Haketon的高性能并发控制算法
High-Performance Concurrency Control Mechanisms for Main-Memory Databases (VLDB12')
这篇文章是微软Hekaton上的in-memory storage engine的高性能控制算法。
MV Storage Engine
关于事务可串行化的一个洞察和论述
如果事务的读和写逻辑上发生在同一时刻,则事务就是可串行化的。SI隔离级别并不满足这个情况,SI的读实际上是发生在事务开启时(事务开启时取快照,快照一旦确定了,即使读请求是过一段时间之后才发起的,仍然等价于是去快照后立刻执行的),写实际上发生在事务提交时(事务提交前,所有写操作都不生效)。
如果在事务结束时我们能够确认该事务之前发起的读操作,再次发起时返回相同的结果,那么等价于读操作和写操作是同时发生在事务结束这个时间点上,因此事务就是可串行化的。
基于上述观察,如果要事务可串行化,则如下两个条件都要满足:
- Read Stability:如果T读取行的某个版本V1,那么V1直到事务结束都应该继续有效而不是被V2更新了。我们可以加读锁或者在事务结束前做validation来实现这一效果(分别对应悲观/乐观)。
- Phantom Avoidance:事务的scan不会返回额外的新版本。我们可以通过加范围锁或者validation来实现(同样对应悲观/乐观)。
如果要实现更低的隔离级别,就容易的多:
- Repeatable Read:只需要保证Read Stability(RR不解决幻读问题)。
- Read Committed:不需要加锁,也不需要valdation。
- SI:不需要加锁,也不需要validation,总是使用事务开启时的快照。
Main Memory Storage Engine的原型
论文实现了一个Main Memory Storage Engine的原型。
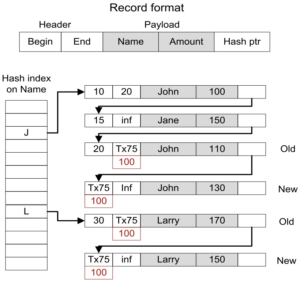
行格式如图示。begin字段可以是时间戳也可以是该活跃事务号,如果是事务号,表示该行可能尚未提交。
存储和索引:原型用的是hash索引,同一个hash桶上的记录无序。
读操作核心逻辑:读请求会分配一个时间戳snapshot作为读快照,查找满足begin < snapshot < end的版本读取。
写操作核心逻辑:创建一个新版本插入hash,beigin字段先用本事务号填充,上一个版本的end上也填充该事务号。
一个事务的生命周期:
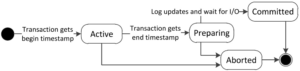
- 事务启动:分配begin timestamp,状态设为Active。
- 事务执行:执行读写,如前述。
- 事务prepare:事务准备提交的时候,先申请一个end timestamp,状态设为Preparing。如果可以提交,则将修改持久化,然后切换到Committed状态。
- 尾阶段:将本事务修改的那些行的end字段中的事务号回填成end-timestamp。
- 事务结束:旧版本会被注册到GC模块,等待不再需要时被回收。
版本可见性
除了前面所描述的查找满足 begin < RT < end 的版本外,因为begin和end可以填充事务id,所以这里分几种情况描述完整的可见性判断逻辑。注:这里先忽略边界情况(< or <=)。
begin字段和end字段都是时间戳
满足 begin < RT < end 即可见,否则不可见。
begin字段是事务id
读事务T遇到一个记录版本V,设V的begin字段是事务id=TB,那么可见性取决于TB的事务状态和TB的end-timestamp,因为TB可能处在已提交但是还没有回填end-timestamp的时刻。
具体的几种情况枚举:
- 情况1:TB.state = Active & TB.end_ts = NOT_SET,判定:TB=T且end=INF时可见。
- 情况2:TB.state = Preparing & TB.end_ts = TS,判定:TB将来的end是TS,V的begin将来会是TS,可以允许speculatively读。
- 情况3:TB.state = Committed & TB.end_ts = TS,判定:V的begin将来会是TS,可以用TS作判定。
- 情况4:TB.state = Aborted,判定:不可见。
- 情况5:TB找不到,判定:重读V的begin字段(读完begin的tid到根据tid查找TB上下文的时间间隔内,TB回填并结束了)。
end字段有事务id
读事务T使用读快照RT读到了版本V,V上end字段是事务号TE,则表明版本V正在被修改为新版本。
具体几种情况枚举:
- 情况1:TE.state = Active & TE.end_ts = NOT_SET,判定:TE=T且end=INF时可见。
- 情况2:TE.state = Preparing & TE.end_ts = TS,判定:如果TS > RT,事务将来提交则本版本可见,事务将来回滚,更新的是写事务会使用一个比TS还大的end-timestamp,所以本版本仍然可见;如果TS < RT则本可以speculative ignore版本V。
- 情况3:TE.state = Committed & TE.end_ts = TS,判定:用TS和RT比较判定。
- 情况4:TE.state = Aborted,判定:V可见。
- 情况5:TE找不到,判定:重读V的end字段(读完end的tid到根据tid查找TE上下文的时间间隔内,TE回填并结束了)。
commit dependency:
两种speculatively读情况要建提交依赖关系,序列化次序上要保持正确的提交顺序,如果被依赖事务回滚,可能要级联回滚。
Updating Version
更新V时,首先V必须是updatable的:即V必须满足end=INF,是最后一个版本。
如果有并发写事务更新同一行,遵循first-writer-win的策略,具体实现如下:事务T修改V时,先将V的end字段从INF原子地更新为T的事务id。如果原子更新失败表示有其他writer并发且抢先了,本事务回滚,如果原子更新失败,则将新版本插入索引结构,本事务持有新旧版本的内存指针,用于在Postprecessing阶段回填。
Commit Dependency
前面已经提到了,speculative执行可能会导致提交依赖,被依赖事务回滚时会导致级联回滚。
具体用到的数据结构很直观,略。
提交时等待可能引入死锁,解决方式是wait-for graph里面只允许end-timestamp小的事务等待大的事务。
Optimistic Transaction
首先讨论的是可串行化乐观事务。
乐观并发控制的validation阶段有两种做法:backward validation 和 forward validation。
论文使用的是 backward validation,但不是拿本事务的ReadSet去检测其他事务的WriteSet,而是检查本事务已经读过的版本是否在本事务结束时刻仍然可见。这一点在一开始就论述过了。还有一点就是跟普通OCC不一样的是,论文描述的方式是一开始就写入索引的,不需要OCC的第三步Write Phase,只需要改下事务状态就行。
具体地,一个可串行化的事务追踪了三个集合:
- ReadSet:包含了所读到每个版本的内存指针(注:这是一个内存数据库)。
- ScanSet:存储了每个scan要发起重复读的必要信息。
- WriteSet:包含了每次修改产生的新版本和老版本。
执行阶段
略,根据前面的说法推理一下就行。
Prepare阶段
Prepare阶段要做的三个操作:read valiation、wait for commit dependency、logging。也就是说prepare要完成所有预防未来不能提交的操作。
validation包含两步:validate已经读取过的行、validate幻读。
Postprocessing阶段
略,根据前面的说法推理一下就行。
更低的隔离级别实现
- RR:要求Read Stability但不要求解决幻读。只需要validate ReadSet就可以了,ScanSet不需要validate。
- RC:使用当前时间戳作为读快照,ReadSet和ScanSet都不需要验证。
- SI:使用事务开始的时间戳作为读快照,ReadSet和ScanSet都不需要验证。
只读事务:用SI和RC的隔离级别就行(要一致性快照就SI,否则RC)。
Pessimistic Transaction
可串行化的悲观事务需要维护如下的集合:
- ReadSet:指向事务加读锁的行指针
- BucketLockSet:事务访问hash桶
- WriteSet:指向修改的行的新旧版本。
Lock Types
两种锁:
- record lock:保证read stability
- bucket lock:避免幻读
Record Lock
Record lock是是一个多读一写的读写锁,锁本身利用行记录的end字段即可。
详细的字段编码如下:
ContentType(1bit): 0表示后面63bit是时间戳,1表示后面63是RecordLock。
RecordLock(63bit):
- NoMoreReadLocks(1bit):置1表示不再允许新加读锁,目的是解决starvation
- ReadLockCount(8bit):读锁计数,最多允许255个并发读。
- WriteLock(54bit):事务ID或者INF。
Bucket Lock
Bucket lock包含如下字段:
- LockCount:该桶上的锁的数目
- LockList:持有该桶锁事务列表
实现上,LockCount放在同上,LockList放在一个单独的hash上。
- 加锁:递增LockCount,找到桶锁的LockList,将自己加进去
- 放锁:从LockList移除,递减LockCount
类似的锁结构可以实现range lock,前提是索引结构是ordered index,比如B+Tree、skiplist等。
Eager Update、Wait-For Dependency
当一个事务尝试加锁失败时,要发生线程上下文切换。上下文切换涉及OS线程调度,要花费几千条CPU指令。少量的线程切换就会对内存数据库事务性能有显著的影响。
为了减少锁blocking,论文采用了eager update方式:即使行被加了读锁,仍然可以被写修改,反过来,即使加了写锁,仍然允许读。这里要保持事务顺序,eager update的事务不能在读锁释放完成前commit。但这个违背读写锁语义的情况跟speculative exection不一样,这里并不会引发级联回滚。还有一点就是record lock和bucket lock都可以按这个思路优化。
每个事务维护如下的信息:
incoming wait-for dependency:
- WaitForCounter:本事务等待多少依赖(我要等几个依赖,这里本事务可能依赖另外一个事务多次)
- NoMoreWaitFors:防starvation(我不相等了)
outgoing wait-for dependency:
- WaitingTxnList:等待本事务结束的事务列表(谁在等我)
Read Lock Dependency
更新事务TU更新V时,加write lock,如果此时ReadLockCount>0,则递增TU.WaitForCounter。
反过来,如果此时另一个事务TR读取V,则TR先申请读锁(若因NoMore标记或者ReadLockCount满导致不满足则abort)。如果发现TU持有write lock,且TR是第一个读事务,则TR加读锁并递增TU.WaitForCounter(建立依赖: TU等待TR)。
TR释放读锁时,如果有写锁被持有,那么看TR是不是最后一个读者。如果不是,TR只需要简单地释放读锁即可,如果是最后一个读者,则要负责删除依赖,具体删除依赖的实现方法是:原子地将ReadLockCounter设为0且V.NoMoreReadLocks=true,如果原子更新成功则找到TU并递减TU.WaitForCounter。如果TU.WaitForCounter被减到0,则表示TU可以提交,那么TU此时被允许申请end-timestamp然后进行提交。
Bucket Lock Dependency
桶锁的核心目的是解决幻读。
桶锁跟普通锁有点不一样,一个读事务TS加桶锁的目的并不是阻止新版本写入,而是阻止新版本对TS可见。更新事务TU可以创建新版本并加入到桶中,但TU得等到TS释放了桶锁后才能进行提交,这个等待是通过让TU wait-for TS实现。
wait-for依赖的加入:
在这个系统中,wait-for依赖关系可能有两种方式被加进来。
- 场景1 - TU自己加<TU依赖TS>: 如果TU发现桶B上有桶锁,则TU要等待B桶锁上所有的其他事务,即将自己加到B.LockList里面的每一个事务TS的WaitForList且递增TU.WaitForCounter。
- 场景2 - TU被TS代加<TU依赖TS>: 如果一个可串行化的事务TS扫描B,且发现了一个满足扫描谓词的版本V,但V还没提交,对TS不可见。如果V提交早于TS提交,则TS就会出现幻读。这里的处理方式是TS代替TU给TU加一个wait-for依赖,即将TU加入TS.WaitingTxnList并递增TU.WaitForCounter。
释放wait-for依赖:
当一个可串行化事务已经申请完end-timestamp后,就可以释放outgoing wait-for dependency,扫描WaitingTxnList中每一个事务,递减其WaitForCounter。
Processing Phases
Normal Processing Phase
- Strat Scan: 可串行化事务会加桶锁来避免幻读;其他隔离级别不加桶锁。
- Check Predicate:同Optimistic Transaction。
- Check Visibility:基本同Optimistic Transaction;如果是可串行化事务,需要增加wait-for dependency避免幻读,参考Bucket Lock Dependency一节。
- Read Version:如果是serializable或者RR事务且V是最新版本,则要加读锁,其他情况不加读锁。
- Check Updatability:同Optimistic Transaction。
- Update Version:创建新版本N,加写锁,如果已经有读锁在那么要加wait-for dependency(参考Read Lock Dependency),将新版本N插入索引,如果插入过程碰到桶锁,按基于桶锁避免幻读的方式加wait-for依赖。
- Delete Version:类似于Update Version,只是没有新版本产生。
事务执行阶段结束后,释放record lock和bucket lock,如果自己需要等别人(TU.WaitForCounter>0)则等待,等地啊结束则申请end-timestamp并将state设为Validating。
Prepareing Phase
Pessimistic transaction不需要validation,但是可能仍然有待解决的(speculative执行引入的)commit dependency,等依赖都解决了,则写wal log并提交。
Postprocessing Phase
这个阶段同Optimistic Transaction。
DeadLock Detection
什么依赖会引入死锁?
系统中有两类依赖关系,一个是speculative执行引入的commit dependency,另一个是wait-for dependency。
- commit dependency:前面描述过,两种speculatively读情况要建依赖关系,序列化次序上要保持正确的提交顺序,所以不会导致循环等待,因为不会导致死锁。
- wait-for dependency:没有处理循环等待,可能导致死锁。
死锁解决方式
解决死锁的方式是构建wait-for graph:分析所有事务间的wait-for dependency,然后应用已有的成熟算法(例如Tarjan算法)来找依赖环路。
Wait-for graph
有向图,其中节点是事务、边是事务间依赖。
构建过程:
- 创建节点:如果事务T卡在等wait-for依赖而不能提交,则给该事务创建一个节点N(T)。
- 显式依赖:bucket lock引入的依赖叫显式依赖,因为里面有WaitingTxnList,根据这个list构建边。
- 隐式依赖:record lock引入的依赖叫隐式依赖,因为没有单独维护具体是哪个事务依赖关系,只知道写锁上有些写事务id但不知道是哪个读事务在等待,这时就要扫描全部事务的每个ReadSet逐个找。
因为构建过程中,并发事务不断进行,所以graph并不精确,不过没关系,如果真的有死锁,死锁相关的节点和边就一定存在于graph中。对于小概率false deadlock,可以recheck一下。
乐观事务与悲观事务并存
本系统的乐观事务与悲观事务可以并存,但是要乐观事务T要感知并使用锁,三个具体的修改:
- T的tid只能是54bit
- T更新一个持读锁的记录时,要增加wait-for dependency
- T插入桶B时,要增加wait-for dependency
实验测试结果
实验环境:2-socket CPU,共12核24超线程,NUMA架构,remote socket比local memory慢30%。
事务异步IO刷盘,这里注意事务不等待IO结束,内存数据库不像磁盘数据库那样需要更多并发线程进来以overprovision(填充事务都在等磁盘IO而带来的CPU空闲),因此测试最多测24线程。
另外作为基线对比,实现了single-version的基于锁的并发控制算法,该算法标记为"1V",乐观标记为"MV/O",悲观标记为"MV/L"。
同构workload
Scalability (Read Committed)
- 1V在需要超线程出现拐点(NUMA remote开销),拐点前后基本是线性扩展的。
- 两个MV都比1V性能差,主要是多版本创建、GC等开销。
- MV/L比MV/O差30%,主要是追踪依赖关系和锁两者带来的访存开销,其中30%=20%的执行指令本身开销大(CPI变差了) + 10% MV/L额外的per-trans指令数目。
Scaling under Contention (Read Committed)
热点行问题对所有并发控制算法(CC)都是不好处理的。悲观CC会产生大量的锁等待和死锁,乐观CC会导致大量的validation失败和写写冲突,导致高回滚率。从硬件指令层面看,热点行场景下,有一些热点数据结构会带来产生大量的跨核访问。
测试结果:MV/O稍好点。1V仍在需要超线程出现拐点(NUMA remote开销)。
从RC到RR/Serializable:
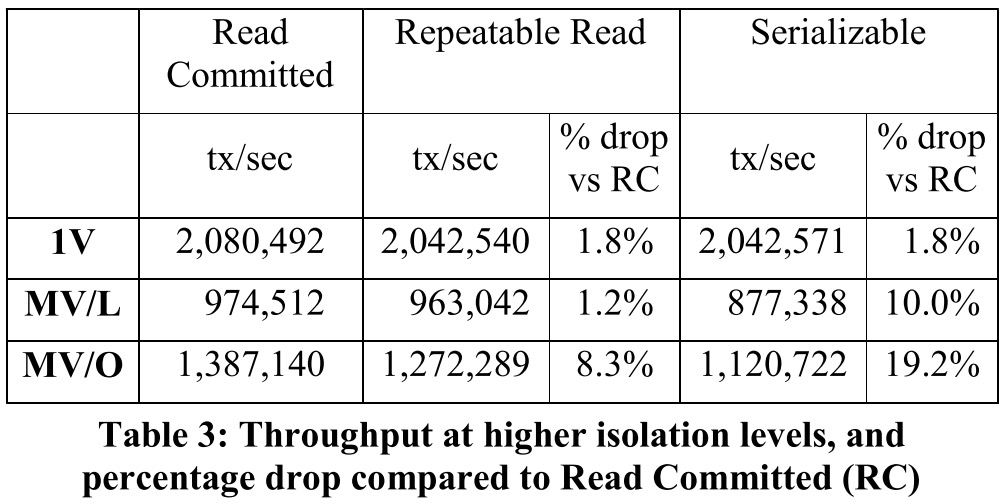
MV/O的开销增幅最大,因为要做repeat valdiation。
异构workload
Impact of Short Read Transactions
低冲突:只读事务比例接近100%时,MV比1V好,因为只需要读一致性快照即可,省了锁和validation开销;写事务少,因此多版本、GC开销比例也很低。
高冲突:MV比1V好,读和写被多版本隔离。
Impact of Long Read Transactions
测试中,workload有部分长只读事务。
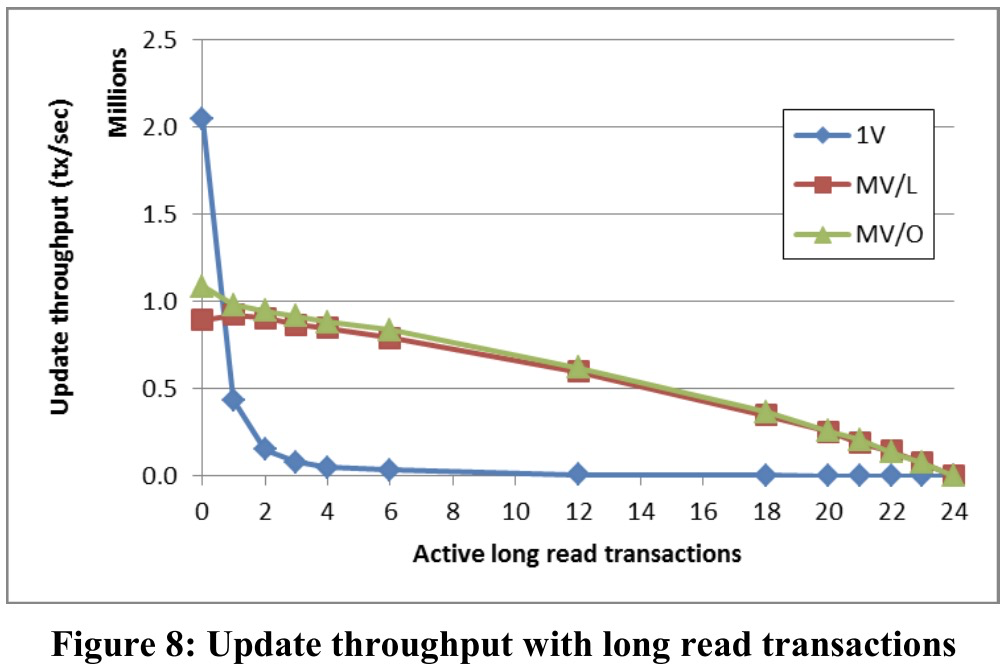
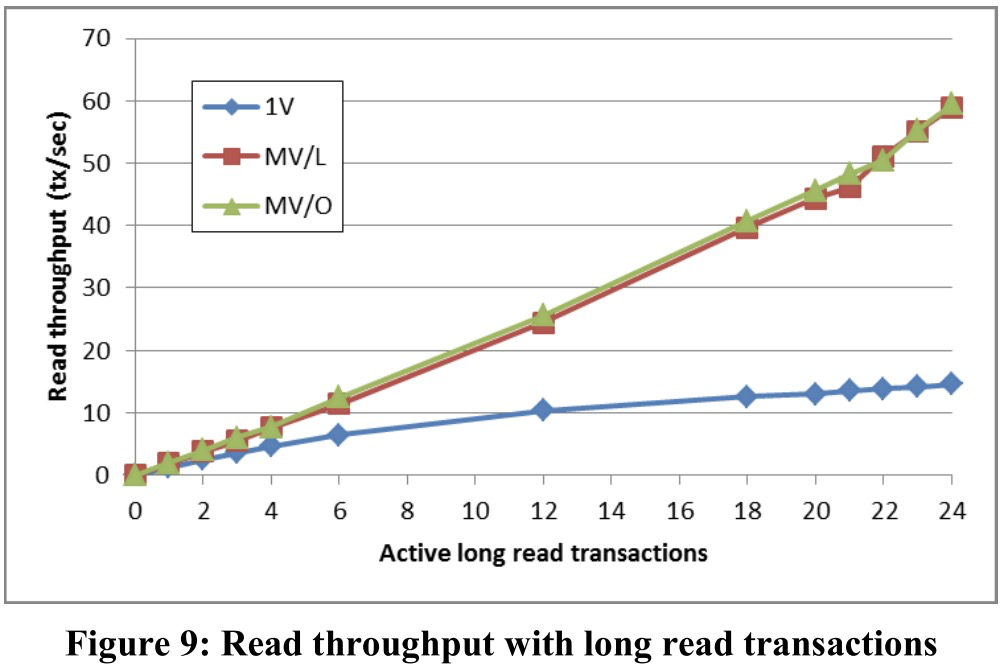
测试结果看,有长只读事务就会导致1V骤跌。
注意到前面同构workload几个测试中,1V往往都比MV表现好。这说明1V的workload适应性不好。
一点总结
这篇论文是微软Hekaton系统上的CC算法的介绍,虽然索引结构只是简单的hash表而不是ordered index(BwTree之类),但论文对CC讲的非常到位,如何设计锁,如何做validation,如何避免幻读等等,而且对于操作次序有明确的说明。
炉温同时也充分测试了多种场景下的性能。访存频率/Cache跨核对内存数据库CC性能有直接影响。
另外,1V虽然在一些场景比MV强(因为1V不需要多版本维护开销),但多场景适应性很差,因此基本上商用数据库都是支持MV的。
2 条留言 访客:0 条 博主:0 条 引用: 2 条
来自外部的引用: 2 条