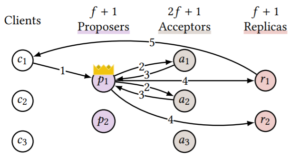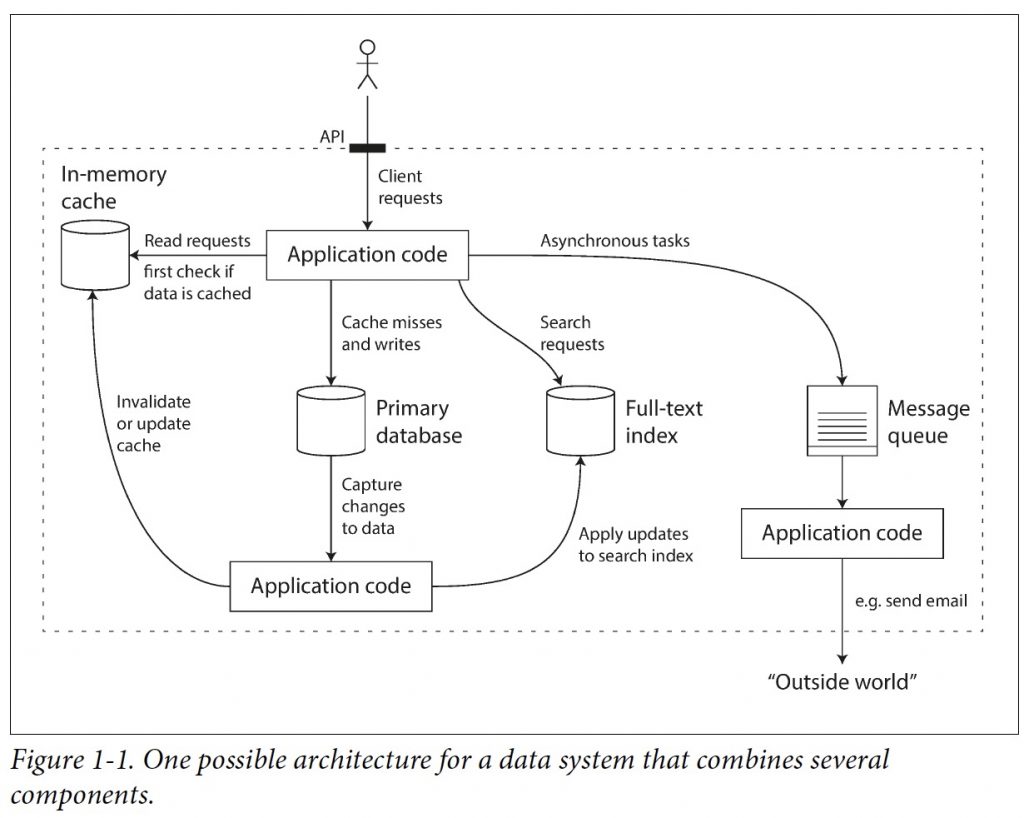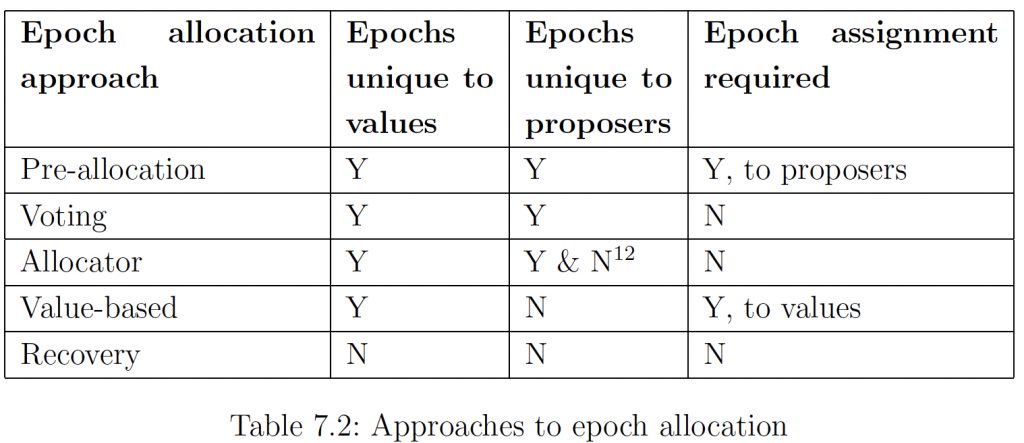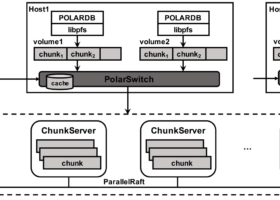
《PolarFS : An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database》 VLDB2018
Introduction
存储计算分离:
存储节点和计算节点可以分别独立灵活配置硬件
存储池化,降低碎片、利用率不均、空间浪费,存储集群的容量和吞吐透明水平扩展
计算节点无状态,数据库弹性更好(迁移更容易),可靠性提升
PolarFS:
利用RDMA和NVMe SSD新硬...