《The Volcano Optimizer Generator : Extensibility and Efficient Search》1993
论文介绍了在EXODUS之后的一个新的优化器生成器Volcano。
一个好的optimizer generator要满足如下条件:
- 既能用到Volcano Executor,也能用到已经存在的其他执行器
- 优化的时间消耗和内存消耗都比较低
- 能够高效、可扩展地支持物理属性(如sort order、compression)
- 允许使用启发信息和数据模型语义来引导搜索和剪枝
- 支持灵活的代价模型
Design Principles
5个design decision
第一,关系系统上的查询处理是基于关系代数,其他如OO系统等的查询实际上也可以基于代数技术。通过定义代数算子、代数等价规则、实现算法等,可以使得非关系系统查询优化和执行采用关系代数类似的代数技术实现。
第二,规则是关于匹配模式和转换公式的说明,匹配模式要精确、模块化。在Volcona中,每个规则都是独立的。
第三,优化器在映射查询到执行计划的过程中所做的选择被表示为代数等价式。有一些系统会用到多种层次的中间表示,例如Grammar-like … 这篇论文提到的方法。但这种方法对于等价和转换的很多问题模糊掉了,例如优化器的输入、计划搜索方法、等价计划选择的次序等等。
第四,关于规则的解释执行和编译执行。解释执行灵活,编译执行高效。Volcano使用编译执行的方式。为了保持可扩展性,规则本身可以进行参数化。
第五,search engine基于动态规划。
Optimizer Generator Paradigm
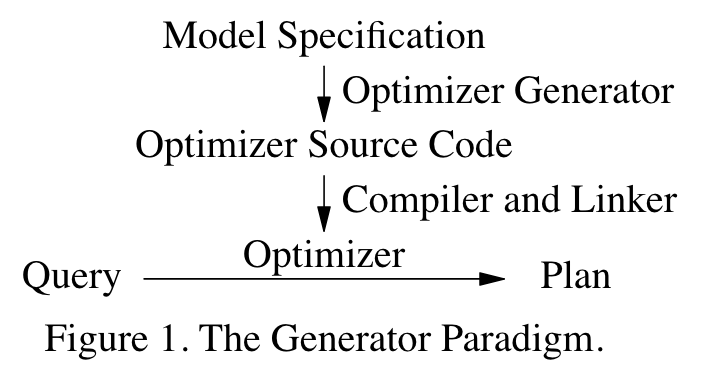
优化器的输入是Query,表示为logical operator的表达式(树),它来自parser的输出。优化器的输出是Plan,是physical operator表达式。
优化器的实现者需要提供如下积累信息:
第一,logical operator和physical operator。优化器就是将一个logical operator表达式映射为一个最优的等价的physical operator表达式,并选择算子具体的实现算法。
第二,代数transformation rule。表达式的等价交换律和结合律用transformation rule表示。
第三,algorithm和enforcer集合,algorithm指的是数据访问层的接口,等价于physical operator,enforcer类似于Starburst的glue。
第四,implementation rule。从operator到algorithm用implementation rule表示。rule需要支持复杂的映射,例如join+projection可能就映射到一个实现了。
第五,抽象数据类型cost,该类型支持互相比大小。这就是CBO优化器的代价类型。
第六,抽象数据类型logical property。它是指表的模式、预期大小等等,主要还是关系代数中的关系属性。与之对应的是physical property,是指记录顺序、分区等属性。
第七,抽象数据类型physical property vector,需要实现者定义,它是search engine搜索过程使用的类型,该类型支持比大小。
第八,每个algorithm和enforcer的application function,判断是否可以应用规则。一些physical operator没有对应的logical operator,例如sort、decompress,这些operator被称为enforcer,类似于Starburst的glue。
第九,每个algorithm和enforcer的代价函数。
第十,每个logical operator、algorithm、enforcer的property function。计算得出property的函数,包括得出logical property和physical property。
The Search Engine
1 | FindBestPlan (LogExpr,PhysProp, Limit) |
先检查结果缓存
FindBestPlan主要分为两部分,首先如果hashtable中已经有了一个满足输入表达式的physical property vector 和 cost的plan, 则直接返回,过程结束。如果不存在或者cost不满足要求,则开始执行优化过程。
搜索的Next Move
在某一时刻,输入的表达式有三种变化(move、搜索空间上的移动):
第一种是基于transformation rule;
第二种是有一些algorithm可以将输入的逻辑表达式转换,并满足physical property,例如针对无序数据的hash join、针对join列有序的数据的merge-join;
第三种是增加某些enforcer来支持其他操作,例如merge join可以通过sort enforcer在无序数据上做join。
下一步就是针对这些move的每一个,或者启发式方法选出一部分,进行搜索。具体是搜索全部move还是一部分move可由实现者决定。论文给出的搜索框架是搜索全部move。
第一种move(transformation rule)的处理:
根据transformation rule生成新的表达式,然后递归执行FindBestPlan。考虑到有些rules可能是互逆的操作,所以需要标记表达式in progress,以避免搜索出现回路。
第二种move(algorithm)的处理:
即遇到algorithm的move,这个algorithm的applicability function确定了其输入的physical property vectors。这时需要针对该algorithm的每一个输入,执行FindBestPlan。
例如,某个算法是sort-based intersection,它的两个输入是有序列表,总代价就是每一个输入的逻辑表达式的代价(递归FindBestPlan来求),再加上该algorithm本身的代价。
这里还有一个值得注意的点,对于一些binary operator,两路输入属性的一致性很重要。比如刚才的求交集算法,只要两路有序输入是相同的顺序即可,即都是从小到大或者都是从大到小。再比如parallel join,两个输入都是分区表,只要分区规则相同或者兼容,就可以方便地应用该算法。像这种情况,search engine也需要考虑到。
第三种move(enforcer)的处理:
enforcer实际上会修改某个或某些physical property,其代价包含enforcer本身的代价,再加上根据logical expression获得新的physical property的代价(这一步也是递归FindBestPlan)。例如,用户查询是join后order by,则可以通过hash join后加一个sort enforcer实现,则总代价就是先获得hash join的开销,然后加上sort本身的代价。
缓存结果
搜索的部分中间结果缓存到hashtable,避免重复计算。例如某个join的两个输入表达式的优化结果可能在其他的join算法下被重复使用。
分支定界和剪枝
搜索过程中的cost limit用于分支定界 (branch-and-bound) 剪枝。一旦找到了一个可行的计划,其代价就作为初始的代价阈值。搜素过程中如果某个可能的计划的一部分代价都已经超过这个阈值则剪枝。因此尽早找到一个相对比较低代价的计划(也就是获得了一个比较紧的cost上界)对优化搜索过程很重要。
从上述几个步骤可以看出,其搜索算法的主要框架还是比较经典的搜索+分支定界剪枝。当然应用到优化器这一场景下有很多概念需要抽象定义好。
扫描二维码,分享此文章