《An Overview of Query Optimization in Relational Systems》PODS 1998, Microsoft Research
优化器的输入是用户查询,负责生成一个高效的执行计划,优化过程是一个比较复杂的过程。
优化器主要包含三个部分:
- Search Space:搜索空间包含足够好的计划
- 代价估计:代价估计足够精确
- 枚举算法:枚举算法要足够高效
System R优化器案例
以System R为例来初步看下优化器的这三部分,通过这一节,对优化器有个初步的认识。
这里假设只考虑Select-Project-Join类型(SPJ)的查询优化。
Search Space
A B C D四张表JOIN,可以是linear或者bushy方式,因为JOIN满足结合律和交换律。另外,每个JOIN操作可以使用Nested Loop或者Sort-Merge的implementation。所以Search Space比较大。
代价估计
代价模型会给执行计划或者执行计划的片段做代价估计,同时也会估算输出结果的集合大小。
代价模型依赖如下信息:
- 表/索引上的统计信息,例如页面数目、distinct value等
- 估计谓词的selectivity和算子输出结果大小的公式,例如join的输出结果大小估计值为两表大小乘积再乘以谓词的selectivity。
- 估算每个算子执行时消耗的CPU和IO代价公式。
枚举算法
System R的枚举算法使用了动态规划和interesting order两种技术。
动态规划基于最优化原理,以3表join为例,3表join的最优join order的其中两表join order一定是两表join最优的(否则就可以找到更优的替换非最优,从而得到一个更优的最终结果)。System R采用bottom-up方式,如果要找到K表join最优,就要先找到K-1表最优,然后再计算包含第K张表最优的结果。
Interesting order是指类似如下的情况:R1 R2 R3三表在R1.a = R2.a = R3.a 上JOIN,R1 R2的JOIN可以使用nested loop或者 sort-merge,假如nested loop开销更小,我们就剪枝sort-merge的计划,但实际上,如果选择sort-merge,则R1R2的结果是按a列有序的,后面再JOIN R3可能整体开销更小。
Search Space
search space是根据transformation来扩展的。transformation本身不一定能降低优化过程开销,所以要和基于代价的枚举算法结合来降低优化过程开销。
算子之间的交换
一大类tranformation是进行算子之间的交换。
Generalizing Join Sequencing
JOIN操作满足交换律和结合律,因此可能导致search space非常大,很多系统只考虑其中一部分。例如System R只考虑linear sequence join。除了linear sequence join,有些系统还多考虑了一部分的bushy join,bushy join是形如 (A⋈B)⋈(C⋈D)的join。
Outerjoin and Join
以left outer join (LOJ)为例,LOJ不能自由地交换,但是满足如下的规则:
JOIN(R, S LOJ T) = JOIN(R, S) LOJ T
Group-By and Join
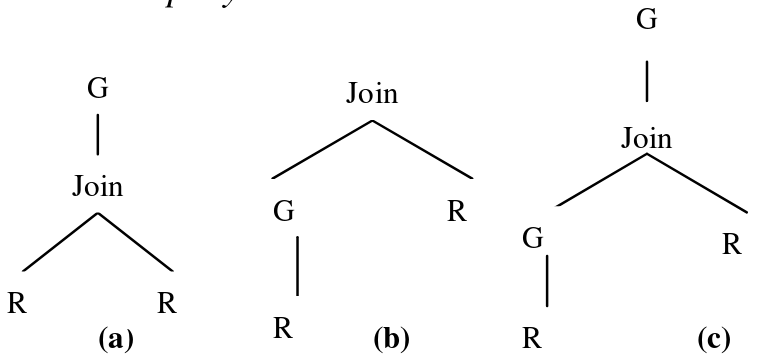
如图(a)中的G可以下推到左边的R。但JOIN完是否需要再G一次(即(b)和(c)),取决于下推的G结果和右R join情况,如果G结果的每一行最多和右R的一条记录join,则不需要JOIN完再G。
将多Block查询规约为单Block查询
Merging Views
如果查询Q=JOIN(R, V),其中V=JOIN(S,T),则可以将V展开到Q中Q=JOIN(R, JOIN(S, T)),这样就可以自由重新考虑join order。
但这种merging在V定义比较复杂的时候不一定可以简单地展开,比如V是SELECT DISTINCT。
Merging Nested Subqueries
诸如:
1 | SELECT Emp.Name |
转换为
1 | SELECT E.Name |
如果内查询没有引用外查询的变量,即uncollated情况,则内查询只需要计算一次。
如果是collated情况,则可以将嵌套子查询展平成单个查询。
一些嵌套子查询可以视为SemiJoin,并按照如下变换进行merge:
SemiJoin(Emp, Dept, Emp.DeptNo = Dept.DeptNo) = Project(Join(Emp, Dept), Emp.*)
如果包含了aggregate操作,pullup GroupBy之类的操作就需要小心。
1 | SELECT Dept.name |
该查询中,假设某个dept d在Emp中不存在,则d会出现在最终结果中。但如果直接改为单个join查询,d就不在结果中。所以这里换成等价的单查询的结果应当是:
1 | SELECT Dept.name |
使用类SemiJoin技术来优化多Block查询
略。
统计和代价估算
代价是优化器比较plan的依据,因此代价越准确优化器才可能更好。
估计框架:
- 收集数据的统计信息汇总
- 给定一个算子和该算子各输入数据流的统计信息,估计算子输出的统计信息 和 执行该算子的代价。
这里的统计信息是指逻辑属性,例如表中的行数;代价是物理属性,例如消耗多少CPU。前者在不同计划下是相同的,后者不一定相同,例如A JOIN B结果行数是确定的,但可能hash join和nested loop join的代价可能相差很多。
如果一个算子的代价计算出来了,则整个计划的代价就是plan中所有算子的代价总和。
统计信息
统计信息除了行数目信息外,还可能包括页面数量。
列上的统计信息在列上谓词估计selectivity比较有用。
很多系统的统计信息以直方图来表示,(等高/等宽)直方图可以用来估计数据分布。但直方图无法反应列之间的关联,2D直方图(联合分布)可以做到,但空间占用也比较多。
一般用采样sampling的方法。采样方法会有误差,尤其是distinct value的估计很容易出错。
代价计算
代价包括CPU/IO,在分布式环境下,还包括通信开销。
枚举架构
枚举算法架构需要支持可扩展性,即支持新增transformation和新增物理算子。
这里介绍两种 Starburst 和 Volcano/Cascades,其共性特点有
- 使用泛化的代价函数 和 物理属性
- 使用规则引擎
- 提供调节开关
Starburst
Starburst内部采用Query Graph Model来表示查询。
优化的第一个阶段是query rewrite,根据rule将一个QGM转成另一个QGM。Rule包含apply condition检查和具体apply的方法。
优化的第二个阶段是query optimization,Starburst用了一种类文法的思路来推导可能的最终执行计划,推导过程中会根据代价进行剪枝。其中JOIN顺序的枚举类似于System R的bottom-up。
Volcano/Cascade
二者类似,都是从Exodus演化来的。
规则分为transformation rule和implementation rule,前者用于进行逻辑转化,后者用于生成物理表达式。
Volcano/Cascade采用动态规划方法,top-down方式。在要去优化某个子任务时,先去看下以前是否已经优化过(memorization),否则就使用transformation rule、implementation rule、enforcer生成新的表达式。每个过程中都通过规则的promise来进行下一步的转换。
Volcano/Cascade和Starburst的差异主要是:
- 不需要将优化过程分为两个阶段,因为所有的转化都是代数表达式转换,而且都可以用基于代价的方式。
- 从逻辑表达式到物理表达式就是其中的一个普通的转换。
- 采用goal-driven的顺序应用rule
Beyond The Fundamentals
分布式和并行数据库
引入了网络通信开销,搬迁数据算子,选择计算节点等。
User-Defined Functions
存储过程(也叫用户定义函数 UDF)在优化阶段可能会比较麻烦。比如查询中的谓词用到了一个UDF,那可能就不能尽早执行这个谓词判断。一种思路是将UDF视为一张关系表进行动态优化;另一个思路是如果UDF中没有JOIN,可以按UDF的rank 排序,其中rank取决于selectivity等。
Materialized Views
新问题是将物化视图考虑进来后,如何进行优化。
首先是将查询重写为使用一个或多个物化视图的等价查询比较困难,其次是如果是两阶段优化(先枚举所有逻辑表达式再转换物理表达式)下,有物化视图后,基于代价的剪枝会变复杂。
其他问题
延后生成完整的执行计划;
考虑其他资源,如内存;
面向对象系统下的优化过程;
多媒体和web场景下的优化问题。
总结
文章比较精简概括,但主干脉络总结的很好。
扫描二维码,分享此文章