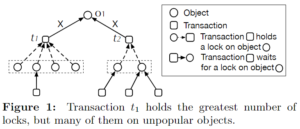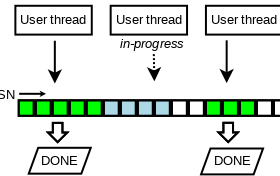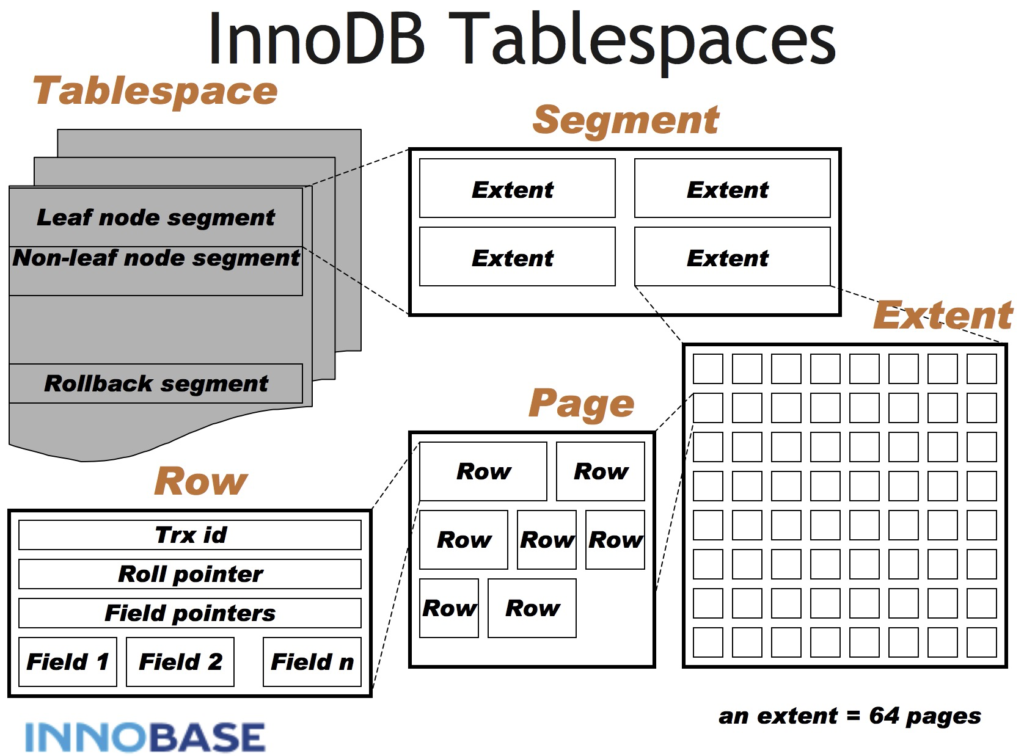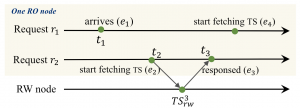
《PolarDB-SCC: A Cloud-Native Database Ensuring Low Latency for Strongly Consistent Reads》
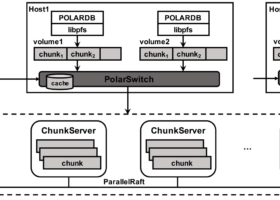
很多数据库系统通过类似于binlog复制或者redo复制的方式提供RO节点来提升整个系统的读吞吐,RW节点上产生更新,同步到RO节点apply变更。但只读请求发到RO节点上可能会读到陈旧的数据。如果想读到最新的数据(例如read-after-write一致性)呢?
首先读到最新数据或者强一致性读,指的是RO上启动的只读请求,...