《The MemSQL Query Optimizer: A modern optimizer for real-time analystic in a distributed database》VLDB2016
MemSQL是面向内存优化的数据库,本身是shared-nothing架构。MemSQL后来改名叫SingleStoreDB(S2DB),详细的架构参考这里:http://loopjump.com/singlestore-cloud-native-htap/
MemSQL的优化器分为三步:Rewriter, Enumerator, Planner。
因为MemSQL是shared-nothing的分布式架构,优化器的输出结果自然也是分布式执行计划(DQEP)。
先初步看下一个优化的例子,这里选的是TPC-H Q17
原始查询语句是
1 | SELECT sum(l_extendedprice)/7.0 as avg_yearly |
Rewriter会将这里的标量子查询转为join。原子查询计算起来会非常麻烦,对于part的每一行都要进行分布式计算出子查询结果。Rewrite为join后可以有更灵活的join plan和DQEP。
1 | SELECT Sum(l_extendedprice)/7.0 AS avg_yearly |
Enumerator会尝试找代价低的计划。因为lineitem表很大,所以最好是广播part和sub两个较小的表。所以Enumerator的计划如下:
1 | Project [s2/7.0 AS avg_yearly] |
Planner根据上面的计划生成DQEP,MemSQL引入了RemoteTable和ResultTable的概念来支持DQEP。
1 | CREATE RESULT TABLE r0 AS |
Rewriter
基于heuristic和cost-base的重写,将一个查询改写为另一个性能更好的等价的查询。
一些典型的基于启发的重写规则:
- Column Elimination:消除没有实际用上的列
- Group-By Pushdown:将group by移动到join前执行
- Sub-Query Merging:子查询改为JOIN,这样从局部优化变成全局优化,可能有更大的优化空间
重写规则很多,需要考虑这些规则的顺序,有时候可能需要交叉应用这些规则。
Rewriter改写时需要注意要将数据分布存储考虑进来。例如
1 | CREATE RESULT TABLE r0 AS |
假设T1有R1=200000行,T2有R2=50000行,T1执行完group后剩余有S_G =1/4比例,即S_G * R1 = 50000行,执行完Join剩余S_J=1/10,即S_J * R1=20000行,那么Group和Join执行完剩余R1 * S_G * S_J = 5000行。
假设T2.a索引单点查询代价为每行C_J=1,Group By通过hashtable实现,代价为每行C_G=1,那么:
$$ Cost_{Q_1} = R_1 C_J + R_1 S_J C_G = 200000 * 1 + 2000001/101 = 220000 \ Cost_{Q_2} = R_1 C_G + R_1 S_G C_J = 200000 * 1 + 2000001/41 = 250000 $$
如果根据这两个代价值对比,我们可能就选择Q1了。
但是如果考虑数据是分布存储的呢?因为T2按T2.a分区,但T1没有按T1.a分区,所以join需要移动数据,要么T1按T1.a做reshuffle或者广播T2,如果T2比较大,那么可能要选择reshuffle T1。这种情况下Q1和Q2的代价情况可能就有所不同了。
1 | Q1: |
假设reshutffle的代价为每行C_R=3,则
$$ Cost_{Q_1} = R_1 C_R + R_1 C_J + R_1 S_J C_G = 620000 \ Cost_{Q_2} = R_1 C_G + R_1 S_G C_R + R_1 S_G C_J = 400000 $$
BUSHY JOINS
搜索所有的join顺序来找到最优解是个NP问题。很多系统基本上值考虑left-deep或roght-deep join tree。但对于一些涉及到star和snowflake schema的查询,bushy Join可能会有非常大的性能优势。
注意到,即使Enumerator只考虑left-deep join tree,生成bushy join也是一个自然的过程,因为join的右侧的derived table可以扩展开,每个subselect可以采用left-deep join,这样自然就生成了bushy join。
我们以一个例子具体介绍这个算法。
1 | TPC-DS Q25: |
- 按照join关系构造如下的图,其中节点是表,线是join关系
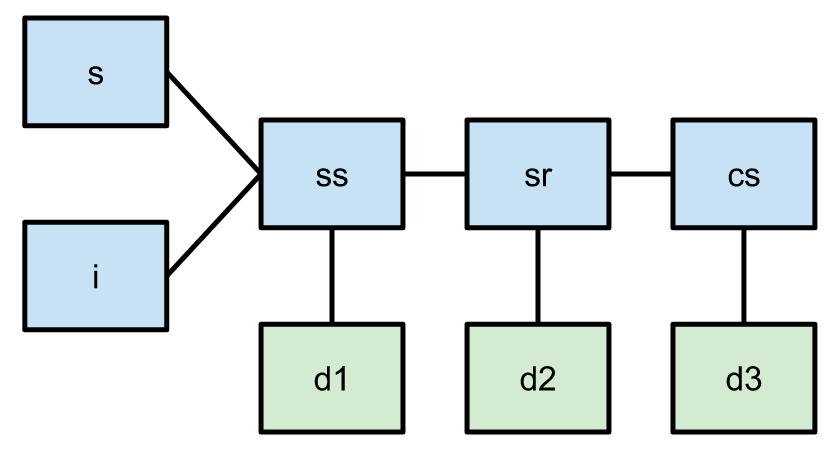
- 定义satellite表为至少有一个谓词的join表,且这些表只跟一张表有join。如图中的d1, d2, d3。
- 定义seed表为至少跟两个表有join,且其中至少一个是satellite表,如图中ss, sr, cs。
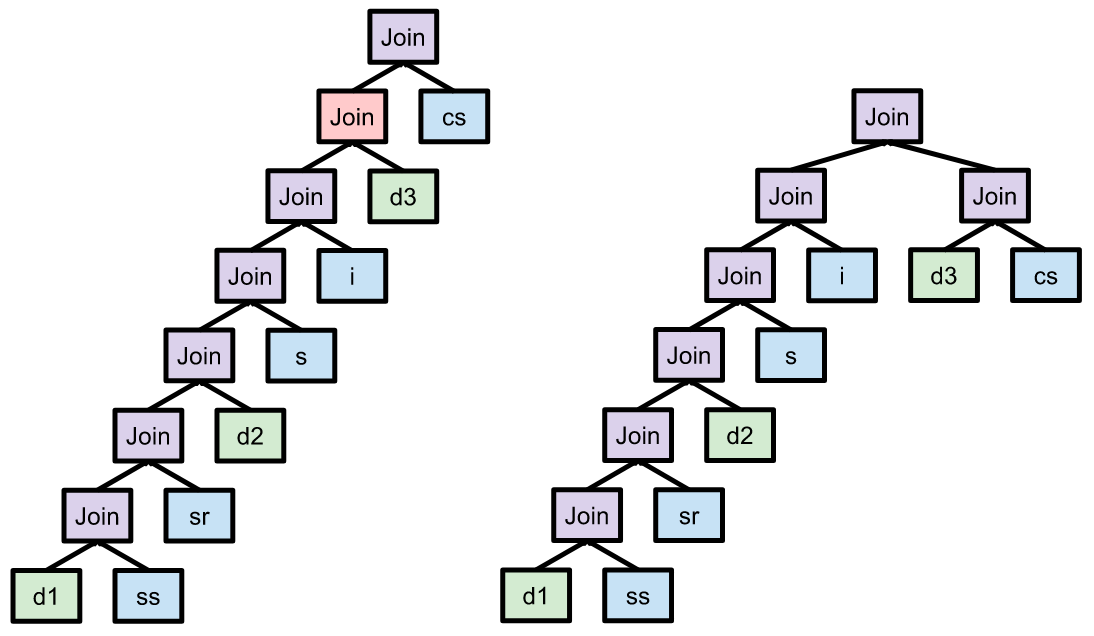
- 对于每一个seed表:
- 计算当前plan的代价C1。将这个seed表和它join的若干satellite表改为derived table写法。应用Predictate Pushdown规则,然后使用Column Elimination规则,使得外面的谓词转到内部并且外部不需要的列在内部也消除掉。计算新的代价C2。如果C1 < C2,则放弃这个重写变换,否则继续下一个seed表。
例如前面的查询改写后的结果为:
1 | SELECT ... |
Enumerator
Enumerator是Rewriter的下游,Rewriter主要是逻辑转换,Enumerator主要是物理转换。Enumerator要感知代价,而且单机上最佳的计划直接并行化并不一定是分布式下最好的计划。
Enumerator只负责针对每一个select block做join优化,跨select block的move join靠前面Rewriter来实现。
Enumerator通过bottom-up方式处理select block,最开始从优化最小的subselect开始,然后使用annotation information(类似于优化器hint)来激进优化更大的subselect,最后当最外面的select block处理完,整个查询的物理执行计划就确定了。
尽管Enumerator使用的是bottom-up的方式,但换用top-down的方式也类似。为了限制组合数爆炸,其他系统System-R类似基于interesting order的的动态规划,Enumerator实现了基于interesting property of sharding distribution(如sharding列等)的方式,值得考虑的sharding key如equal join的predicate column、grouping columns。
分布式代价
分布式执行计划代价里面多了数据移动的开销。
数据移动一般包含两类
- broadcast:数据从一个leaf node广播到所有其他leaf node,代价为R*D,其中R为待移动数据量,D为平均move一行的代价
- partition(reshuffle):数据从一个leaf node到某个特定的leaf node,代价为1/N*(RD + RH),其中N为节点总数,H为计算hash的平均代价
Fast Enumerator
详见另一篇论文《Query optimization time: The new bottleneck in real-time analystics》2015
Planner
Planner负责生成物理执行计划 - 一组DQEP Steps,DQEP Step是类SQL的step,可以以文本发送到其他节点,叶子step可以同时执行,一个Step可以在partition上并行执行。
MemSQL中节点间交互发送的是SQL语句,这可以透明支持node-level optimization。
Remote Table
MemSQL扩展了Remote Table功能,允许任何一个leaf node像aggregator一样来执行所有partition上的查询。
1 | SELECT facts.id, facts.value |
REMOTE关键字意味着facts这张表分布在多个节点上,查询要在每个节点的partition上执行,而不是只计算本地的partition。
Result Table
Result Table是查询在local partition上的一个中间结果,如果其他partition要多次查询该结果,则可以只执行一次。
例如,针对上面的查询,Planner会针对每个partition生成一个查询:
1 | CREATE RESULT TABLE facts_filtered |
这样,remote table查询的时候,可以直接查这个结果。
在DQEP中使用Remote/Result Table
DQEP里面包含一组数据移动step和计算step,中间通过Result Table衔接。Result Table并不一定要物化,可以只作为一层抽象流式提供数据。
1 | SELECT * FROM x JOIN y |
其中x在x.a上shard,y没有在a上shard。根据过滤后数据量的大小,最佳计划可能是broadcast x或者reshuffle y。
假设filter后x数据量很小,则选择broadcast x。这种情况下可能生成如下的DQEP:
1 | 1. CREATE RESULT TABLE r1 AS SELECT * FROM x WHERE x.b < 2 (on every partition); |
Remote Table和Result Table抽象非常灵活,例如
1 | 1. CREATE RESULT TABLE r1 AS SELECT * FROM x WHERE x.b < 2 (on every partition) |
Result Table在创建的时候支持通过指定partition key的方式实现reshuffle。
1 | 1. CREATE RESULT TABLE r1 PARTITION BY (y.a) AS SELECT * FROM y WHERE y.c > 5 (on every partition) |
扫描二维码,分享此文章