Spanner: Becoming a SQL System论文阅读笔记
继2012年在OSDI年发表了Spanner论文《Spanner: Google’s Globally-Distributed Database》之后,Google在SIGMODE'17上发表了第二篇关于Spanner的论文《Spanner: Becoming a SQL System》。从整个的数据库系统角度看,2012年那篇讲是的Spanner的下半部分Storage Engine的一些feature:数据自动分区和全球部署、多副本Paxos高可用、支持外部一致性的分布式事务。2017年这篇主要讲是讲数据库的上半部分查询引擎相关的内容(也包括适配查询引擎的存储部分的改动)。
Spanner的演化
相信读过OSDI'12 Spanner论文的同学都对Spanner强大的存储引擎印象深刻。但在12年的时候,Spanner对业务呈现的几乎就只是一个引擎,而很多OLTP业务强schema和查询能力的期待,促使Spanner演化成了一个全功能的SQL系统。
Spanner的查询引擎实现了标准SQL,具备如下能力:
- 支持TP和AP两种workload
- 支持低延迟和长查询
查询引擎做了各种针对Spanner的优化:
- 分布式执行器
- Range Extraction
- Query Restart
- 适应于查询引擎的存储格式改造
Query Distribution
这节讲述分布式查询。
Distributed Query Compilation
Spanner的执query解析和执行跟传统单机数据库差不多,首先是解析成语法树,然后使用规则进行等价重写。但Spanner多了分布式的部分,具体地,就是多了一个DistributedUnion operator来显式指明需要分布式执行,这个算子负责将子查询发到各个shard,然后汇聚结果。
DistributedUnion是整个分布式执行中非常基本的操作。首先,基于DistributedUnion可以实现更复杂的分布式operator,比如分布式join。另外,尤其是考虑到Spanner引擎层的shard可能迁移或分裂,查询引擎并不是静态感知shard的location,而是在执行过程中感知。
在生成plan的时候,如果出现扫表的操作,就要把扫表改写成扫描各个shard然后汇聚结果。
)](http://loopjump.com/wp-content/plugins/latex/cache/tex_8cb638301733798d020783f35530dfc2.gif)
如果有可能,针对Scan(T)的operator就尽量下压,但下压的operator要满足partitionability:
))](http://loopjump.com/wp-content/plugins/latex/cache/tex_bb3dc552af5a951c84ecff61f16d4de6.gif)
这种下压在传统单机数据库优化的时候也是常见的。另外,跟Spanner的数据模型相关(层级模型)的一点,如果要Join的两张表的连接键如果同时是两张表的分区键,那么Join就可以在每个shard上并行做,然后直接用DistributedUnion汇聚结果。
另外一种可以下压的情况是多个Shard上的结果再次计算得到最终结果的场景,比如TopK和GroupBy。这种情况Spanner使用两阶段计算的方式,先在Shard上局部计算一次,然后在DistributedUnion的结果后再汇总计算一次。这类操作要满足如下条件:
))) = opFinal(DistributedUnion[shard \subset T](opLocal(F(Scan(T)))))](http://loopjump.com/wp-content/plugins/latex/cache/tex_692445828068800c49144932ea20e1ac.gif)
举个例子:
|
1 2 3 4 5 6 7 8 |
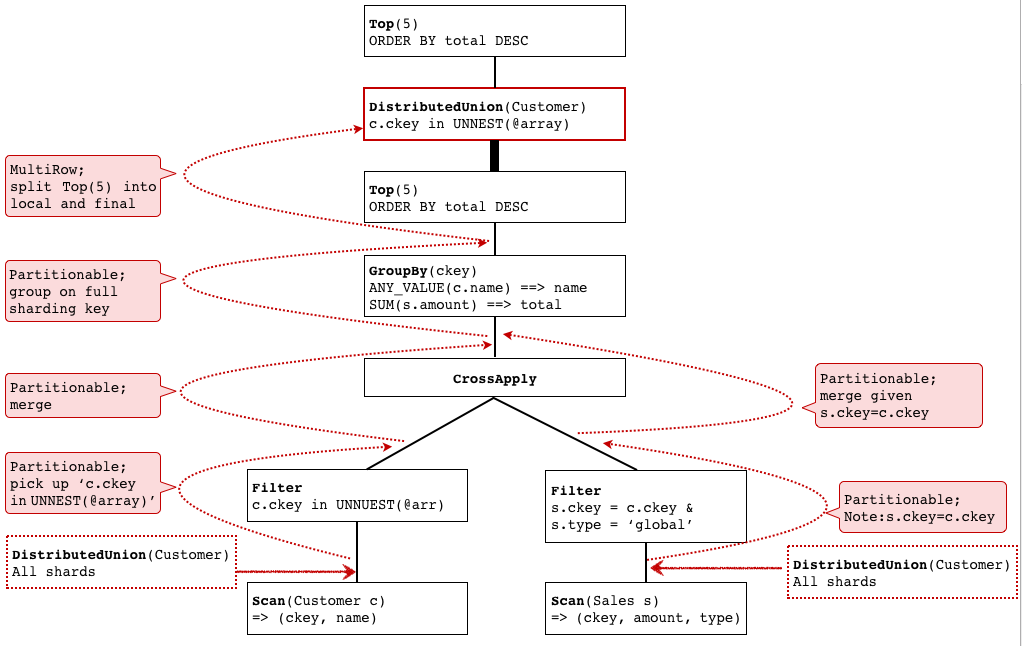
SELECT ANY_VALUE(c.name) name, SUM(s.amount) total FROM Customer c JOIN Sales s ON c.ckey = s.ckey WHERE s.type = 'global' AND c.ckey in UNNEST(@customer_key_arr) GROUP BY c.ckey ORDER BY total DESC LIMIT 5 |
其中,在Spanner数据模型下,Customer表和Sales表都是按照ckey进行sharding,并且Sales表交叉到Customer表中(Customer表一行与同ckey的Sales的若干行存放在一起)。
这个SQL查询customer_key_arr指定的这些customer的类型为global的销售记录的金额总和的top 5。
 其中,
其中,
UNNEST 获取一个 ARRAY,然后返回一个表,ARRAY 中的每个元素均占该表的一行。
CrossApply(input, map)允许你join两个table表达式,针对左表达式的每一行,右表达式都计算一遍,如果右表达式计算结果不空(一行或多行),就产生一行或多行最终结果。
图中红色的虚线,描述了DistributedUnion这个operator不断上移的过程,红底描述了每次上移所满足的条件。
需要注意的一点,在DistributedUnion不断上移,也就是key过滤条件不断下压的过程中,会把跟sharding key有关的过滤条件不断收集起来,最后合成一个,称之为sharding key filter expression,把这个表达式附带在DistributedUnion上。
另外,实际更复杂的执行计划可能包含多个层次的DistributedUnion。
Distributed Execution
Spanner的coprocessor framework是能够感知location信息的RPC层,在通过coprocessor framework路由去某个shard上的查询时,可以在这个shard的多个副本中选择就近的副本。
开始执行的时候,Spanner根据sharding key filter expression做range extract和prune(具体方法后面有介绍),确定要访问哪些shard。多个shard(或shard group)的执行是并行的,以此可以减少这个查询的整体耗时。另外如果存在一些非常大的shard,Spanner的存储层可以通过维护一组分割点来将shard逻辑上分为多个subshard,subshard粒度上可以进一步并行执行。
执行前,执行器还可以检查一下,看看是不是有某几个shard是位于同一台物理机器的(这样的几个shard称为在一个shard group中),这样就可以把分布式执行的粒度从shard优化为shard group,从而减少跨机的调用。此外,DistributedUnion算子还会检查shard是不是就在本地,这样可以将RPC优化为本地调用。
不过考虑到避免一个查询引起过高的负载,实践中也会限制并行度。
Distributed Joins
这一小节只讲了一种Join的优化,叫Batched Apply Join。
通常的ApplyJoin,比如CrossApply,是左边表达式结果的每一行都要在右边表达式计算一次。这种row-at-a-time的方式(volcano模型就是这种方式)即使在单机就有可能比较低效,考虑到分布式执行的时候,左边每一行都要发到其他节点进行apply,这种低效就不可接受,因此将这种row-at-a-time优化为batch-at-a-time,转换方式如图。
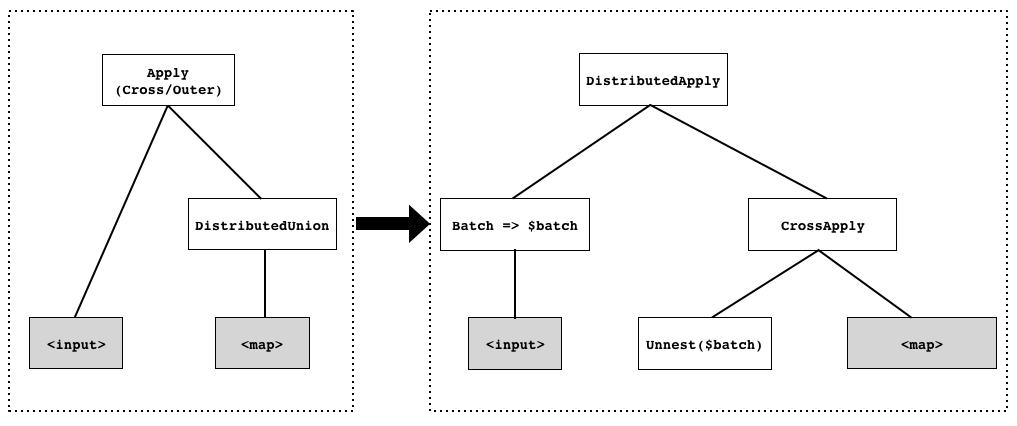
这个过程中可以按如下步骤做shard pruning:
- Step1: 对batch的每一行,用sharding key filter expression计算,得到这一行涉及到的sharding key range。
- Step2: 将batch各行产生的range结果合并。
- Step3: 根据Step2的结果确定将要发送到的shard的最小集合。
- Step4: 根据Step3的shard集合,对集合中的每一个shard,都反过来对batch再做一次过滤。
另外,DistributedApply可以在多shard上并行执行,每个shard也可以先seek再scan,不需要scan整个shard的范围。
Query Distribution API
Spanner提供两种查询接口:
single-consumer api: 跟普通的数据库查询接口一样,客户端首先做初步location信息分析,然后直接发给特定节点。
parallel-consumer api:用于数据分析,客户端先调接口告诉Spanner查询的并发度(有几个并发的客户端),然后Spanner会返回一组划分好的数据分区,各个客户端负责查询一个分区。
Query Range Extraction
Problem Statement
Query range extraction是指分析一个查询涉及到的数据主键区间集合。
Spanner有如下几种风格的query range extraction:
Distribution range extraction
分析这个查询涉及哪些shard
Seek range extraction
分析这个shard上哪些fragement是需要访问的。有些查询可能只需要扫描一个shard的一部分数据。不过extraction本身也会耗费时间,这个需要平衡。
Lock range extraction
分析哪些range需要加锁(参见12年论文),Lock range extraction能够精细地加锁。
至此,query range extraction是干什么的这个问题就清晰了,接下来就是怎么实现。
Query range extraction依赖两种机制:
- 编译期将filtered scan改写成关联的self-join
- 运行期维护filter tree用来从底向上计算range和优化post-filter的计算
Compile-time Rewriting
先看一个重写的例子。
|
1 2 3 4 5 |
SELECT d.* FROM Documents d WHERE d.ProjectId = @param1 AND STARTS_WITH(d.DocumentPath, ’/proposals’) AND d.Version = @param2 |
这个filtered scan会改写成如下的计划:

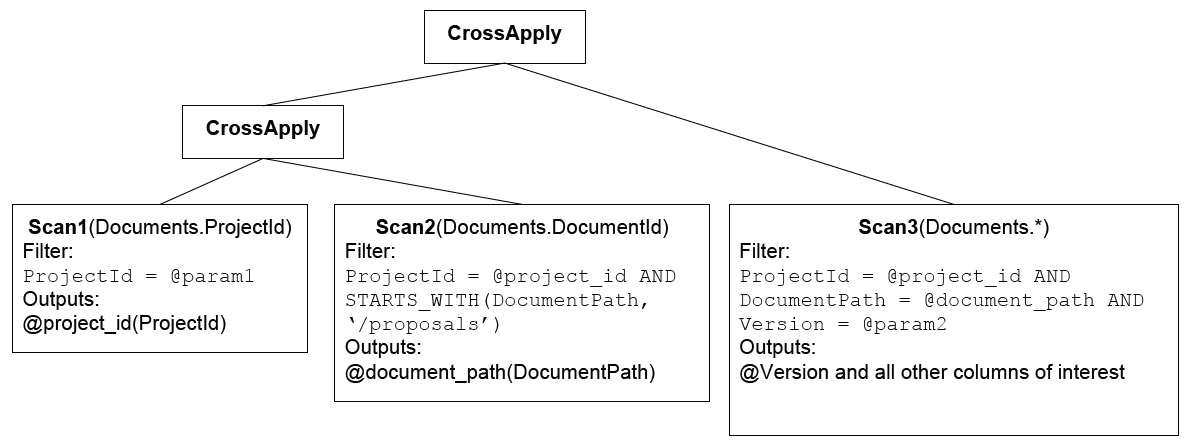 复杂的查询条件被逐渐拆开到每个scan上。其中,Scan1是包含一个常亮的条件@param1,Scan2和Scan3都是关联的(依赖前面的输出结果)。
复杂的查询条件被逐渐拆开到每个scan上。其中,Scan1是包含一个常亮的条件@param1,Scan2和Scan3都是关联的(依赖前面的输出结果)。
Scan1实际上是直接将结果(就是project_id=@param1)吐出来,Scan2依赖Scan1的输出,Scan3依赖Scan1和Scan2的输出。Scan2在执行时,首先seek第一个"/proposals/*",比如"/proposal/doc1",然后跳过doc1的所有行到doc2。Scan3是最右Scan,因此它会把所有列输出出来。
跟同事简单讨论了下,优化器会把一个filtered scan改写成self-join,一些可能的原因是Scan2可以选择特定个索引,比如Scan1过滤完,还是有大量的shard或者fragement,第二步有机会做一些pruning。
Complile-time rewriting会执行如下的normalization steps:
- NOT会被push到leaf predicates
- predicate tree的叶子上,如果引用到了列,就把列隔离出来(列+运算+参数的形式)。比如1>k改成k<1,NOT(k>1)改成k<=1。
- 整数区间离散成列表。k BETWEEN 5 AND 7改成k in (5,6,7),离散值太多就放弃。
- 消除包含子查询和复杂的算数函数的条件(消除指的是改成post-filter?)。
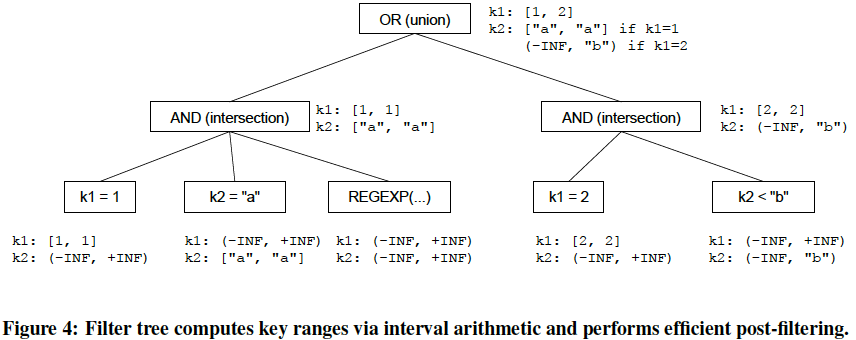
Filter Tree
Filter Tree是运行时的数据结构,既用于通过自底向上的交并区间来抽取range,也用于post-filtering self-join的结果。

Query Restarts
Spanner的一个目标就是要解决瞬时故障导致的query失败。
使用场景和好处
- 隐藏瞬时故障:网络断、机器重启、Spanner进程Crash、副本无响应时换其他副本、数据迁移导致的查询失败。
- 简化编程模式:不需要客户端自己写重试逻辑,因为重试前要客户端确保上一次操作回滚干净。
- 支持查询结果流式分页:有些应用希望使用分页的方式(例如SQL的LIMIT/OFFSET)逐步处理查询结果。
- 减少在线请求的tail latency:开销小的局部的重试。
- 支持long-time查询:对于执行时间长到跟MTTF差不多的查询,如果不支持局部重试的话,失败率太高。
- 日常滚动升级系统:对运维人员是个好消息。
- 简化Spanner内部错误处理:错误处理的复杂度很大程度被隔离到restartable RPC层。
Restart Contract
重试约定:已经消费的数据,在重试后,不能再次提供。
实现重试机制的原理很简单:执行过程中,捕获执行状态。查询执行过程中每个消费数据的地方都维护一个restart token(比如记录cursor相关信息),用于维护结果消费进度。
但显然,工程实现上的细节非常复杂,比如如下几个问题:Spanner支持动态resharding,重试查询的结果集顺序可能会变,服务器升级后还要考虑各种各样的兼容问题。
Common SQL Dialect
主要讲述Spanner的SQL选型,怎样支持标准,内部系统兼容(甚至一些代码组件会拿出来在不同系统共享),测试Case等。这块在工程上很消耗人力。
Blockwise-Columnar Storage
Spanner最早是基于Bigtable,底层存储使用LSM,没有schema,一行数据通常较大(会有自解释的附带信息)。为了支持HTAP,Spanner使用了Ressi格式来存储数据。
Ressi整体上还是LSM Tree结构,在每一层,大致还是按行,但在块级存储上,会按照PAX格式列存,再配备多级索引。
此外,因为Spanner支持行级多版本,考虑到行级版本冷热,会将同一行的老版本和新版本分开存放在不同的物理文件。
还有一个细节是,如果一行非常大(类似于blob),会将这一行拆开存放在多个文件中,如果不是真的要读这一行,就有机会优化成只读一部分。
Lessons and Challenge
Spanner从一个可扩展、容错、事务性分布式NoSQL系统演化成了一个支持SQL、强schema的数据库系统。内部的统计表明,在Google内部SQL接口还是很有市场的。
Spanner一直在持续优化TrueTime的误差(个人认为,如果能优化到亚毫秒级,简直就解决了分布式系统一个根本问题了)。
不过,论文提到因为Spanner提供了丰富的layout选项(地理位置部署、副本复制、树状层次、分库分表),Spanner工程师也会花很多时间review应用的shema设计。
另一个经验是,不要随便动优化器。优化器太敏感,一个小的改动,可能导致一些关键应用的延迟飙升两个数量级(关键应用最好拿个outline框住?)。
最后,虽然one-fit-all被人批判,但AP & TP融合对业务很有价值,所以Spanner还是会做HATP。