Orca优化器
《Orca: A Modular Query Optimizer Architecture for Big Data》 SIGMOD 2014
Orca是Pivotal数据管理系列产品(包括 Pivotal Greenplum Database和Pivotal HAWQ)共用的优化器模块,面向AP负载,整合了当时最新的技术。
Orca的主要特点:
- Modularity 对元数据和系统描述进行抽象,因此可移植
- Extensibility 将所有的查询元素和优化操作当做first class citizen,避免多阶段优化
- Multi-core Ready 优化过程的subtask可以调度到多核上并行执行
- Verifiability 可验证性
- Performance 高性能
Orca架构
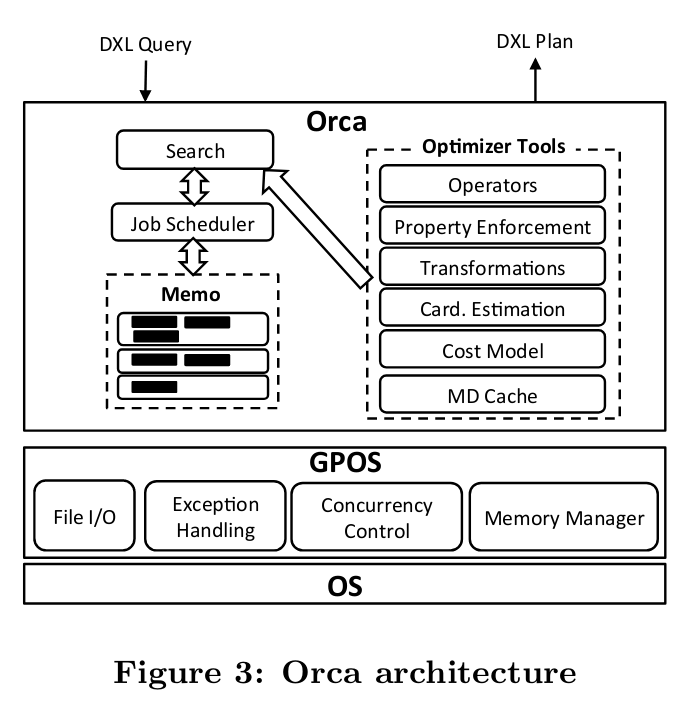
上图为Orca的架构,包含DXL,Memo,Search和 Job Scheduler,Transformation,Property Enforcement,Metadata Cache,GPOS。我们分别看一下。
DXL
Orca为了做到模块化可移植,解耦了优化器在数据库中上下游接口,采用了新的交互数据语言DXL(Data eXchange Language)。
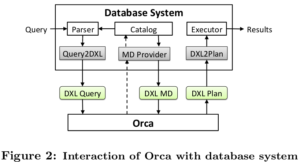
以查询 SELECT T1.a FROM T1, T2 WHERE T1.a = T2.b ORER BY T1.a;为例,DXL Query为(Mdid为metadata id):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
<?xml version="1.0" encoding="UTF -8"?> <dxl:DXLMessage xmlns:dxl="http://greenplum.com/dxl/v1"> <dxl:Query> <dxl:OutputColumns> <dxl:Ident ColId="0" Name="a" Mdid="0.23.1.0" /> </dxl:OutputColumns> <dxl:SortingColumnList> <dxl:SortingColumn ColId="0" OpMdid="0.97.1.0"> </dxl:SortingColumnList> <dxl:Distribution Type="Singleton" /> <dxl:LogicalJoin JoinType="Inner"> <dxl:LogicalGet> <dxl:TableDescriptor Mdid="0.1639448.1.1" Name="T1"> <dxl:Columns> <dxl:Ident ColId="0" Name="a" Mdid="0.23.1.0" /> <dxl:Ident ColId="1" Name="b" Mdid="0.23.1.0" /> </dxl:Columns> </dxl:TableDescriptor> </dxl:LogicalGet> <dxl:LogicalGet> <dxl:TableDescriptor Mdid="0.2868145.1.1" Name="T2"> <dxl:Columns> <dxl:Ident ColId="2" Name="a" Mdid="0.23.1.0" /> <dxl:Ident ColId="3" Name="b" Mdid="0.23.1.0" /> </dxl:Columns> </dxl:TableDescriptor> </dxl:LogicalGet> <dxl:Comparison Operator="=" Mdid="0.96.1.0"> <dxl:Ident ColId="0" Name="a" Mdid="0.23.1.0" /> <dxl:Ident ColId="3" Name="b" Mdid="0.23.1.0" /> </dxl:Comparison> </dxl:LogicalJoin> </dxl:Query> </dxl:DXLMessage> |
Memo
就是指Cascades里面的Memo,也就是Columbia里面的Search Space。
Memo以Group为元素组织起来,每个group包含一组等价的表达式(包含逻辑表达式和物理表达式)。一些Group以其他Group为输入。
Search and Job Scheduler
类似于Columbia的Task,不同Task可以是生成新的等价表达式,或是转为物理表达式,或是计算代价。
Transformations & Property Enforcement
与Columbia类似的概念。
这里的enforcement除了sort order外,还包括数据分布相关的属性,因为GPDB是MPP架构。
GPOS
为了与不同的底层OS交互,Orca对OS也做了抽象层。GPOS包括内存管理、并发控制原语、异常处理、文件IO和同步数据结构。
查询优化
查询优化过程
还是前面这个查询,假设T1表按Hashed(T1.a)分区分布,T2按Hashed(T2.a)分区分布。
Orca的输入是前述的DXL文件,然后解析成逻辑表达式树,拷贝到Memo中,如下图。

然后优化执行如下的一些步骤:
Exploration
应用transformation rule来生成等价的逻辑表达式,如JOIN交换律,生成的结果加到已有的group,也可能生成新的group(比如Join结合律[AB][C]=[A][BC] 会新生成[BC])。 Memo支持去重,去重方式是一句表达式拓扑。
Statistics Derivation
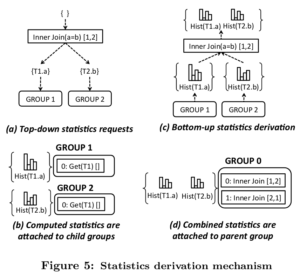
Exploration完了之火,Memo包含了所有的等价的逻辑表达式。这一步用于生成每个group的结果的统计信息,一般就是一组列的直方图。
对于一个给定的group,估计其统计信息的时候,优先选择group中简单的表达式,因为越简单对统计信息的估计越准确。因为group以其他group为输入,所以在估计其统计信息的时候会递归先对其input group进行估计,然后在合并估计当前group的统计信息。从对象管理角度,统计信息挂在group上,而且可以增量式更新(比如新增一个列的统计信息)。
Implemetation
到这一步,开始根据implementation rule将逻辑表达式转换成物理表达式,例如 Get2Scan rule可以将逻辑Get转换为物理Scan,InnerJoin转为InnerJoin2HashJoin或者InnerJoin2NLJoin。
optimization
这一步开始进行property enforce和代价估计。
实现上,定义向group发出optimization request,其含义是 在group中生成满足request条件的最小代价的计划。
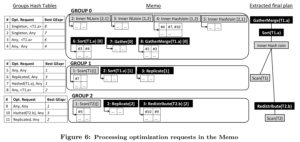
初始请求为 req#1 : {singleton, <T1.a>} 含义为:查询结果需要汇总到master节点(GPDB里的master节点类似于proxy,计算层前面的一层),且要按T1.a排序。
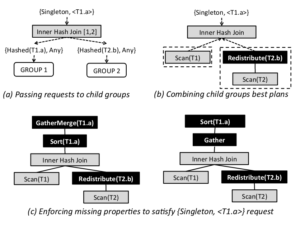
上图显示了req #1 的优化过程。对于req#1,其中一个可选的计划是按照join条件进行对齐分布然后做hash join。所以在(a)中向group 1发送了req#7 : {Hashed(T1.a), Any} 请求(any表示结果的order可任意),向group 2发送了 req#10 : {Hashed(T2.B), Any}。因为T1本来就是按T1.a分区的,所以直接使用Scan,T2需要redistribute。最后在group 1上添加enforcer。最终的计划从root group开始自上而下提取。
并行查询优化
这里是指优化过程本身的并行化。
优化过程拆成多个小的task,主要有如下几类:
- Exp(g):生成group g中每一个表达式的等价的逻辑表达式
- Exp(gexpr):gexpr指group的最佳expr,也就是Columbia的winner。这个任务是生成gexpr的等价的逻辑表达式
- Imp(g):生成group g的所有表达式的物理表达式
- Imp(gexpr):生成gexpr的等价的物理表达式
- Opt(g, req):返回group g满足request req的最佳plan
- Opt(gexpr, req):返回gexpr的满足request req的最佳plan
- Xform(gexpr, t):应用规则t到gexpr
一个SQL语句的优化过程可能产生数百个task,某些task之间可能会有依赖,不能并行。比如parent task和child tasks之间,但几个child tasks可以并行。
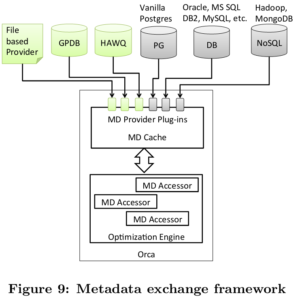
MetaData Exchange
Orca与MetaData之间的数据交互。
Verifiability
Orca开发时就考虑到了测试问题,尤其是确保不要回退。
两个工具:AMPERe、TAQO。