MyRocks in Facebook UDB
MyRocks: LSM-Tree Database Storage Engine Serving Facebook's Social Graph》
这篇文章介绍了Facebook为了解决UDB数据库成本迁移MyRocks的挑战和解决方案。
Introduction
迁至MyRocks所遇到的挑战
- 在Facebook UDB场景下,MyRocks将存储空间压缩了一半,因此实例数目减半,也意味着UDB集群的CPU和IO硬件资源减半。
- Range Scan的Forward和Backward性能不一样,这个主要是底层数据编码格式导致。
- Key Comparison次数变多,原因是LSMTree数据全局有序性较低。
- Range Scan比InnoDB慢。
- BloomFilter对内存的占用:BloomFilter对点查询性能比较重要,但BloomFilter要占用一部分内存。
- 标记删除(tombstone)带来的查询性能下降。
- Compaction带来的突发影响,Compation通常会带来突发的IO/CPU资源消耗,可能会导致性能stall。
MyRocks的创新点
- Prefix Bloom Filter:提升scan性能
- Key比较时候用memcmp
- 新的tomestone类型用来高效处理二级索引
- bulk load模式
- 混合compression:高level用性能优先的压缩算法,最底层用压缩率优先的压缩算法,这样memtable flush更及时,compaction速度也会更高一点。
迁移工具
- MyShadow:将用户query复制一份到测试库。
- 正确性校验:全索引数据对比
- 依赖副本的迁移:增加一个MyRocks的备库即可。
迁移效果
- 存储空间节省62%
- 写Flash数据量减少75%
- 性能与InnoDB持平
- 机器数目减半
Background And Motivation
UDB架构
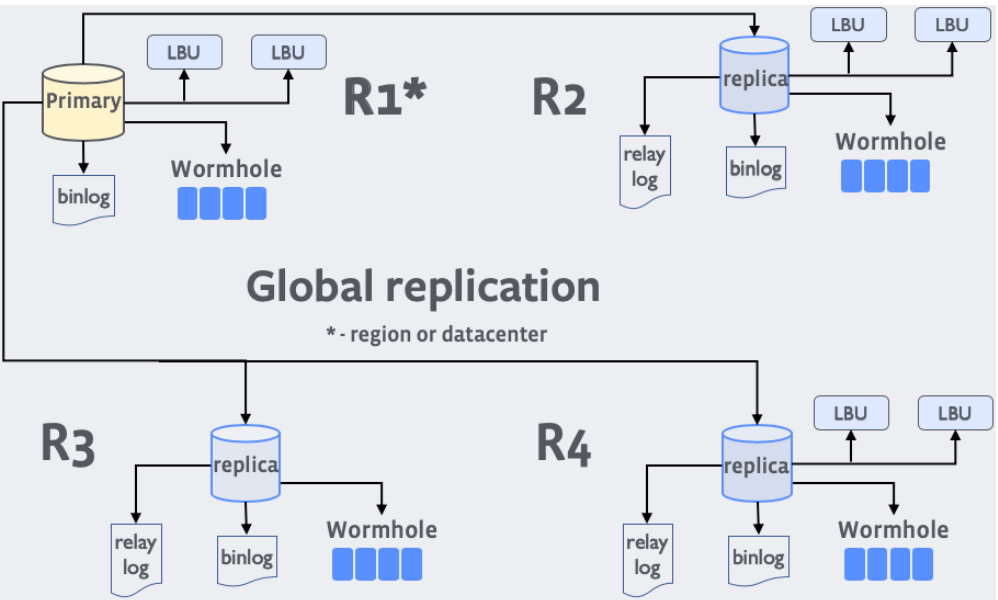
其中, LBU=Log Backup Unit,可以接收并保存最近一段时间的binlog;Wormhole是基于binlog的pub-sub服务,例如通知异地cache系统失效旧数据。
每个region只有一个全数据副本,其中全副本的Primary-Replica用异步复制。
每个region内有三个实例(1个Replica + 2个LBU),用Semi-sync复制。
这样的部署方式,兼顾了数据可靠性和请求响应延迟。
在Facebook,UDB和应用之间还有一层TAO,TAO是一个cache(write through)。
TAO作用,一是提供读Cache,二是TAO仅提供有限的API,迫使应用不会触发bad query。
UDB存储
2013年,UDB全部署SSD后,存储成本高,开始探索低成本方案。
InnoDB页面浪费比较多,有压缩空间降低成本。InnoDB浪费主要来自B+Tree索引,每个页面可能浪费25%~30%。但启用defragmentation会导致性能下降,同时减短了Flash写寿命。另外InnoDB压缩效果不理想,InnoDB是按页面压缩,压缩后还是要占用某种尺寸的页面大小(比如16K页面压缩成5K,但还是要占一个8K的页面空间)。
InnoDB的另一个问题是写放大,一个页面修改少量字节变成脏页,但在将来刷脏页时,就得一整个页面刷下去。再加上InnoDB的double write机制,写放大会更严重。
RocksDB: Optimized for Flash
RocksDB的存储空间优势的原因:
- InnoDB有B+Tree页面浪费(25%~30),RocksDB没有,RocksDB的旧版本数据可以通过调节compaction来控制占比不超过10%。
- InnoDB压缩页必须对其到4K/8K/16K,RocksDB不需要对齐。
- InnoDB的每行的元数据包括6字节事务id和7字节roll pointer,RocksDB只有Sequence,而且最底一层Sequence可以设为0,仅占一些flag位。
MyRocks Development
迁移目标
迁移工程:提升利用率优先级比较高,但是可靠性、隐私、安全性、简单性都不能回退。
迁移适用范围:读密集的应用不适合迁移。
性能优化
CPU消耗
Mem-comparable Keys
LSMTree在range scan时,会产生比B+Tree多的多的key compare操作。首先,初始化scan iterator的初始值时,B+Tree只需要在全局有序的页面中定位一次,LSMTree需要在多个sorted run上都查一次。其次,iterator推进时,B+Tree不需要触发key compare比较,LSMTree需要在多个sorted run上执行归并比较。
考虑到不同的collation,MyRocks存储的key都是经过转化,可以直接bytewise-comparable的。
Reverse Key Comparator
RocksDB中Forward Iterator比Backward Iterator快。原因有几个,一是block内key存放时使用前缀压缩,相邻key可能只存放差异部分,这种方式对Backward Iterator实现层面不友好;二是多路sorted run归并时,可能出现同一个key的不同版本,这些不同版本是按新版本存放在前的顺序存放,这就导致backward时,需要读到下一个不同的key时,才能知道读到了当前key的最新版;三是memtable底层索引结构是skiplist,它只有前向指针,所以backward时,还要多一次二分查找。
对于使用backward更多的场景,可以直接把key compare逻辑取反,这个方法称为Reverse Key Compare,但是同样地,这种情况下,forward就慢的多。
Faster Approximate Size to Scan Calculation
Scan代价估计优化的两个优化思路。一是如果指定了force index,就不触发代价估计。二是如果粗略计算查询区间内所有的完整sst文件的数据量,哪些只有部分数据在查询区间的sst文件,可以简单地认为影响不大。
降低延迟、提升范围查询性能
Prefix Bloom Filter
跟Surf目标类似。用于Facebook社交网络存储场景,该场景下range查询范围前缀往往是uid之类的。
减少delete和update带来的Tombstone
UDB的应用里面有频繁的二级索引的索隐裂更新的情况,这意味着会有二级索引表的旧主键的delete。Delete标记要到compaction到最后一层时才会真正消除,比如一个key的修改历史是:v0=0, v1=1, v2=2, v3=DELETE。为了尽快消除这一行记录,MyRocks引入了一个特殊的删除类型 SingleDelete,如果用户可以确认本次删除key前,这个key只有一个版本,那么compaction时,就可以直接删除,不需要等compaction到最底层。于是二级索引key的修改就变成了 SingleDelete(old_sk) + Put(new_sk)。
基于Tombstone触发Compaction
如果某些sst文件里面的tombstone太多,RocksDB就会触发compaction,称之为Deletion Triggered Compaction(DTC)。
空间和Compaction的挑战
内存占用
Bloom Filter配置为每个key 10个bit,总的内存占用会比较大。这里允许RocksDB最后一层不创建bloom filter,层间乘数是10的话,那么bloom filter就可以减少90%的内存占用。当然这会导致最后一层检测唯一键不存在的情况成本变高。
SSD Slowness Because of Compaction
SSD trim指令是通过标记元数据删除来实现删除效果,实际数据并不需要删除。RocksDB的compaction触发大量删除时,可能导致trim指令卡顿。解决方法是删除文件时限速。同时Compaction限速也会控制后台compaction对前台用户IO的影响。
Physically Removing Stale Data
为了真正物理删除一行数据,而不是仅仅将delete标记compaction到L1L2,引入了Periodic Compaction,在发现有数据存在时间超过阈值时,触发compaction到最底层。
Bulk Loading
使用RocksDB的 File Ingestion API直接创建Lmax的sst文件,但前提是导入的数据本身是有序的。
使用MyRocks的其他收益
Online Backup and Restore Performance
- MyRocks的long running快照成本更低,InnoDB得构建很长的undo log。
- MyRocks从逻辑备份中恢复更快,因为可以使用bulk loading。
- 物理备份:checkpoint会硬链接sst和wal,然后追日志,追日志的过程可能很长,这时可以re-checkpoint,然后只发送新硬链接的sst文件。
Scales Better with Many Secondary Indexes
MyRocks操作二级索引时,不需要发起随机读。
二级索引插入=>Put;二级索引列修改=>SingleDelete&Put;二级索引删除=>SingleDelete。
Replace and Insert Without Reads
SQL的REPLACE语法含义是如果存在则删除旧值插入新值,否则直接插入新值。MyRocks的盲写跟这个语义是一样的,所以可以直接用RocksdDB的Put接口,省掉了一次随机读的开销。
对于INSERT语句,MyRocks也提供了选项跳过唯一性检查,但是用户要自己承担数据不一致的风险。
More Compression Opportunities
RocksDB支持每个level使用不同的压缩算法,Lmax使用压缩率高的算法,其他层使用性能好的压缩算法或者不压缩。
产品迁移
MyShadow - Shadow Query Testing
Capture and replay.
Data Correctness Checks
三种模式:Single、Pair、Select。
Single模式:验证主键和二级索引的一致性。
Pair模式:InnoDB和MyRocks实例取相同的快照(基于同一个GTID点),然后检查行数以及主键的checksum。
Select模式:类似于Pair模式,使用MyShadow捕获的查询来验证两个实例。
修复不兼容的Query
InnoDB和MyRocks的隔离级别实现有差异。InnoDB默认用的是Repeatable Read,换成MyRocks之后,业务产生了更多的错误。最后是通过和业务开发沟通,让业务改用Read Committed。
真正迁移
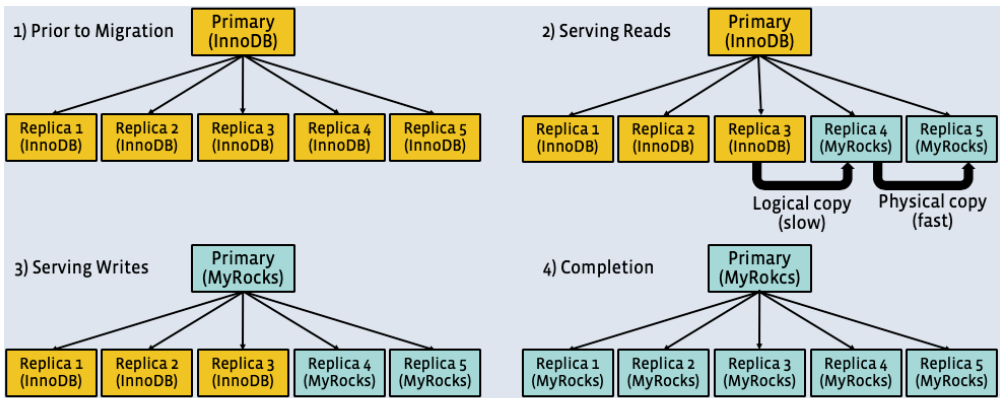
切成master还比较难,需要一些信念 It required a leap of faith that。
迁移效果
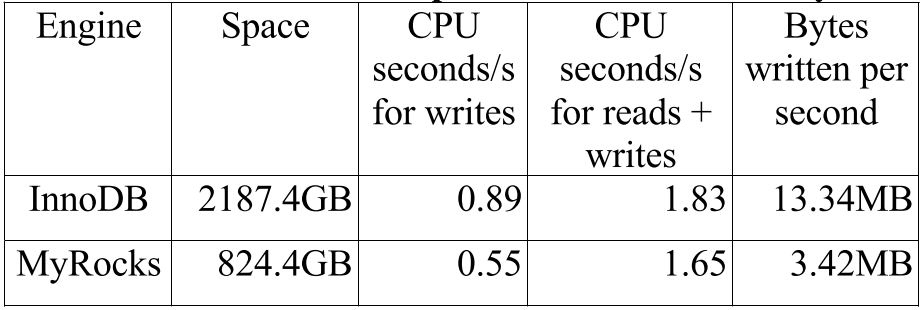
MyRocks空间占用是InnoDB空间占用的37.7%(2187.4 vs 824.4),其中InnoDB使用了压缩格式。最初压缩率大概是50%,后来将压缩算法从Zlib改成Zstandard并且加了PeriodicCompaction,进一步降低了空间占用。
如果不提供读服务,仅作为备库接收复制输入,MyRocks的CPU效率比InnoDB高40%(0.89 vs 0.55)。
有读流量时,MyRocks花费的CPU略低于InnoDB(1.83 vs 1.65,1.65指用了1.65个CPU)。
HBase迁到MyRocks
参见Facebook工程团队写的文章:
Lessons Learned
迁移工程
Production Engineers迁移经验丰富,他们应该在早期参与进来。
做存储引擎的工程师需要对存储组件、Linux内核的相关背景知识比较熟悉,当成黑盒可能会让我们错失一些优化手段和调试手段。
异常点不应该被忽视。
SQL兼容对于迁移引擎能成功是非常重要的。
RocksDB有相当多可调参数,通常跟workload紧密相关,很难调好。
Memory Stall and Efficiency
RocksDB对内存分配器更敏感,MyRocks使用了jemalloc,这一点很重要。
RocksDB之前用Buffered IO加fadvise hint,依赖Linux的page cache。这可能导致两个问题:事务提交时因为page cache分配内存导致stall,Linux内核内存可能触发Swapping。Linux内核最好升级到4.6版本。
MyRocks后面增加了DIO功能,减少对Linux内核的依赖。还有一个问题是要避免混用Buffered IO和DIO。
一点总结
从零开发一款存储引擎需要相当大的资源支持和足够的耐心,这对商业公司来讲是个不小的挑战。
RocksDB作为一个KV存储,应用已经相当广泛。Facebook在MyRocks上的工作,对于RocksDB在TP领域的应用是有质的推进的。
值得关注到的是,RocksDB上线牵扯了多个部门,众多工程师的参与。整个过程中有很多case by case的推进方式,这对于公司内部业务来说,评估投入产出比容易很多,毕竟节省多少硬件资源比较容易估算,也因此更容易获得业务的支持。