本文介绍两个多日志流相关的论文。
《Taurus: Lightweight Parallel Logging for In-Memory Database Management Systems》VLDB’20
CMU的一篇工作,这篇论文是面向单机存储引擎,假设硬件上有多个硬盘(即IOPS还有利用空间)。出发点是存储引擎使用单日志流虽然简单,但串行写日志可能成为瓶颈,尤其是在In-Memory DB中。
注,论文做了一些假设(有些假设可以放松,不影响方案):
- 每个事务只在提交时写一次日志(可能包含多行的修改,修改可以是逻辑修改也可以是物理修改,如果只有物理修改,则后文的readLV就不需要了)。
- 采用严格的2PL加锁(S2PL)策略,但支持ELR提前解行锁。后面解释了其他CC算法下如何应用Taurus。
- 固定个数worker线程,并且每个worker线程固定划分到某个日志流,一个事务由一个worker执行并提交,因此一个事务只归属到一个流。
解决思路自然是从单日志流改为多日志流。
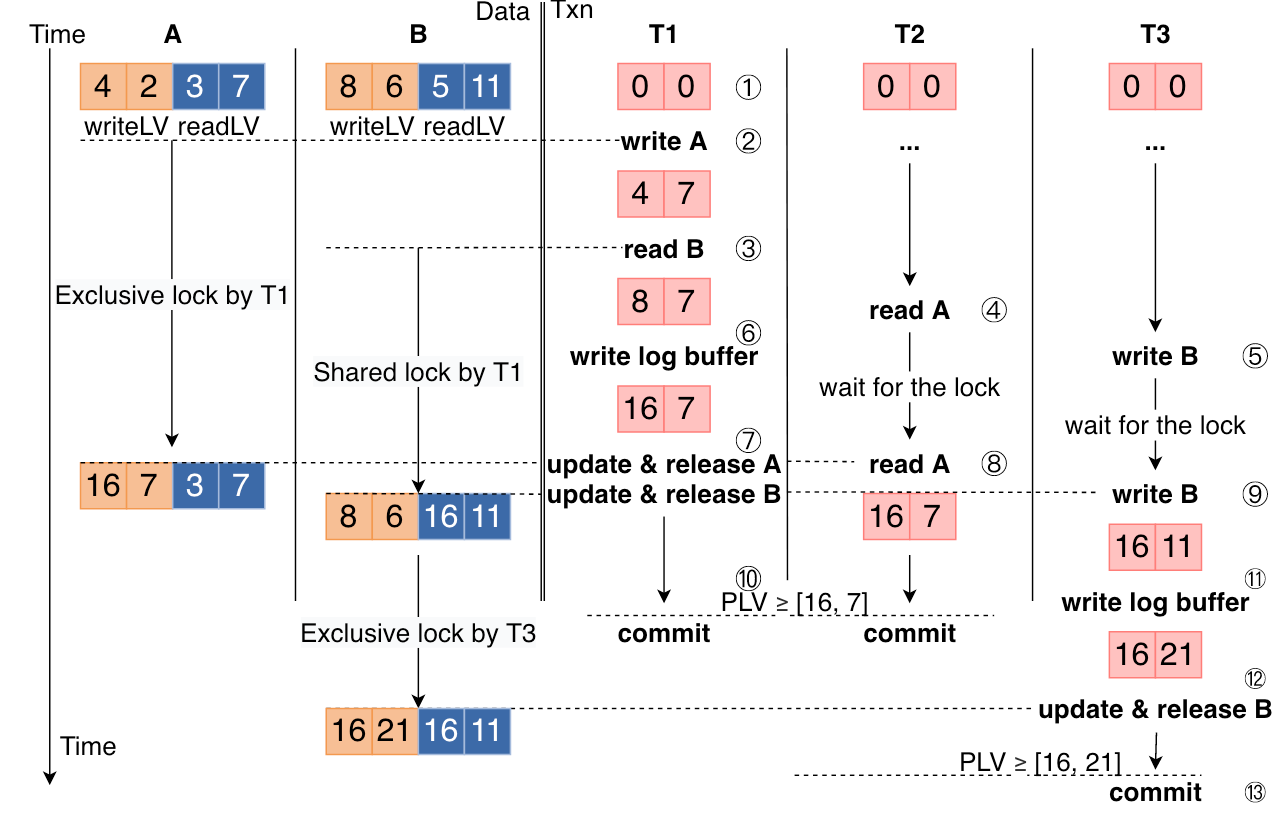
但改为多日志流后,因为ELR,两个有依赖关系的事务(如两个事务先后修改了同一行)可能会并行地写入不同的日志流,那么持久化的先后顺序可能与修改数据顺序不同,因此需要构建事务间依赖关系,事务提交时使用它,且恢复过程也需要这个依赖关系。所以问题的核心是事务依赖关系从单日志流强制下的全序改为偏序后如何捕获这个偏序关系。
注意到事务的依赖关系根源在于读写记录集合之间有交集。因此,(在S2PL+ELR下)可以在行锁上维护最后一次读写该行的事务信息。具体地,记录的行锁上维护了一个readLV和writeLV(LV: lsn vector),含义是LV的每个分量表示该流上最后一次读写该记录的事务的LSN。事务自己也有一个LV表示自己可能依赖的各流上的事务对应的LSN最大值,事务执行过程中访问过的所有行的readLV和writeLV会推大事务的LV(按分量推大)。事务在提交时,需要等待各流持久化LSN分别大于LV的对应分量,即本事务所依赖的那些事务已经提交后本事务才能提交。
logging开销包括四部分:1. LV的维护开销;2. 创建log record开销,copy log record开销;3. 前面1和2导致锁冲突加剧;4.持久化开销。论文提到如果日志流比较多,LV就太大,所以使用了SIMD优化LV的操作。不过相比这个问题,log mgr线程数量应该是个更大的问题,因此并发日志流数量肯定不能太多,或者就是CPU资源比较空闲,后面实验部分用的也是96C大规格机器。
其他:可以支持scan (scan到的每一行都逐行加行锁),可以支持OCC 和 MV;可以支持逻辑日志。
这个方案应用到InnoDB的话,最大的问题一是没有维护全局LSN(可能导致很多依赖单日志流的LSN的设计出问题),二是耦合了锁模块(设计开发复杂度比较高)。
《Border-Collie: A Wait-free, Read-optimal Algorithm for Database Logging on Multicore Hardware》SIGMOD’19
这篇论文并没有提出一种新的parallel logging的方案,而是针对logging(包含centralized logging和decentralized logging,即单日志流和多日志流)中的并发过程中如何高效地维护一个boundary。
需要注意的是,这里的boundary是个抽象的含义,在论文中给的示例中,boundary针对centralized logging和decentralized logging场景,有不同含义:
- centralized logging中是哪些位置的buffer可以执行刷盘
- decentralized logging中是哪些buffer已经刷盘完成
文章的核心是说明维护boundary的算法是wait-free,read-optimal的。
为方便理解,先考虑MySQL8.0中的lock free wal,其中有一个link buffer组件用于维护连续已拷贝的位置。对于应用到centralized logging场景,Border-Collie的boundary算法实质上就是一个与link buffer对等功能的算法,其原理如下:
- 提交日志的线程维护一个flags,flags包含两个信息,一个是color(BLACK表示正在copy buffer,即图中代码line4,WHITE表示已经完成copy),一个是lsn(论文抽象为逻辑时钟)。
- 单独有一个线程(即论文标题中牧羊犬Collie的线程)执行扫描(图中眼睛表示的操作),针对所有已经开始但未结束的线程,记录其开始lsn,对已经结束的线程,以实现取的lsn为其lsn,选择所有线程最小lsn,即为boundary,它表示小于该值的日志都已经连续copy完成。
[IMAGE]
对于decentralized logging,假设有N个worker,每个worker使用一个独立的log,每个log各自有一个flusher。boundary针对的是若干日志流的ts_f,其含义是该log已经连续copy,即可以flush的逻辑时钟(lsn)。boundary的结果RLB是所有log中最小已经flush完成的lsn。
[IMAGE]
Boundary算法的wait-freel是显然的,Collie线程完成一次计算boundary的过程中连retry逻辑都没有,不管worker线程怎么样,Collie线程在有限步骤内必然可以结束算法。
有关read-optimal的论述如下:
we believe it is read-optimal in the sense that the minimum number of reads required for obtaining an RLB is Θ(|W|), assuming that workers never collaborate with each other to facilitate deciding an RLB
意思是,假设并发worker个数是|W|,我们最多只需要看|W|即可确认boundary,因此认为是read-optimal。该论述也不能说没有道理,尤其是要先保证wait-free的情况下。
跟InnoDB的link buffer算法相比,核心差异是该论文将信息的维护做成分布式的,flags是per-worker的,也正是通过这一点做到了标题所描述的wait-free和read-optimal。
扫描二维码,分享此文章