浅谈性能分析
性能分析和优化是一个要求比较全面的工作,通常既要了解所分析的目标系统本身的设计和实现,也要对操作系统等底层基础设施有一定了解,同时需要掌握一些方法论以指导性能分析和优化工作。
本文尝试根据个人这几年做过的几次数据库性能优化的一点经验做一些总结。如前所说,性能分析和优化覆盖面比较广,这里只能抛砖引玉,欢迎读者批评指正。
性能测试
性能分析的第一步是做性能测试。
像MySQL数据库这种适用性较广的系统,性能测试本身就很难做的比较完善,不同场景、不同配置、不同数据规模、不同负载下测试,MySQL的性能瓶颈往往都不相同。所以怎么测,要测哪些场景是需要考虑的一个问题。
如果你是业务方,那么测试场景就比较简单,可以直接上模拟业务流量。如果你是云数据库厂商,可能就比较麻烦。数据库实例众多而且客户实例也不能随便监测,可能很难分析负载模型。不过数据库发展了几十年,有一些成熟的性能测试工具,例如sysbench和tpc系列benchmark等。sysbench比较简单,很容易上手。tpc测试更规范一些,还有官方审计,例如OB跑过tpcc/tpch,ADB等跑过tpc-ds等等。
性能分析的三个层面
性能分析有几个层面可以考虑。
首先,关注架构设计,架构设计决定了系统的性能上限。
举个例子,单机版本的数据库如MySQL或Oracle,它最多将单机硬件资源榨干。相比而言,如Aurora这种存储计算分离的一写多读的系统,硬件资源就可能多几倍,其中的存储层除了存储功能还有部分计算资源用于apply redo log,甚至部分读写节点的计算任务还可以offload到这里;这相比单机版本的整体性能上限就高数倍,但Aurora的架构还局限在只有一个写节点(新版本支持比较弱的多写能力,我们可以先忽略),其写性能还是会有瓶颈。再相比而言,以Spanner为代表的share nothing水平扩展的数据库,写性能上限会高很多,这也是OceanBase可以打榜TPCC的底层逻辑。实际上,容量和性能上限本身也是架构设计需要重点关注的。
其次,需要了解待分析系统的系统设计。
当然架构设计是在系统开发之前的工作,我们往往是拿到一个已有的甚至是演化很久的系统来做性能分析和性能优化。这种情况一般需要在性能分析之前对系统有较为深入的了解,包括系统的主要设计和关键路径的实现。例如需要知道MySQL一条查询从头到尾执行的主要流程,知道每一个阶段可能的耗时在哪里。同时最好也对其他类似系统有了解以做参照。了解的越多,越容易分析和识别性能瓶颈。
如果你了解的少也不用焦虑,一般数据系统的大致执行流程大同小异,很容易通过论文或者文档学习到。文档里面没有的细节,可以一边分析一边学习。这有时候反而可以让你从系统实现者之外的视角去思考系统该如何设计和实现,可能更容易发现处理请求的不必要的开销。
第三,从资源利用率的角度分析系统瓶颈。
也就是很多地方提到的USE方法,Brendan Gregg在其博客上论述比较清楚。简单地说,USE(利用率/饱和/错误)是看系统压测跑起来后软硬件资源的利用率情况,资源主要包括CPU、内存、IO、网络这几类。
性能优化的目标就是,在给定资源下尽量让系统把资源完全利用起来,并且资源尽量都用在有效工作上。
什么是有效工作?比如 select sum(col_2) from t1 这种查询里面,求和的加法就是有效工作,因读数据可能带来的mutex等冲突就不是有效工作。当然,哪些是有效工作哪些是无效工作的分别并不明确,比如查询的优化过程,可以是有效工作,因为不走优化器就不能找到合适的执行计划,但如果有Plan Cache,则每次都做优化又成了无效工作。识别有效工作,减少一次请求的有效工作量(如通过支持Plan Cache减少优化开销)本身就是就是性能优化的一部分。
性能相关的一些基础知识
CPU亲和性
CPU亲和性是指Linux内核在调度线程时,同一个线程尽量调度到同一个核的策略。
设置亲和性主要有两类原因:一是有利于减少因为线程调度带来的cache失效,二是可以实现进程隔离。
详细请参考taskset命令和sched_setaffinity接口。
NUMA
NUMA是指non-uniform memory access,非一致内存访问。
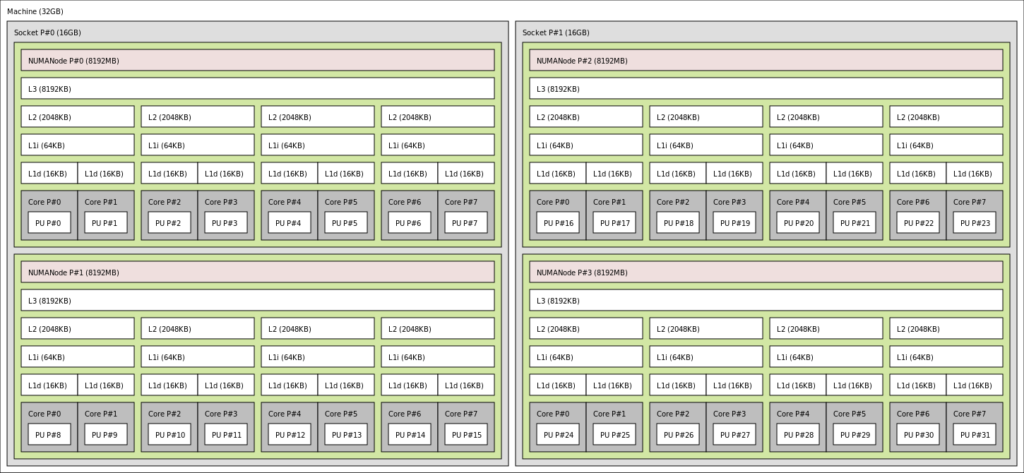
维基百科上这张图比较清晰。图中CPU有两个socket,4个node,每个node包含8个core。Node概念上包含一组core和一块内存,Node之间有QPI(quick path interface)连接,Node中的core访问自身的内存比较快,访问其他node的内存就要走QPI,会比较慢。
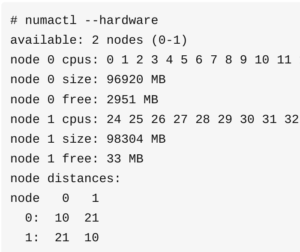
numactl命令可以查看numa的情况。
例如,另外一台机器(与上图不同)上CPU有两个node,node distance描述了访问延迟的相对大小。
像数据库之类的应用,需要注意 swap insanity 的问题(开启NUMA后本node内存不足时触发swap而不是从其他node分配),不过高版本内核应该已经解决了。
Cache
Cache是介于CPU与内存之间的存储层次,用于提高读写数据性能。如前图所示,Cache分为L1/L2/L3三级,容量和延迟逐级增大,同时L1的cache还会分为数据cache和指令cache以避免互相污染。
常见的一个Cache相关的问题是伪共享 false sharing:Cache是按Cache Line(一般64字节)来加载或淘汰的,如果两个core读写同一个64字节内的不同地址a和b(例如排在一块的两个全局计数器变量),比如其中一个core修改了a,则会失效a和b所在的64字节缓存内容,并通过cache一致性协议MESI通过QPI将该失效信息同步到其他core,那么另一个core读取b就需要从内存读取。解决方法也比较简单,如果两个变量经常被并发访问,就不要放一块,或者中间加padding撑开。
TLB
页表是用于将虚拟地址转为物理地址的映射表,页表存放于内存中。TLB是页表的硬件缓存。TLB也分为dTLB和iTLB。
如果发现TLB的命中率比较低,可以试下huge page。很久以前我之前遇到过一个场景,内存中存放了大量的数组数据以供查询,启用huge page可以显著提升性能。
另外,如果发现iTLB命中率比较低,可以考虑PGO等优化来改善二进制文件的代码排布,见 BOLT。
指令流水线
现代CPU都支持指令流水线,教科书上一般分为取址、译码、执行、访存、写回。实际CPU的流水线有几十级。流水线执行的越流畅,平均每个时钟周期能执行的指令数越多,也就是IPC(instruction per cycle)越高。反之,如果出现两条指令抢占同一个部件(structure hazard)、当前指令执行依赖上一条指令结果(data hazard)或 遇到分支预测失败(control hazard)流水线就可能停顿。编译器编译阶段和CPU运行时会通过重排或乱序的方式减缓hazard,但写码实现上也要注意。比如虚函数调用是间接调用,要先根据对象找到虚表里面记录的函数地址再调用。这对指令流水线不利,所以不要滥用虚函数,尤其是访存可能是瓶颈的情况下。
Lock Free编程
Lock Free编程指的是并发编程时不使用同步锁,一个线程暂停(例如调度离开CPU)时,不阻塞其他线程progress。
在遇到并发锁冲突的时候,可以考虑看看是不是可以用Lock Free的方式优化。
不过Lock Free还有一个附加问题 - 内存回收,常用的机制如Hazard Pointer, EBR等,比较麻烦但其原理和实现跟具体无锁的数据结构无关,比较通用。
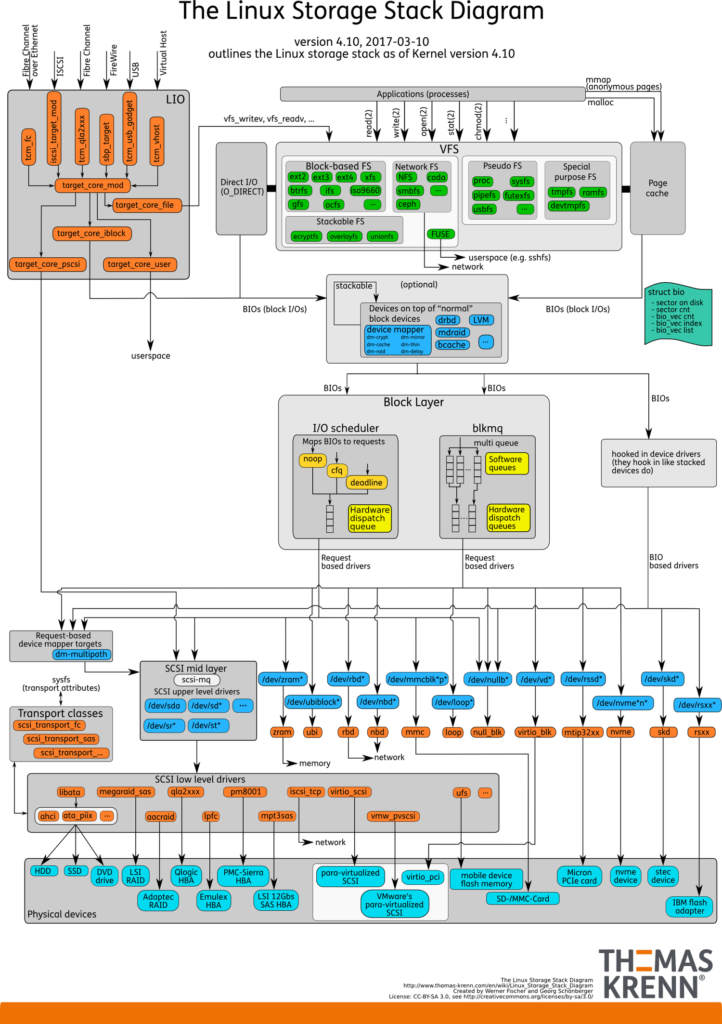
IO Stack
性能分析工具
Linux下有丰富的监控工具,可以满足各种维度的查询,以CPU利用率为例,可以查询到整台机器的CPU利用率、进程的CPU利用率、每个核的利用率、每个核sys/usr/irq/soft等、进程内的每个线程的CPU利用率等等。
CPU
top
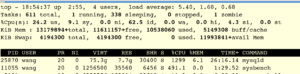
其中CPU列表示进程的CPU利用率,图中1299%表示mysqld进程占用了约13个核。
htop
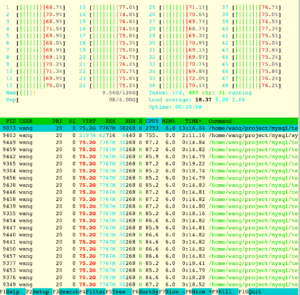
htop可以看到每一个核的利用率,这有助于排查一些做了绑核操作相关的问题,例如绑核后工作线程的负载不均匀等等。其中红色表示sys,指CPU花在内核上(例如内核spinlock冲突 或 网络栈 之类的),绿色表示usr,指CPU花在用户态。如果sys比较多,可能需要排查下具体花在内核什么地方了,例如并发写文件(写不同位置)可能导致inode上的锁冲突,这样就需要对应优化应用代码。如果没有明显的应用层瓶颈,可能需要考虑kernel-bypass的一些技术,例如SPDK/DPDK。
关于亲和性的一个直观例子(进程的6个线程分别跑在1-6号核上):
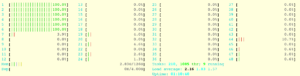
vmstat

vmstat也有CPU相关的信息,其中 id表示idle,wa表示花在等待IO的时间,st表示stolen(跟虚拟机有关)。
mpstat
mpstat也能查看CPU各个核利用率(类似于htop),并且可以看到中断占用CPU的情况。
%irq和%soft分别是处理硬中断/软中断的CPU开销,这里可以用于排查中断落在同一个核的瓶颈等问题。
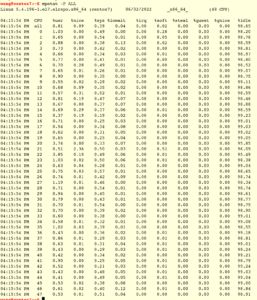
pidstat -u
pidstat可以指定进程号。-u 表示显示CPU利用率,-t 表示显示进程内的各个线程。
如图可以看到mysqld进程中只有8个工作线程在忙。
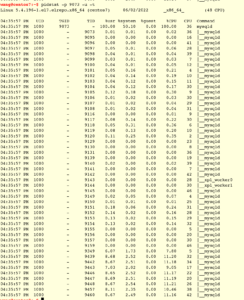
Intel VTune
Intel VTune是面向intel CPU的一款分析工具。分析方法见 Intel Top-Down Microarchitecture Analysis Method。
内存
free 可以看到内存概况,buff/cache是指例如page cache等内存占用。

Linux下内存需要关注下swap,如果有发生swap,可能是出现内存不足了需要倒腾内存空间出来。
vmstat -a 可以看到内存swap情况。

IO
iostat 用于显示io的各种信息。


- tps: 每秒向设备发送的请求数目
- kB_read/s:每秒从设备读取的字节数目
- kB_wrtn/s:每秒写入设备的字节数目
- rrqm/s, wrqm/s:每秒merge的读/写请求数目
- r/s,w/s:每秒完成的(merge后的)读/写请求
- rkB/s, wkB/s:每秒读/写多少kB
- avgrq-sz:请求队列的平均长度(长度以扇区数目计数)
- avgqu-sz:请求队列的平均长度(长度以请求数目基数)
- await:IO请求处理的平均耗时(以毫秒计),包括在队列等待时间和实际设备服务时间
- r_await:读请求处理的平均耗时(以毫秒计),包括在队列等待时间和实际设备服务时间
- w_await:写请求处理的平均耗时(以毫秒计),包括在队列等待时间和实际设备服务时间
- %util:设备带宽利用率,如果接近100%表示设备可能达到IO上限了。
blktrace
blktrace是分析块设备IO性能的利器,它可以追踪各个关键阶段的耗时。
blktrace有一组命令,blktrace用于追踪,blkparse用于解读blktrace的结果,btt用于汇总分析。
blktrace 执行起来之后,Ctrl-C终止执行,默认在当前目录下生成一组sda.blktrace.{CPU}的文件。
然后执行blkparse -i 解析这些文件。
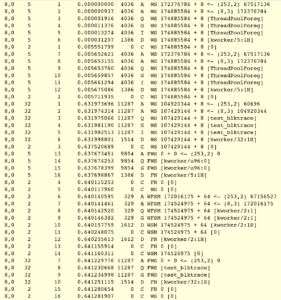
其中,第一列是设备(用主设备号和次设备号标识),第二列时发生在哪个CPU,第三列是sequence number,第四列是时间戳(启动时为0),第五列是进城号,第六列是Action,第七列是RWBS,第八列是进程名。
Action各字母含义:

RWBS的含义:R - read, W - write, D - block discard, B = barrier, S - synchronous
btt工具可以汇总分析,blkparse的输出数据,不过要先把按CPU分开存放的数据合并起来 blkparse -i sda -d sda.blktrace.data,然后再执行 btt -i sda.blktrace.data 。

各阶段描述可参考[4]
- Q2Q — time between requests sent to the block layer
- Q2G — time from a block I/O is queued to the time it gets a request allocated for it
- G2I — time from a request is allocated to the time it is Inserted into the device's queue
- Q2M — time from a block I/O is queued to the time it gets merged with an existing request
- I2D — time from a request is inserted into the device's queue to the time it is actually issued to the device
- M2D — time from a block I/O is merged with an exiting request until the request is issued to the device
- D2C — service time of the request by the device
- Q2C — total time spent in the block layer for a request
文件系统
lsof lsof用于显示所有打开的文件(就是拿到fd的这种),因为linux下有“一切皆文件”的抽象,所以这里面还包括网络连接、管道等等。从截图还可以看到有些已经被deleted的文件实际上还在占用空间,但如果去它所在目录看却看不到。

网络
ip addr 查看本机的网络接口

ethtool 查看网卡配置
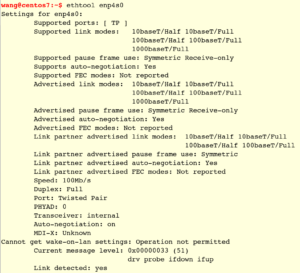
从Speed可以看到是百兆网卡。
iperf3可以用来实测机器之间的网络带宽,在两台机器上分别以server和client启动iperf3,就可以测起来了。
iftop 用于查看实时流量

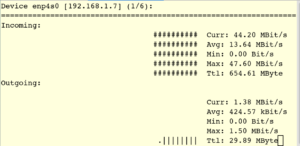
nload 用于查看实时负载,如下图,incoming流量为44.20 Mbps。
nethogs 可以用来查看每个进程的流量情况。
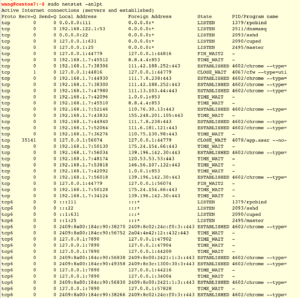
netstat
netstat可以从网络连接/socket的情况进行分析。
pstack
pstack工具可以回答 “进程现在在干什么? ”。pstack可以获得进程的各线程的快照,从中可以看到各个线程在执行什么操作。pstack实际上就是个shell脚本,调用gdb attach上去执行 thread apply all bt命令打印各线程的调用栈。
执行结果(部分截图)如:

pstack输出比较多,有些线程的栈都是相同的,因此pt-pmp(percona的工具套件之一)可以用于聚合其输出结果,聚合后的结果如下(部分截图):

这说明进程中当时有17个线程在将结果通过网络发送回去,有10个线程在等待,等等。
pstack除了用于性能分析之外,在分析死锁等问题时也是最好用的工具之一。但如前所说,pstack会hang住进程几秒到几十秒,使用的时候要注意影响。
perf
perf是linux下最常用的性能分析工具之一,它可以读取CPU内置的PMU数据,提供非常详实的性能信息。
perf top可以回答 “CPU在执行什么?”。
除了top,还可以 perf record -g -p 1234 sleep 5,表示抓取5秒内进程号1234的栈信息,该命令结束后在当前目录生成一个perf.data文件,用 perf report打开该文件,可以看到和perf top相似的输出:

其中的+/-可以展开/折叠。
实际上perf可以捕获多种event,执行perf list命令可以查看,在我的机器上输出有几百个event可以trace,包括cache、流水线、访存、虚拟内存、分支预测、TLB等方面,还包括库代码的event(USDT,user-level static probe,比如sdt_libpthread:cond_wait等)。
我们举个USDT的例子:pthread.so里面有个probe名为mutex_entry,我们分析关于它的调用情况。
首先 perf probe -x注入,然后perf record监测,最后perf report显示结果。
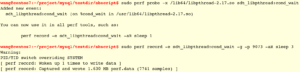

从这里可以看到进程调用pthread_cond_wait频率最大(71.35%)的是事务提交流程change_stage函数中对pthread_cond_wait的调用。
火焰图
火焰图是非常直观的数据展示方式,常用于展示各性能数据(如调用栈)对某个指标的贡献程度。
以分析CPU热点为例(svg格式,可以鼠标交互):

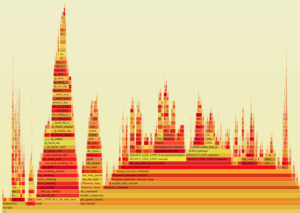
除了分析CPU消耗,其他多种数据都可以用这种直观方式展现,因为火焰图只是counter+frequency的展示方式。
这里本文提供同一个场景测试的两个性能数据,一个是perf结果,一个是pstack结果,从中看到不同维度的信息。


上面两个图的对比可能还不能明显显示perf和pstack火焰图的差异。读者可以考虑如下的demo程序:进程有100个线程,其中1号线程执行一个耗时的计算如计算圆周率pi,2号线程执行计算自然对数底e,有49个线程等待pi的计算结果,49个线程等待e的计算结果。
Linux计时
计时可能时最朴素的性能分析方法了,堪比print之于debug。Linux下有多种方式来计时。
RDTSC
RDTSC是Intel的一个指令,读取CPU内部的time stamp counter。这种获取时间戳的成本非常低,非常适合计时来比较耗时大小。但是这里需要注意多核CPU中,RDTSC可能会不准确的问题,有些CPU支持了Invariant TSC,这种情况可以用来准确计时。可以通过查看CPUID.80000007H:EDX[8]位的值来判断是否支持Invariant TSC,这里有个工具[2]可以对CPUID值做全面的解释(部分截图):

clock_gettime
clock_gettime获取纳秒精度的时间戳,具体可参考手册 man clock_gettime。
eBPF
eBPF是一种强大的内核追踪技术,现在还在快速发展中,未来可期,值得关注。

eBPF类似于linux的module,也是用户写的代码运行在内核态,但采用了沙盒和代码验证,因此更安全,也更方便。eBPF可以追踪内核函数,也能追踪应用进程的函数。一般要求linux内核版本比较高,最好到5.0以上。另外,通过eBPF对内核状态进行监控以支持性能分析需要对内核有比较多的了解,了解越多,eBPF用的越顺手。
bcc是常用的eBPF开发套件,用户可以自己开发性能分析工具,实际上bcc也自带了一组性能分析工具,如下图(来自Brendan Gregg)。

我们这里挑几个工具简单介绍下。
比如funccout用来追踪指定函数调用了多少次。
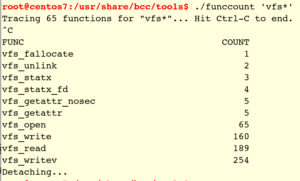
除了vfs_write这种内核函数,用户态的函数也可以追踪。读者可参考bcc的手册。
再比如,offcputime用于追踪线程offcpu的情况,其原理是trace内核进程调度模块的finish_task_switch内核函数,记录切换的前后进程和发生的时间戳进行分析。该工具可以回答 “线程为什么放弃了CPU,放弃了多久才重新调度回来”。
bcc套件还是挺好用的,我自己也写过简单的工具用于分析系统。
性能分析实战例子
以MySQL单机性能分析为例,架构方面资源就只有本机资源,MySQL跑起来的主要流程假设读者也都知道,接下来就是一边测试一边分析资源USE,然后调整参数或优化代码测试验证。
这里举几个简单的实战例子。
我们用sysbench压测本机的mysql服务器,测试oltp_insert 128并发场景,QPS约5000。
观测发现CPU很闲,大概只有9%的利用率,但是IO很忙,%util接近满。注意,监控命令的前几秒输出不准确,读者自行忽略。
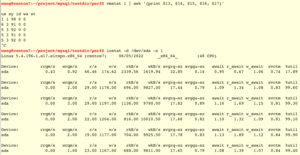
MySQL写盘主要是binlog文件,innodb redo文件,innodb page文件。
写日志文件一般都支持配置是否实时sync。针对前两者,尝试修改参数 sync_binlog=0, innodb_flush_log_at_trx_commit=2 (注意:这两个参数影响事务持久性,这里简单地假设用户可以接受新的参数值),QPS从5000升到50000。
测试跑了一会,发现磁盘满了,更新了测试目录重测。新盘性能好一点,QPS跑到了9万左右。监控数据如下。

现在看起来IO还没有打满,但是CPU利用率也只有约55%左右。
CPU跑不满的可能的原因有:进程里面worker线程数目本身就不多;线程数目多但很多线程都不占用CPU(例如在等待IO或网络,或者等待其他业务逻辑)。总之就是没有足够多的线程处在RUNNING状态。
我们的这个测试环境下,客户端并发度128不算低,网络也没问题(测试客户端和myqsld在同一台机器),在观测前我们可以排除这两个因素。接下来我们看线程放弃CPU在干什么。
这里可以使用bcc的offcputime工具来分析,但我本机跑这个命令有点问题,跑不起来,可能是OS内核版本不行,我们改用pstack跑,我们可以抓10次pstack数据,合并后用火焰图分析看看。
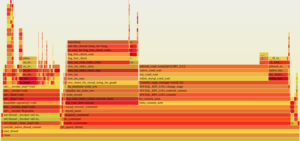
从中可以看到,比较集中的是两块:有很多线程在插入新数据的时候log_free_check_wait,另有很多线程在ordered_commit流程的enroll_for中等待。
前者是指redo log在循环复用的时候需要确保旧的日志不再使用,这部分旧日志对应的事务已经checkpoint刷盘(可能是log file size太小或者checkpoint跟不上)。后者是事务group commit后提交时被group的线程等待代为提交。
排查了下log file size参数,发现默认值比较小,改大后重测,仍然是同样的问题,所以怀疑可能时checkpoint跟不上。checkpoint跟不上可能时刷脏页跟不上,我们调大刷脏页线程数目,重测后的pstack火焰图如下:

如图可以看到log_free_check_wait已经看不到了。
MYSQL_BIN_LOG::change_stage的等待,是group commit带来的,修改binlog_order_commits=OFF能够减缓该问题,原因是允许并发在innodb层提交,THD阻塞时间减少。但这个问题仍然存在。
再看一个例子。我们测试只读,因为buffer pool足够大,所以可以看到CPU已经完全跑满了。

perf看到的结果如下,optimize开销比较大,因为MySQL现在还没有Plan Cache功能。

这个在现阶段可能就没有明显的瓶颈,优化空间比较小。
扩展谈一谈MySQL数据库的性能。
第一个点是binlog。Binlog从性质上说是MySQL Server层的WAL,但InnoDB也有自己的redo log。一个数据库有两套日志,这实际上是不常见的。Binlog带来的好处是比较容易在一个实例内支撑多个存储引擎,坏处是两套日志显然会拖慢性能。
第二个点是MySQL被Oracle收购后,代码进行了大量的重构,比如innodb的log sys和lock sys、server字典、DDL等,这些重构解除一些瓶颈,但仍然还有,因此性能还没有大幅的提升。看官方重构的节奏,应该还会继续。但也不排除有些功能可能不会出现在开源分支,而是只在付费企业版本里面有。
第三个点是SQL层性能问题,包括Plan Cache等功能在其他数据库里面算是标配了,但MySQL一直也没有,主要原因就是SQL层代码模块化不好,改造难度非常大,考虑到国内很多分支还要follow官方的变动,这个事情目前来看只能依靠Oracle官方来搞了。
高性能系统实现案例
ScyllaDB & Seastar
ScyllaDB是一个高性能NoSQL数据库,底层使用了Seastar高性能框架。Seastar的核心想法是data shard per core,并且完全异步化,shard之间使用message passing而不是共享数据,因此可以避免数据同步。此外还支持DPDK等网络栈。在Searstar中,请求之间的同步比较少,如果请求需要等待一个条件,则可以先执行其他请求,因此CPU是比较容易充分跑满的。Seastar几乎可以达到线性扩展。
CoroBase
内存数据库中,访存可能会成为整个数据库的性能瓶颈。CoroBase的优化思路是借助协程来overlap访存开销。比如当前请求接下来要从内存中读取数据,则为了overlap读内存的延迟(data stall),当前请求先prefetch对应地址,然后使用协程让本线程放弃当前请求的执行,转而执行其他请求,当后面又调度到原请求时,我们期望prefetch也已经完成,因此原请求读取数据就比较快。
需要注意的是,CoroBase借助了C++20的协程,其调度开销已经接近普通函数的开销,否则用协程掩盖访存data stall会适得其反。
PolarFS
PolarFS充分利用了用户态的网络栈和IO栈,比较新的RDMA/NVMe/SPDK等技术,将一个分布式FS的性能做到了接近本地FS的性能。
NVMe盘的性能非常好,500K IOPS & 100us latency,3DXPoint的延迟甚至到了10us。RDMA传输4KB数据到同一交换机上的其他节点耗时7us。这些新技术相比传统IO和网络技术提升非常多,如果要做到极致的性能,就需要考虑这类优化改造方向。
X-Engine
X-Engine在LSM-Tree上做了很多性能的优化,例如
- Cache是存储系统的标配,但Cache做好也不容易,内存管理/数据结构细节/cache汰换/预热等等问题都需要小心处理。X-Engine有丰富的Cache系统,如Block层面有BlockCache,SST记录层面还有RowCache等等
- 事务提交流水线,将事务提交改造为多级流水线,并调节使流水线充分运行。RocksDB后来也支持了简单的流水线。
- FPGA加速compaction,将compaction这一耗费IO和CPU但核心逻辑比较简单的工作offload到FPGA之类的新硬件,扩展系统可用的硬件资源。
- 多种优化并发的技术,如lock free skiplist, cow object, thread local object等等。
Hekaton
Hekaton是SQL Server的内存事务型引擎,是微软的几位系统研发大佬主导开发的。
Hekaton的所有关键数据结构,包括内存分配器、hash/range索引(BwTree)、trans-map等完全都是lock-free的。关键路径上没有任何spinlock/latch。Hekaton的OCC算法也是完全lock-free的。我甚至怀疑几位大佬写码的时候可能脑子里面一直在评估CPI。
像编译执行这种大杀器自然也必须搞。
此外,从logging、checkpointing和recovery组件的设计原则(顺序访问IO;主流程尽量减少操作,能移到Recovery阶段的操作都移过去;消除扩展性瓶颈)都能让我们看到极致的性能是怎么做的。
总之,Hekaton的搞法给的人感觉就是,老司机就是老司机,不服不行。
总结
性能分析是一项要求比较全面的工作,需要从架构设计到系统实现都有了解,对硬件资源和OS的特性比较熟悉,掌握一些必要的方法轮和分析工具。
我们大部分时候都是面向一个已有系统做性能分析和优化,这种情况限制比较多,可能这也不能改那也不能改。如果你有机会从头设计开发一个新的系统,则性能是必须考虑的一个方面。有读者可能会说 “过早优化是万恶之源”,但这也只是针对开发编码阶段,架构设计和系统设计阶段必须把性能考虑进去,务必明确在你的设计下性能天花板在哪里。
掌握一些基本的高性能程序开发技术是作为数据系统开发的必备能力。学习优秀的系统设计和实现也是一种重要的提升方法。
参考
[1] Brendan Gregg https://www.brendangregg.com/ 著名性能分析大佬,宝藏博客
[2] 解析CPUID https://github.com/tycho/cpuid.git
[4] blktrace工具 https://developer.aliyun.com/article/698568
[5] Deep in blktrace https://zhuanlan.zhihu.com/p/355548200
[6] eBPF https://cloudnative.to/blog/bpf-intro/
[7] bcc手册https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#4-attach_uprobe。
[8] ScyllaDB & Seastar https://www.scylladb.com/,http://seastar.io/
大牛