这是SIGMOD’21 上的论文《Rethink the Scan in MVCC Databases》,论文针对像HTAP等场景下可能出现大量versioned data中执行scan慢的问题提出了一种比较有效的方案。
Scan性能问题
首先,论文看到了这种场景下scan慢的一个重要原因:
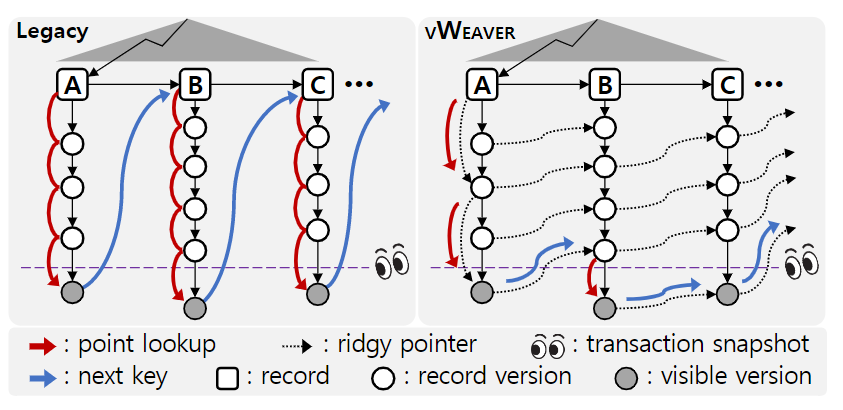
Scan的时候,每一个key都要分别从自己的多个版本里面做一次线性查找,找到当前读快照可见的版本。
这个过程中假如有一种ridgy pointer,用于从key A的可见版本数据直接跳转到下一个key的可见版本数据(或者临近版本),则scan操作性能就会大幅提升。
为此,论文要解决两个问题:
第一个问题是,per-chain内加速搜索(例如上图右侧key A从A最新版本跳过次新版本)。
第二个问题是,相邻key的per-chain之间建立k_ridgy pointer。
两个优化问题
per-chain内加速搜索
首先第一个问题本质上是线性有序链表加速查找的过程,论文提出了一种新的跳表 frugal skip list。
frugal skip list也是一个概率查找数据结构,查找性能与普通skip list一样,都是O(logN)的。但如其名所描述,比普通skip list要节省很多指针空间。
frugal skip list加速查找示意图如下
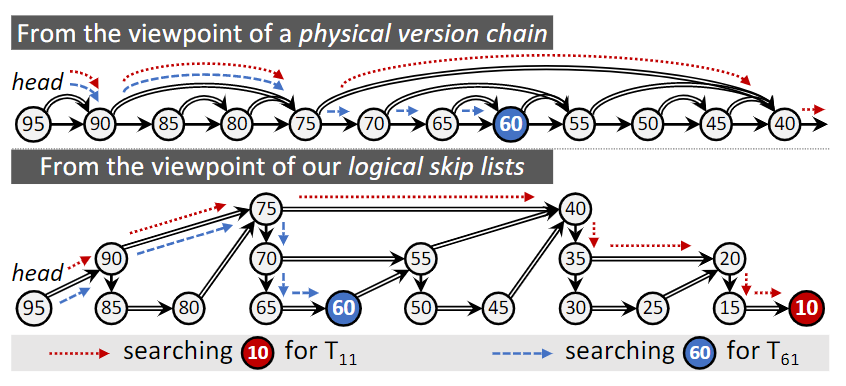
关键还是新增的v_ridgy指针(v指version,per-chain内节点加速)。
v_ridgy指针插入的流程如下
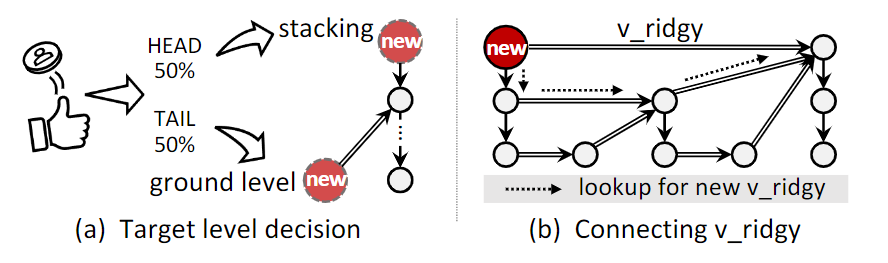
首先新节点以50%的概率成为一个新的最底层节点,50%的概率成为一个有序链表中其后继节点所在version stack的head。不管是底层还是head,设置其ridgy pointer时,要求都是一样的:新节点N的ridgy pointer指向的节点是N向前(这里向前是指per-chain的old version方向,也就是原始version chain的单链表指针方向)找最近的一个version stack,这个version stack满足stack top的节点的level比N高。
在这个规则下,ridgy skip list实际上类似于普通skip list的level pointer,注意到version stack达到高度h的概率是1/2^h,所以沿着ridgy pointer走实际上达到跳过了指数数量node效果。所以frugal skip list的查找过程也就容易映射到普通skip list了。
相邻key的per-chain之间建立k_ridgy pointer
第二个问题相邻key的per-chain之间建立k_ridgy pointer。
这里的核心诉求是保证两个不变式:key-free 和 version-free。
两个不变式的概念很容易理解,来自最开始的那个洞察。
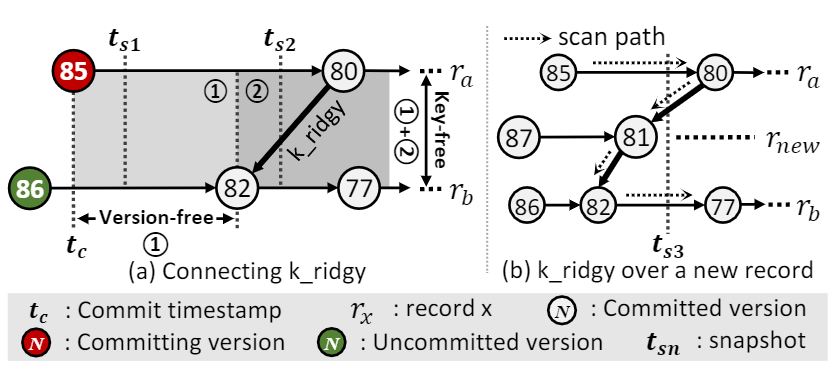
如图,既然ra80有一个k_ridgy pointer指向 rb82,就要求ra和rb之前不存在其他record,否则scan就会丢数据,这就是key-free。另外一点就是某个读快照如果可以看到ra80,则上述k_ridgy pointer必须保证该快照可以看到的rb版本不会比rb82新,也就是rb82往新的方向没有该快照可见的version,这就是version-free。
这种k_ridgy pointer的实现实际上也不复杂。如果数据结构本身是lock free的话,可能需要小心,在某些情况下,数据结构新增ridgy pointer应该也有机会做成lock free而不引入lock阻塞。
应用到实际系统的坑
这个思路应用到具体实际系统中,还有一些坑需要趟平。
论文给出了几个坑,并给出的解决方案。
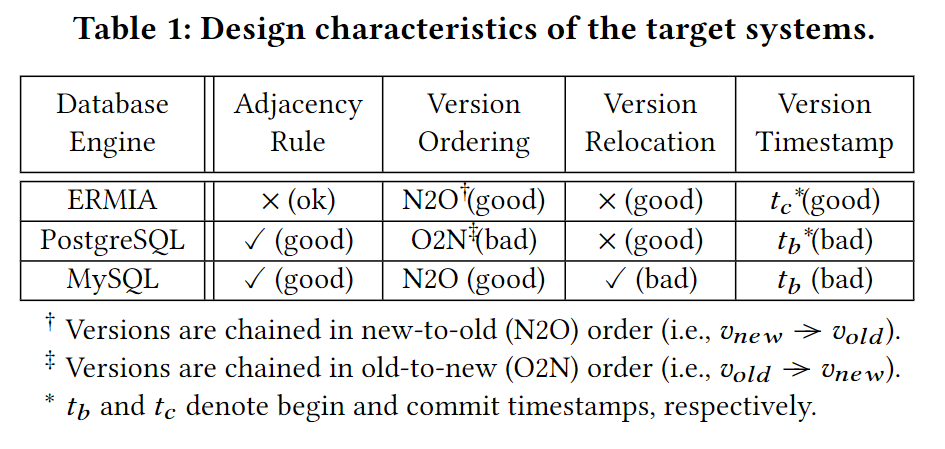
adjacency rule
也就是说有些数据结构不容易确定相邻key,比如in-memory hash结构。像MySQL InnoDB属于磁盘B+Tree,是可以很简单确定next record的。
ERMIA就有这个坑。ERMIA主体结构是一个masstree,但叶子上记录的不是raw record address,在叶子和raw record之间多一层indirection arrary。
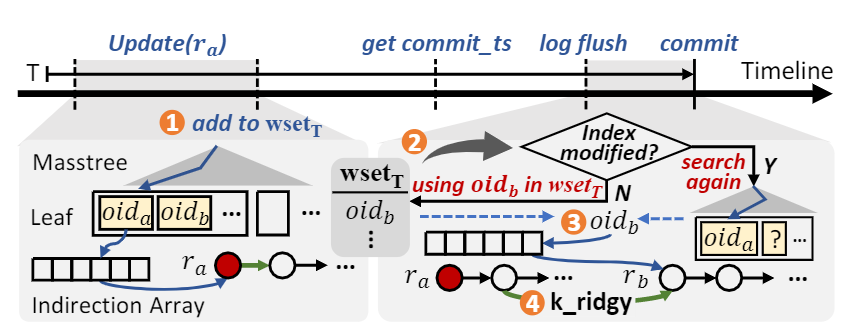
解决方法是在提交时保留待提交record在之前执行期间搜索的信息,把这个信息带到提交阶段即可。如果没有这个信息,就只能重新搜索了。
version ordering
version chain的方向是new2old(N2O),还是old2new(O2N)。
如果是O2N,就比较麻烦,一是要修改old version的ridgy pointer,这可能会引发IO,二是还要额外维护N2O的frugal skip list。
解决方法就是……重构这个索引系统,把它从O2N改为N2O,粗暴且彻底。
version relocation
像MySQL InnoDB,最新版本的数据在做一次修改后,就会被复制到undo space作为前镜像,原位置覆盖写入新值。但是旧版本一旦到了undo space,就不再relocate了,所以解决方法就是只在undo space内做ridgy pointer,然后新增backlink指向原页面记录。purge逻辑也要跟着调整。
verison timestamp
就是开启序和提交序的差异。开启序就麻烦很多,执行阶段就产生新版本,提交阶段设置k_ridgy的话,还要写redo(更新了undo page)。解决方法也是新增backlink,但解决起来也比较麻烦。详看论文。
一点总结
总之,论文提出了一个新的skip list,性能比肩原skip list但空间占用更省,然后针对versioned data上的scan,根据snapshot的洞察引入跨key的捷径k_ridgy pointer加速scan,同时将方法应用到实际系统,并克服了多个困难。
另外值得注意的是,该洞察也比较适合应用到In-Memory OLTP引擎、LSM Tree引擎中(即使具体到k_ridgy pointer不好应用)。
扫描二维码,分享此文章