Hekaton内存引擎
Hekaton: SQL Server’s Memory-Optimized OLTP Engine(SIGMOD13')
为什么要重新设计Hekaton引擎?
单纯优化现有的SQL Server还能不能有10-100倍吞吐提升?
说到底吞吐提升的三条路:提升scalability、提升CPI、减少单个请求执行的指令数目。
关于提升scalability:SQL Server的scalability已经有1.89(直到增至256核,core数目加倍,能获得性能1.89倍)。
关于提升CPI:SQL Server跑常规的OLTP benchmark的CPI小于1.6,即使提升到CPI=0.8,也只能获得一倍提升。
最优情况下,提升scalability 且 提升CPI 可以获得的性能也就3到4倍。
所以只剩一条路:减少单个请求执行的指令数目,10倍性能要减少90%的指令,100倍要减少99%的指令,只优化现存的引擎是做不到的。
Design Considerations
Architectual Principles
Optimize indexes for main memory
基于磁盘页面的引擎,通常要维护复杂的buffer pool,page要被latch保护,即使page全在内存,一个简单的B-Tree查找也要消耗几千条指令。所以Hekaton重新设计实现了驻内存数据的索引。当然wal和checkpoint仍然存在。
Eliminate lathes and locks
百核心的CPU逐渐流行,因此scalability非常关键。如果系统中存在一些内存地址被高频修改,例如latch、spinlock、LockManager、wal log tail、last page of B-Tree等等,就会严重影响scalability。
Hekaton的所有关键数据结构,包括内存分配器、hash/range索引、trans-map等完全都是lock-free的。关键路径上没有任何spinlock/latch。Hekaton的OCC算法也是完全lock-free的。
Compile request to native code
解释执行是RDBMS的标准且通用的做法,解释执行的优点是灵活,缺点是执行慢。一个简单的查询语句,如果是使用解释执行的话,大概要执行10万条量级的指令。
Hekaton解决方法是,对于T-SQL编写的语句和存储过程,Hekaton会将其编译成高度优化的机器码,编译会花一些时间,但执行期间效率很高。
No Partitioning
HyPer/Dora/HStore/VoltDB这类内存数据库会将数据partition到per-core。但是Hekaton搞了个partition的prototype探索之后,并没有采用这个设计。原因在于workload本身能够partition的时候,数据分区的设计效果很好,否则请求做分区导致多个执行线程间协调同步会导致性能下降严重(比如按非分区键搜索)。
High-Level Architecture
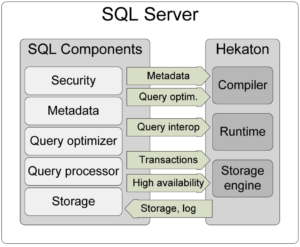
大部分都比较容易理解,这里挑几个介绍。
Hekaton runtime:一个小的模块,与SQL Server的资源结合,作为编译执行时所依赖功能的库。
Query Interop:解释执行时存储引擎提供的操作接口。
Storage and Indexing
参见之前的文章《论文阅读 - Haketon的高性能并发控制算法》。
区别在这里除了hash index还有个btree index。Hekaton用的是一个lockfree的BTree,叫Bw-Tree。
Programmability and Query Processing
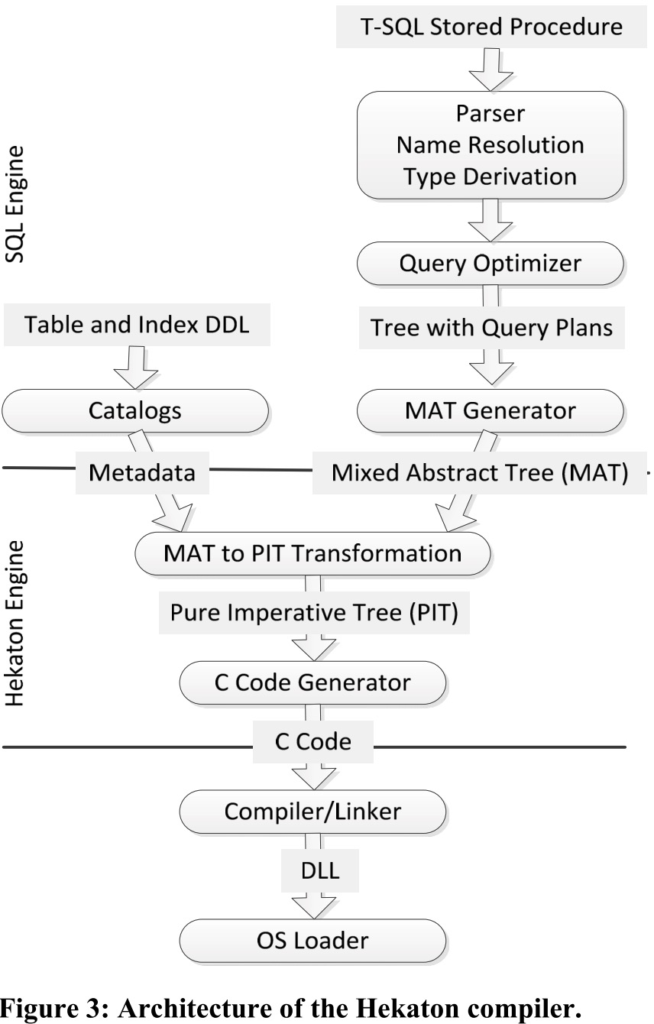
面向compile-once-execute-many-times的workload,编译执行对用户透明。C代码到机器码复用Microsoft的Visual C/C++编译器。
Schema Compilation
Hekaton存储引擎将record内容视为黑盒,并不了解record内部格式。对record的操作编译成机器码之后,需要调用一些回调函数来操作record内容,这些回调函数需要感知record格式,因此涉及schema相关的信息也要编译成机器码。
Compiled Storage Procedures
举例说明将T-SQL转成C语言的一些困难:
- 二者type system差别很大,T-SQL有date/time、各种精度数值类型。
- T-SQL支持NULL,C没有这个语义对应的类型。
- T-SQL在出现算术错误(除零等)时报错,但C语言会直接抛给OS。
因为复杂性,Hekaton不是直接将MAT转成C,而是先转成PIT再转成C。
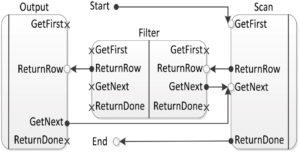
有些编译执行的方式是, 每个operator通常都有自己的一组接口,每个接口都表现为一个C语言函数,operator间通过接口调用。这种基于函数的方式,会有函数调用和函数传参的开销。
Hekaton为了提升极致性能,采用的方式并不一样。Hekaton将每一个存储过程直接编译成单独的一个函数,跨operator的调用使用的是label和goto。一个带filter的scan的执行计划,编译完可能就是如图示的样子,空心圈表示一个label,箭头表示goto,filter根据谓词可能有命中/未命中两个逻辑。
注:有些像sort/数学函数之类的可以直接使用库函数,没必要编译到一个函数里面。
Restriction
为了极限性能,带来的一些限制:
- option功能只支持编译时确定的情况
- 为了做权限检查,要求存储过程必须在预先定义好的security context中执行
- schema bound
- 存储过程必须在某单个事务的上下文中执行
Transaction Management
参见之前的文章《论文阅读 - Haketon的高性能并发控制算法》。
Transaction Durability
logging、checkpointing和recovery组件的设计原则:
- 顺序访问IO,这样客户就不需要单独为了买高性能的随机读写存储花钱了。
- 主流程尽量减少操作,能移到Recovery阶段的操作都移过去。
- 消除扩展性瓶颈
- 在Recovery阶段要做IO和CPU的并发。
磁盘数据有两类:Log Stream、Checkpoint Stream。
Transaction Log
逻辑REDO日志,事务提交阶段写。
因为log tail竞争多,所以减少日志量、支持多个日志流(事务顺序不依赖LSN)都可以优化性能。此外经典的GroupCommit方式也能大幅优化性能。
CheckPoints
- Continuous Checkpointing:要避免突发的checkpoint
- Streaming IO:依赖顺序流式IO
Checkpoint Files
Checkpoint文件包括:
- data file:只包含某段时间(事务begin-timestamp)区间的插入的版本(insert/update),Append-Only。
- delta file:跟data file一一对应,记录被删除的版本,Append-Only。Recovery的时候用于过滤对应data file的新增version。
- checkpoint file inventory:checkpoint相关的文件清单
Checkpoint Progress
将新的transaction log转为data file和delta file,更新inventory。
持续一段时间之后,checkpoint文件就会逐渐变多,导致recovery时间变长。解决方法是merge以消除delete操作带来的空间浪费(物理删除delete项)。
Recovery
可以按data/delta file pair粒度并行恢复,one thread per core充分并行。
恢复完checkpoint之后,再恢复transaction log。
Garbage Collection Details
GC Correctness
Delelte/Update会产生旧版本,这些版本在未来不会被任何事务再访问时需要被回收。另外就是事务回滚也要回收该事务产生的版本。
GC线程周期地扫描全局活跃事务map,得到最老的活跃事务的begin-timestamp作为gc-timestamp。end-timestamp小于gc-timestamp的事务产生的旧版本都可以回收。
Garbage Removal
GC包括两个部分,一是服务请求的工作线程间协作,二是并发后台回收。
工作线程碰到需要回收的版本可以自己做回收,好处一是 这个过程是并发的,二是后面其他scan不会因为这个旧版本变慢。
仅靠工作线程做回收,就会出现索引的热点区域的回收比较及时,但冷区就不及时,虽然冷区不会拖慢整体扫描性能,但是还是会浪费内存,因此启动一个后台线程做回收,反正冷区不影响性能,后台线程回收不那么及时也没问题。
这样设计的主要原因是:及时 和 可扩展。
Scalability
如果是使用一组单独的线程并发做回收,可能出现在大负载压力下回收线层无法及时做回收的情况。所以Hekaton采用了上述让工作线程附带做回收的设计。当然单独的回收线程仍然需要,因为要定期计算gc-timestamp等工作。
单独的回收线程计算完gc-timestamp,会将待回收的事务集合划分成子任务,分派到CPU-local的工作队列里面,每个工作线程处理完一个事务后就去工作队列里面拿出来一个任务处理。这个设计对scalability非常友好:一是自然地在CPU核间并发了,而是系统自调节的(不会出现忙于处理事务请求而无法及时回收旧版本的情况)。
Experimental Results
CPU Efficiency
Lookup测试结果:(Hekaton表 + 编译执行)相比(SQLServer常规表 + 解释执行)10~20倍加速。
Update测试结果:同上的对比测试,20~30倍加速。
Scalability
从2核扩展到12核(6倍)的情况下,考察几种情况的tps提升倍数:
编译执行:提升36375/7078=5.1倍,
原SQLServer提升2312/984=2.3倍,
将原SQLServer测试改成完全无冲突的情况,提升也就5.1倍。
一点总结
Hekaton是镶嵌在SQLServer上的内存数据库引擎,使用了各种方式做到了极致的性能优化。这篇论文所有的设计分析和测试分析都十分硬实,读下来十分舒服。
内存数据库如何实现10倍性能提升?Hekaton指明了一条路:减少执行的指令数目。
尤其是在目前多核服务器架构下,核间通信带来的开销已经有了显著的影响。如何尽可能地优化CPI,提升scalability也是设计实现上的一个重要的原则。
1 条留言 访客:0 条 博主:0 条 引用: 1 条
来自外部的引用: 1 条