:一种partitioned tiering with vertical grouping的变体。
Lightweight Compaction Tree(LWC-tree):也是一种partitioned tiering with vertical grouping的变体,并且解决了sstable group之间的workload balance。
PebbleDB:还是一种partitioned tiering with vertical grouping的变体,通过某种方式来确定group的key-range。
dCompaction:引入一个虚拟sstable和虚拟merge的概念,虚拟merge不真做,这样等查询性能下降超过一定阈值再真触发merge。[ ? ]
这几个方案都是某种partitioned tiering with vertical grouping方案,主要区别是sstable和workload负载均衡的方法。
Merge skipping
Skip-tree:的一个跳过某些merge操作的优化。直接将L层的key merge到 L+K 层,能跳过中间 L+1, L+2, … L+K-1 层的前提条件是这个key在中间层不存在(可以用bloom filter快速判定)。
Expliointing data skew
TRIAD:
区分冷热key的优化:识别出hot key之后hot key和cold key区分开,只有cold key flush到 L0,hot key的多个旧版本不刷 L0(wal里面有hot key的最新版本)。
其他优化:1) L0积攒若干layer后才往下merge。2) 用一段wal代替一个component的flush。
注:提升写性能的优化手段声称的写性能提升,是相比未调优的Rocksdb,所以这些提升效果可能实际并不怎么样。
优化Merge操作
提升merge性能
VT-tree的思路是如果发现一组需要merge的sstable文件里面有key-range不交叠的page,可以让merge的resulting sstable直接指向这个page。好处是减少了读取和计算,坏处是会造成一个key-range内的page不连续(可以采用设定阈值触发该优化),另一个坏处是page不被读的话,就不会触发产生Bloom filter,VT-tree用的是quotient filter来解决这个问题。
也有论文是通过流水线CPU和IO来提升merge性能,因为merge操作涉及的多个阶段消耗的资源不一样。
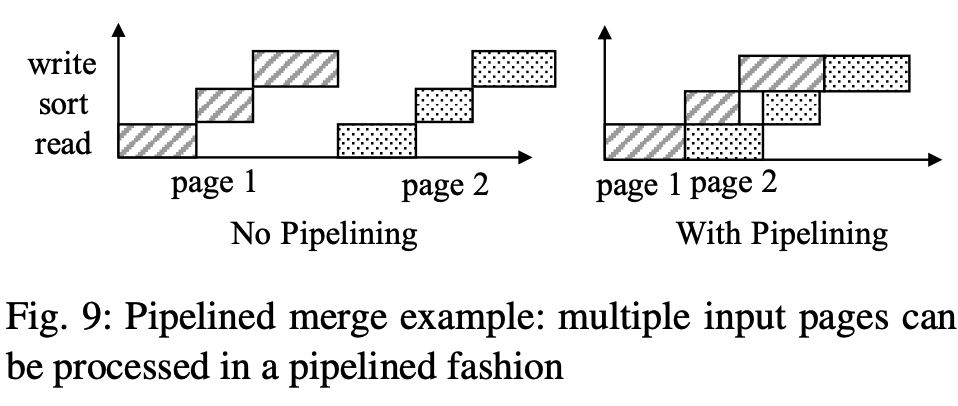
降低Buffer Cache Miss
merge会生成的新component,如果有新的读落在这个新的component上,就会导致cache miss。如果将component全部load到内存,落它上面的读虽然不会导致cache miss,但是会挤压其他正在working page,同样会导致cache miss。
Compaction management in distributed key-value (PVLDB15’) 实验分析了merge带来的性能影响,merge会消耗大量的CPU和IO资源,建议将merge操作offload到其他节点,完成用预热机制来增量地使用新的component。不过这个方法也存在一些问题,第一个问题是merge需要offload到另外的节点,第二个问题是新page与旧的hot page之间的竞争,LSbM-tree将上一层的sstable挂到新的sstable的buffer上缓和cache miss(按照cache淘汰策略被逐步淘汰)。
减少write stals
bLSM允许每层有多个component,不同层的merge可以并发,bLSM每层的速率受限于下一层的情况,像一组连起来的齿轮一样,最终限制了内存表写速率,从而避免了大停顿。
新硬件
大内存
大内存能够降低层数,对读写都有利。
大内存下的问题是内存管理的开销和CPU cache miss。
FolDB利用大内存的方式比较奇葩,它有两个内存结构,一个是小hash,一个是大skiplist,二者是层次关系,小hash只服务写,写满一批就插入大skiplist,大skiplist服务range query,但执行range query前要先把小hash数据搬到大skiplist里面,所以在write和range query混合场景下性能很差。
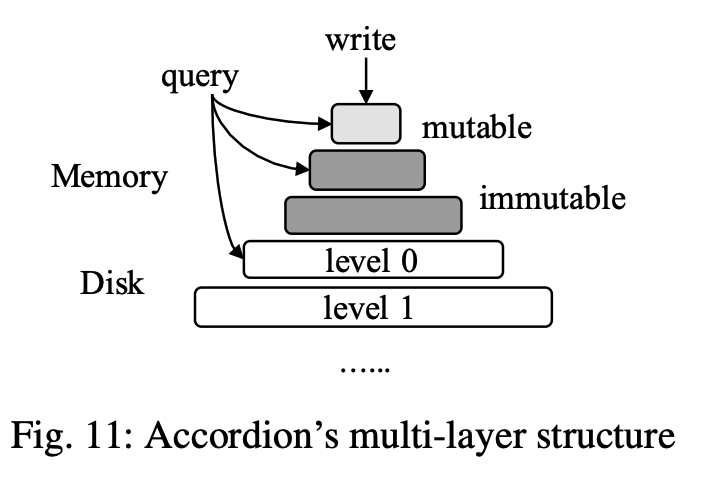
Accordion的内存结构组织如图,mutable memtable变为immutable时,执行一个被称为in-memory flush的操作,将数据在内存里面排的更紧凑。
多核
cLSM将LSM的component组织成支持并发操作的链表,flush和merge最终在修改这个链表时,都只需要原子变量操作即可。对memory component的write kv和flush用读写锁解决并发。
SSD/NVM
FD-tree、FD+tree、MaSM。
WiskKey:因为这类新存储的随机读的性能比较高,所以一个可能的优化思路是,将key和value分开,LSM里面只有key和指向value所在WAL Log的偏移量地址。HashKV和SifrDB都采用了类似的思路。好处是写到LSM结构里面的数据量小了,写性能和merge性能会提升,但是因为LSM里面是间接指向value,读性能会下降,而且GC会比较难做。
NovelLSM将NVM用作存放DRAM和SSD之间的component,另外就是去掉logging,这个思路是比较自然的想法。
Native Storage
绕过文件系统,构建基于LSM-tree的直接存储系统(LSM-tree-based direct storage system)。
面向特定workload的优化
LHAM(log-structured history access method) :是给每个component关联一个timestamp range,时序查询时,可以借助这个timestamp range剪枝,merge的时候也可以通过修改merge策略使得每个component都有不交叠的时间戳。
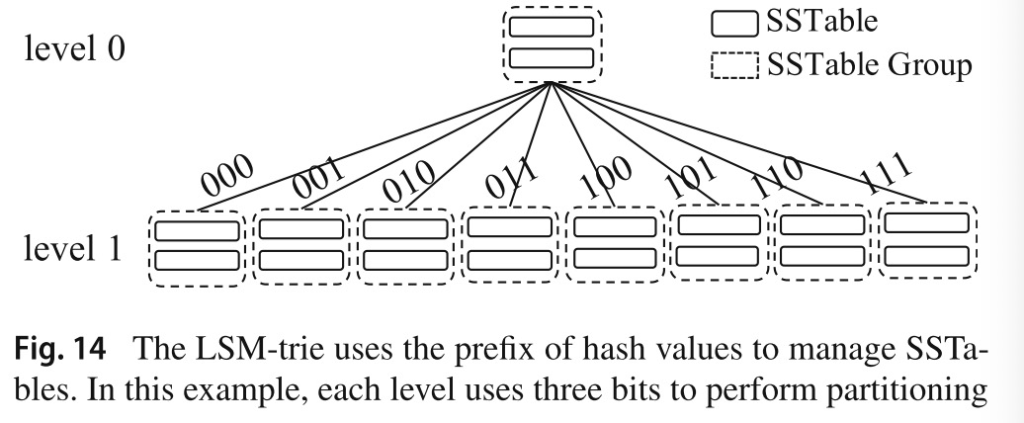
LSM-trie :LSM-trie是一个基于LSM的hash表,sstable组织上采用的是partitioned tiering,中间层直接用hash value进行trie索引。注意该结构只支持点查。
SlimDB:面向semi-sorted数据的LSM-tree。
Mathieu:面向append-mostly的workload。
自动调优
- 参数调整
Lim 提出了一个模型,假设有key分布的先验知识,基于此计算flush和merge的开销。
Monkey :调优联合参数<merge-policy, size-ratio, memtable-vs-blommfilter-memory quote>,找到最优的参数值。
- Merge Policy调整
Dostoevsky :zero-result的点查、长范围查询、空间放大主要取决于最底层,但所有层对write cost都有影响。Dostoevsky引入lazy-leveling,在最底层上用leveling,上层用tiering。
Thonangi:研究了partition对write cost的影响。
- 动态BloomFilter内存分配
ElasticBF:可以基于key的hotness和访问频率调整bf的false positive。
- 优化数据存放位置
Mutant:云数据库将数据按照冷热存放在不同成本/性能介质上,控制总成本。
二级索引
二级索引两个方法:索引键和主键拼成组合键存储,或者索引键作为key,一组主键作为value。
- 索引结构
LLSI(Log-Structured Inverted Index):用于微博的反向索引支持查询最热的K条微博,每个post都有三个反向索引(该post的significance/freshness/frequency)。
Kim:实验分析了基于LSM的空间数据处理系统。此外还有DHB-tree(Dynamic Hilbert B+-tree)、DHVB-tree(Dynamic Hilbert Value B+-tree)、SHB-tree(Static Hilbert B+-tree)、SIF(Spatial Inverted File)。
- 索引维护
Diff-Index:因为更新操作可能导致二级索引的旧项删除和新项插入,Diff-Index提供了几种模式:
- sync-full:插入和删除都同步
- sync-insert:同步插入 + 异步删除(删除通过查询lazily触发)
- async-simple:插入和删除都异步(先把更新放到异步队列)
- async-session:在async-simple基础上,提供session一致性(实现方式是在client端维护local cache来保存update)。
**DELI(Defered lightweight indexing) **:改进了Diff-Index的sync-insert,在merge时,扫描主键component,扫到一个索引列值对应的多个主键列时,把旧的主键拿出来用于删除二级索引。
《Efficient data ingestion and query processing for LSM-based storage systems》(作者的另一个工作) 提出了几种基于LSM的二级索引和过滤器等方案。该工作实验分析了batched lookup、stateful B+tree search cursor 和 blocked bloom filter。其他的一些优化思路是,lasy维护二级索引,通过二级索引拿到pk后也validate一下sk。
- 统计信息收集
Absalyamov:统计信息在flush和merge时附带做。
- 分布式索引
HBase有global index和local index。global index借助HBase的co-process(类似触发器)实现。
也有论文介绍了一个可以并发建二级索引的方法,先从各个主键索引分区生成对应的二级索引片段,然后发到其他节点执行合并。大概类似于hadoop的shuffle。
另有论文介绍了异步维护物化视图的方法,基本还是先同步保存delta然后后台异步消费。
Tradeoff
survey里发现很多优化工作都是在提升leveling merge policy下的写性能(这跟我所了解到的业界需求不太一样……)。
LSM-based的典型系统
LevelDB: Google出品
RocksDB:Rocksdb磁盘利用率比较高,size ratio=10的情况下,大概只有10%的空间放大。B+tree类型的存储引擎通常只有2/3满。Rocksdb的L0是tiering,其他层是leveling。
Cassandra:类似于Dynamo的KV存储,每个partition用LSM组织数据。
AsterixDB:开源大数据管理系统。
未来研究方向
- 全面的性能评估
- Partitioned 的 tiering结构
- 混合的 merge policy
- 减小性能抖动
- 从LSM架构的KV存储研究到LSM的DB研究(索引、查询等)
扫描二维码,分享此文章