Snowflake Elastic Data Warehouse
《The Snowflake Elastic Data Warehouse》 SIGMOD 16'
Snowflake具备如下的特点:
- 纯粹的SaaS体验:用户将数据放到云上,然后可以通过snowflake对他们的数据进行查询。
- 关系型:支持SQL和ACID
- 办结构化:内置函数和SQL扩展来支持对半结构化数据的访问,自动schema discovery和列式存储
- 弹性:存储和计算资源可以独立无缝弹性,不影响数据可用性和当前查询性能
- 高可用:容忍node、cluster和data cent宕机,软硬件升级无downtime
- 持久性:通过clone、undrop、跨region备份保证数据持久性
- 经济成本:数据压缩,计算高效,按需付费
- 安全:所有数据包括临时文件和网络都是端到端加密,基于角色的访问权限控制机制可以精细到SQL粒度
Storage Versus Compute
shared-nothing架构在曾在数仓领域占据主导地位,主要因为可扩展性和基于普通商用硬件。
但是shared-nothing架构的主要问题是以单个机器节点为粒度,计算资源和存储资源紧耦合,这会带来一些麻烦:
- 异构负载:硬件是同构的,但负载不是。批量加载的场景和复杂计算的场景对资源的要求差异巨大。
- 成员变更:数据需要大规模reshuffle数据。
- 在线升级:升级影响服务,实际上是有能力做到升级完全无感知。
云计算时代,背景有些变化:云服务商提供了多种规格的计算资源,可以物尽其用;机器节点失效不再是异常,而是预期内的常态;升级无感知和弹性也是强需求。
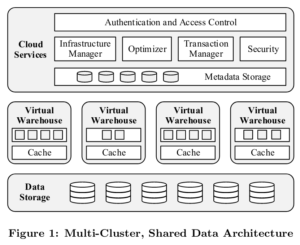
Snowflake架构
Snowflake是service-oriented架构,由多个容错和独立扩展的服务组成,服务之间用RESTful接口交互。整体分为三层:
- Data Storage:使用AWS S3存储数据表和查询结果
- Virtual Warehouses:系统的肌肉部件,负责处理查询执行和资源弹性
- Cloud Services:系统的大脑部件
Data Storage
存储层选择S3的原因:
- S3在云厂商中比较成熟
- AWS客户本身也多,这样可以为snowflake提供潜在客户
- S3在易用性、高可用、高持久性保证方面都很出色,性能在一些方面也很好
因此,与其自研一个类似的S3/HDF存储系统,不如在S3基础上搞,再将精力投入到local cache、skew resilient进行性能加强。
但真选择了这条路的话,也要面对S3的各种问题:
- S3的读写延迟很高,如果用HTTPS接口访问,CPU消耗也很高。
- S3是blob存储,仅支持简单的基于HTTPS的简单的PUT/GET/DELETE接口,文件要整体覆盖写,甚至不支持追加写,但S3支持读取部分内容。
这对Snowflake的存储格式设计影响比较大。Snowflake中表水平分区,每个分区对应的文件都比较大,分区文件不可变,文件采用自解释的高压缩列式存储格式,查询读取时只读取所需要的部分内容。
临时表先存到本地存储,如果满了也会再外溢到S3存储上。
Virtual Warehouses
Virtual Warehouses层包含了EC2实例集群,整体对外表现为一个VW(virtual warehouse),其中每个EC2叫做worker node。VW规格相对固定,只有X-Small 、XX-Large等规格,客户对具体内部EC2不感知。
这种靠近用户的抽象有利于封装IaaS层细节,有利于系统演化。
弹性和隔离
VM是纯计算资源,无状态,因此很容易创建、销毁,实现弹性。查询不会跨多个VW,这样可以实现强性能隔离,不过如果允许worker node在VW之间共享,则可以进一步提高利用率。查询发送到VW后,VW内的每个worker node上都会创建一个进程服务该查询,进程生命周期与该查询生命周期一致。各个进程不会影响S3上的原始数据,因为这些数据是immutable的。
Snowflake现在还不支持failure retry,未来会支持。
用户可以有多个VW,每个VM都可以运行多个查询,数据是共享的,不需要物理拷贝。共享的无限存储意味着可以共享和集成所有的数据,这也是数据仓库的核心原则之一。
弹性的另外一个点是同样的价格成本可以带来完全不同的性能体验。比如某个data load工作,如果用4个node需要15小时,改用32个node后需要2小时,总体价格成本差不多,但是用户体验好了很多。也就是说,“一个人怀胎十月可以生小孩,十个人怀胎一月不能生小孩” 类型的问题在这里不存在。
弹性是Snowflake架构最大的优势和代差。
本地缓存和File Stealing
本地缓存使用的是本地存储,缓存了该node上查询所读取过来的S3的数据。这些缓存在该node的多个进程上共享。
优化器一定程度上感知VW内各node的本地缓存这一事实。优化器在生成计划时,会对分布式查询进行分发到各node,这个过程中会按对表名进行一致性哈希分发,这样不同查询的访问相同数据的查询片段就会落在同一个node上,该node的本地缓存效果就会好一些。
另外一个问题是数据倾斜。Snowflake采用了一种称作 file stealing的方法。当一个node完成了该node上的查询片段的scan之后,会去其他执行慢或者负担重的node上偷一个文件查询任务。以此来进行负载均衡。
执行引擎
分布式执行固然可以提高性能上限,但单机性能对系统效能(price/performance)影响非常大。
Snowflake的查询引擎的特点:
- 列式存储:列存更适合AP负载,可以显著降低IO开销,并充分利用SIMD指令。
- 向量化:pipeline风格,批量处理。
- Push模型:与volcano模型pull相反,采用了push模型;push模型cache友好,而且可以支持处理DAG形状的计划(对比tree形状的计划)。
Cloud Service
VM是短暂的资源组概念,相对而言,Cloud Service是比较重的组件,其中的访问控制、查询优化器、事务管理等都是长生命周期的,而且很多都是在多个用户间共享的。多租户提高了资源利用率,降低了管理开销。
查询管理和优化
所有的查询都先经过Cloud Service,查询的前几个阶段parser, resolver,access control和optimizer都在这里处理。
Snowflake的优化器是Cascades-style,top-down的CBO。统计信息在数据加载和更新的时候自动维护。因为Snowflake不适用索引,所以优化搜索空间小很多。还有一些如join的数据分布类型要到执行时才会确定。因此snowflake的优化器出错的情况比较少。
优化器生成执行计划后,将计划各片段发送到所有的worker node,Cloud Service负责监控这个计划的执行情况,包括性能数据和node failure监测,搜集的信息也会保存下来用于审计。Snowflake提供了GUI界面可以查看监控和分析。
Concurrency Control
并发控制过程完全在Cloud Service层处理。
Snowflake面向AP,主要处理大量读,批量插入/更新。Snowflake提供了ACID支持,隔离级别采用SI。
Snowflake中,更新要通过替换原文件来生效。
Pruning
剪枝是减少数据访问的方法之一。很多系统依赖索引,但索引在Snowflake中不合适,原因如下:
- 索引底层依赖随机读,但Snowflake的存储介质S3和数据压缩对随机读都不利
- 索引维护本身会带来存储空间开销和数据加载耗时
- 用户需要显式维护索引,增加了用户心智负担
索引的替代方案是 min-max based pruning,也叫 small materialized aggrgate, zone maps, data skipping。每个data chunk维护其分布信息,尤其是min-max。
这个方法非常适合Snowflake:不依赖用户输入;scale很好;容易维护。
FEATURE HIGHLIGHTS
纯Software-as-a-Service体验
Snowflake支持标准的JDBC/ODBC/Python PEP-0249各种接入标准,可以与大量的第三方工具集成如Tableau/Informatica/Looker,也支持直接通过Web操作。Web UI看似简单,实则很有用(应该是承担了很多管控的角色)。
此外,ease-on-use和服务体验一直是Snowflake的追求,隐藏节点失效、更少的调控参数、更少的物理设计、没有storage gromming tasks,所有的一切都仅仅紧扣数据和查询两个概念。
Continuous Availability
略
Semi-Structured and Schema-less Data
Snowflake扩展了SQL类型,新增三种 VARIANT、ARRAY、OBJECT。
VARIANT可以存储任意的标准SQL类型,也可以存变长的ARRAY和OBJECT,其中OBJECT和MongoDB的document是类似的。ETL的时候,用户可以将JSON、XML等load到VARIANT类型的列中。
Snowflake的ETL的优势:
- 支持schema later
- 需要transformation的时候,可以直接用snowflake的资源和SQL能力来做
Snowflake使用列存存放半结构化数据。
Time Travel 和 Clone
更新数据后,旧版本文件保留一段时间如90天,Snowflake支持Time Travel功能:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT * FROM my_table AT (TIMESTAMP => 'Mon, 01 May 2015 16:20:00 -0700'::timestamp); SELECT * FROM my_table AT(OFFSET => -60*5); -- 5 min ago SELECT * FROM my_table BEFORE (STATEMENT => '8e5d0ca9-005e-44e6-b858-a8f5b37c5726'); SELECT new.key, new.value, old.value FROM my_table new JOIN my_table AT(OFFSET => -86400) old -- 1 day ago ON new.key = old.key WHERE new.value <> old.value; |
undrop功能
|
1 2 |
DROP DATABASE important_db; -- whoops! UNDROP DATABASE important_db; |
clone:软引用,不会copy物理数据
|
1 2 |
CREATE DATABASE recovered_db CLONE important_db BEFORE( STATEMENT => '8e5d0ca9-005e-44e6-b858-a8f5b37c5726'); |
安全
Key Hierarchy
Key Life Cycle
End-to-End Security
Lession Learned
- 2012年Snowflake启动的时候,当时还有大量的SQL on Hadoop系统,做一个这样的AP有点冒险,但回看,Hadoop并没有取代RDBMS。
- 面向云的架构。
- 针对半结构化数据的工作现在看来是很有价值的。
- 研发Snowflake对团队来说难度并不太大,研发团队累计100年研发经历了,因此避免了很多重大弯路。
- 虽然无需调节就已经性能不错了,但有待进一步提升性能。
- 最大的技术挑战是SaaS和多租户方面。
- 演化过程有很多新问题。
- 未来最大的挑战是转为一个full self-service model。