DISTINCT P FROM Patient p IN Patient_Set WHERE p.sex == 'male' AND EXISTS (SELECT r FROM Medical_recrod r IN p.get_medical_record() WHERE r.get_date() < '10/10/89' AND (r.get_diagnosis() == 'Malaria' OR r.get_diagnosis() == 'Smallpox'));
Query在内部用Query Graph Model (QGM) 来表示,QGM表达能力很强,支持任意的表操作,它的输入和输出都是表。
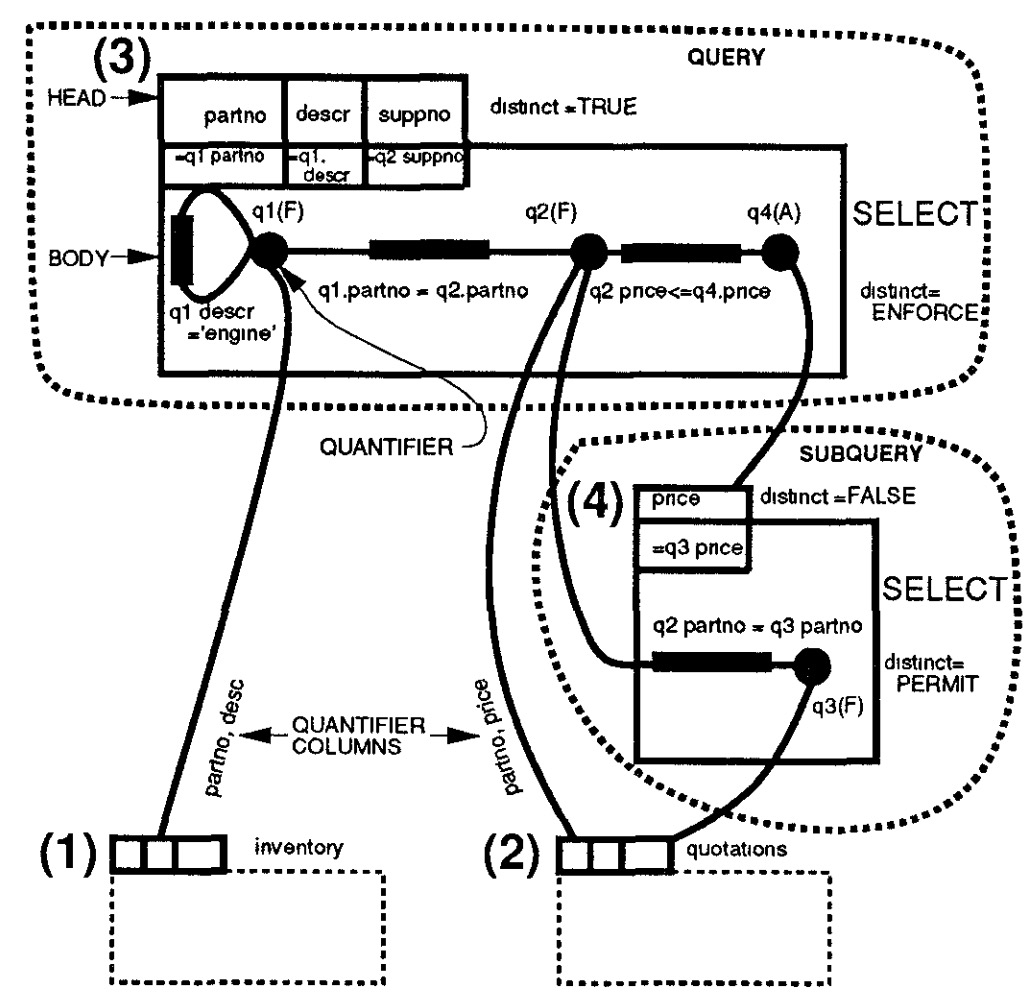
例如如下的查询
1 2 3 4
SELECT DISTINCT q1.partno, q1.descr, q2.suppno FROM inventory q1, quotations q2 WHERE q1.partno = q2.partno AND q1.descr = 'engine' AND q2.price <= ALL (SELECT q3.price FROM quotations q3 WHERE q2.partno = q3.partno);
if ( in a SELECT box(upper box) a quantifier has a type F AND ranges over a SELECT box(lower box) AND no other quantifier ranges over lower box AND (upper.head.distinct = TRUE OR upper.body.distinct = PERMIT OR lower.body.distinct != ENFORCE ) ) { merge the lower box into upper box; if(lower.body.distinct = ENFORCE AND upper.body.distinct != PERMIT) { upper.body.distinct = ENFORCE; } }
例子:
1 2 3 4 5 6 7 8
CREATE VIEW itpv AS (SELECT DISTINCT itp.itemn, pur.vendn FROM itp, pur WHERE itp.ponum = pur.ponum AND pur.odate > '85');
SELECT itm.itmn, itpv.vendn FROM itm, itpv WHERE itm.itemn = itpv.itemn AND itm.itemn >= '01' AND itm.itemn < '20';
Rewrite后的结果:
1 2 3 4 5
SELECT DISTINCT itm.itmn, pur.vendn FROM itm, itp, pur WHERE itp.ponum = pur.ponum AND itm.itemn = itp.itemn AND pur.odate > '85' AND itm.itemn >= '01' AND itm.itemn < '20';
这样,查询优化器就可以从新的查询将view的内部查询考虑进去进行优化。
Rule2. Distinct Pullup (DISTPU)
1 2 3 4 5 6 7 8
if (in a SELECT box either quantifier-nodup-condition or one-tuple-condition holds for all F quantifier) { head.distinct = TRUE; body.distinct = PERSERVE; }
/* DISTPDFR */ if (in a box with type SELECT, UNION, INTERSECT or EXCEPT, body.distinct = PERMIT or ENFORCE) { for (each F quantifier in the body) quantifier.distinct = PERMIT; }
/* DISTPDTO */ if (in a box with type SELECT, UNION, INTERSECT or EXCEPT, all quantifiers ranging over the box have quantifier.distinct = PERMIT) { body.distinct = PERMIT; }
这条rule也比较简单,如果查询允许重复,那么例如子查询等quantifier也不必去重。
Rule4. E or A Distinct Pushdown From (EorAPDFR)
1 2 3 4 5
if (in a SELECT box a quantifier has type = E or A) { quantifier.distinct = PERMIT; }
意指quantifier如果是E或者A量词,则quantifier本身可以不去重。
Rule5. Common Subexpression Replication (BOXCOPY)
公共子表达式复制。
1 2 3 4 5 6 7
if (in a SELECT box more than one quantifier range over the box) { make a copy of the quantifiers ranging over the original box and change it to range over the new copy; }
Rule6. Add keys (ADDKEYS)
1 2 3 4 5 6 7 8 9 10
if (in a SELECT box head.distinct = FALSE) { for (each F quantifier) if (the key of the F quantifier does not appear in the output) { Add the key to the head; head.distinct = TURE; } }
if (in a SELECT box there is a quantifier of type E forming a Boolean factor AND ( head.distinct = TRUE OR body.distinct = PERMIT OR one-tuple-condition ) ) { set quantifier type to F; if (one-tuple-condiftion is FALSE AND head.distinct = TRUE) { body.distinct = ENFORCE; } }
例子:
1 2 3 4
SELECT * FROM itp WHERE itp.itemn IN ( SELECT itl.itemn FRO itl WHERE itl.wkcen = 'WK468' AND itl.locatio = 'LOCA000IN');
Rewrite后的结果:
1 2 3
SELECT DISTINCT itp.* FROM itp, itl WHERE itp.itemn = itl.itemn AND itl.wkcen = 'WK468' AND itl.locatio = 'LOCA000IN';
Rule8. INTERSECT to Exists (INT2EXIST)
将INTERSECT查询改写为EXISTS子查询,进而通过EtoF改写为SELMERGE。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
if ( in an INTERSECT box body.distinct != PRESERVE) { set the box to be of type SELECT; choose an arbitrary quantifier Q1; /* Q1 will keep tyoe F */ for ( each quantifier Q != Q1 in the box) { Q.type = E; add the predicate EXISTS ( SELECT * FROM Q WHERE Q1.c1 = Q.c1 AND Q1.c2 = Q.c2 AND ... Q1.cn = Q.cn ); } }