InMemoryDB并发控制算法评估
这篇工作梳理了MVCC的四个要点:
- 并发控制协议
- 多版本存储
- 垃圾回收
- 索引管理
还介绍了MVCC的多种变体原理,实现了这些变体,然后在OLTP workload上测试评估各个变体的效果。
MVCC基础
MVCC介绍
MVCC是一种并发控制算法,一个数据库对象可能会被并发操作,算法维护同一个对象的多个版本来提高并发度,例如只读事务可以访问旧版本数据从而避免阻塞写。基于版本号也容易实现系统快照和time-travel。
多版本粒度可大可小,不过一般选择行记录粒度来实现多版本,因为粒度太细则多版本的维护开销就太大。
MVCC历史
1970年理论提出,1981年 InterBase DBMS(now FireBird)首次实现。
主流的DBMS都实现了MVCC(Oracle 1984, Postgres 1985 MySQL InnoDB 2001)。目前MVCC基本上是DBMS的标配了。
MVCC基本概念
行格式
![]()
- txn-id:一般同时用作行latch,设定为64比特以支持CAS原子操作
- begin-ts ~ end-ts:行的生存周期,如果被delete,可以设置begin-ts=INF
- pointer:指向下个版本
Concurrency Control Protocol
这节介绍四种并发控制协议:MVTO、MVOCC、MV2PL、Serialization Certifier。
Timestamp Ordering (MVTO)
最原始的MVCC实现算法,行格式在原有格式基础上再加上read-ts列。
读请求:Tid作为快照点读取对应版本
- 事务T读行A时,首先找到满足begin-ts < Tid < end-ts 的版本行Ax;
- 然后检测Ax的write-lock(即txn-id列)是否被活跃事务持有,如果被持有,说明是正在更新的行,不可读;
- 如果可读,读前先将Ax的read-ts推大到Tid。
写请求:写请求总是更新最新版本的行
- 如果满足条件 (没有活跃事务持有Bx的write-lock) && (Tid大于Bx的read-ts),则事务T创建新版本Bx+1,设置Bx+1的txn-id为Tid。
- 事务T提交时,设置Bx+1的begin-ts=Tid, end-ts=INF, Bx的end-ts=Tid。
- 这个算法是将事务严格按照Tid排序的;写请求不满足条件时,要被abort。
Optimistic Concurrency Control (MVOCC)
乐观的并发控制,这里假设了冲突并不多,并不需要预先申请锁再执行修改。
MVOCC将事务分成三个阶段:read phase、validation phase、write phase。
- read phase:执行阶段,类似于MVTO,读请求根据begin-ts和end-ts区间查找可读的Ax;写请求如果发现没有write-lock,则可产生Bx+1新版本,并且Bx+1的txn-id设为写事务Tid。写操作仍然只能更新最新版本(防止lost-update)。
- validation phase:给事务分配一个提交时间戳Tcommit作为序列化次序,如果事务的读集合没有被其他事务提交更新,则可以提交。
- write phase:DBMS将新版本写入系统,设定begin-ts=Tcommit, end-ts=INF。
Two-Phase Locking (MV2PL)
这个算法使用2PL来保证事务可串行化隔离级别。
事务执行读/写操作前需要先申请读/写锁。In-memory DBMS中,锁借助行格式里面的txn-id作为写锁,新增一个read-count作为读锁(也可以将二者编码成64bit方便操作)。
- 读操作要先确认没有其他事务持有写锁,然后找到合适区间的版本后,要给这一行加读锁,即read-count递增1。
- 写操作要确认没有事务持有读锁或写锁,然后创建新版本。
- 提交时,分配Tcommit时间戳,类似于MVOCC的write phase。
如何处理死锁是2PL的主要差异,研究表明 no-wait策略是最scalable的deadlock prevention方法。
Serialization Certifier
serialization certifier维护一个serialization graph,检测和移除"dangerous structure",进而提高隔离级别。
serialization certifier是一套机制,最早实现这套方案的是Postgres的SSI(Serializable Snapshot Isoation)。
相比Serializable,SI隔离级别不能避免A5B Write Skew。所以通过维护anti-dependency来避免A5B,就可以提升隔离级别。
具体我们另文描述(Serialization Certifier,SSI,SSN)。
几种MVCC机制讨论
MV2PL每次读都要更新read-lock,MVTO每次读都要更新read-ts,这两者性质其实差不多。MVOCC读的时候不需要更新什么字段,可以减少修改操作,但在validation阶段需要验证整个read-set。Certifier算法可以降低abort rate,因为它不验证读,但是anti-dependency的检查需要额外的开销。
speculatively read优化:允许事务读未提交数据,但要等被依赖的若干事务提交后才能提交本事务,有cascade abort的风险。
eagerly update优化:要维护中心化的数据结构来记录依赖关系,同样也有有cascade abort的风险。
Version Storage
这节介绍多版本存储的几种方法。In-Memory DB中,通过指针将多版本数据串起来。
Append-only Storage
将多版本存放到相同的存储空间,例如Postgres/Hekaton/NuoDB/MemSQL等。更新时,先分配一个槽位,然后拷贝旧值,再做修改。
因为数据结构层面实现一个latch free的双向链表非常难,所以多版本链用的是latch free单链表。这样就有两中串链的方式:
Oldest-to-Newest(O2N) 链表头是最老版本
- 优势:新增版本时,不要更新索引结构,因为索引结构指向的是最老版本(间接指向最新版本)
- 劣势:访问最新版本时需要遍历链表,遍历链表很容易污染CPU Cache,所以需要及时prune旧版本数据
Newest-to-Oldest(N2O):链表头是最新版本
- 优势:访问最新版本不需要遍历链表
- 劣势:新增版本时,需要更新索引结构(6.1节讲了一个优化)
Append-only Storage方案需要处理BLOB的问题,如果BLOB列本身没有更新,可优化为多个列BLOB引用同一个物理BLOB。
Time-Travel Storage
跟Append-only Storage方案类似,不过在主表里面维护一个master version(一般是最新版本,也可以是最老版本),其他版本单独存放到另一张表(time-travel table)。
Delta Storage
跟Time-Travel Storage类似,只是除了主表空间维护的master version,其他版本只维护delta部分(存储在delta storage),类似于MySQL/Oracle的回滚段。这个方式在比较大的行只修改其中少量列的情况下,可以节省很多空间。
Garbage Collection
当一个旧版本数据不再对活跃事务可见,那么这个旧版本就可以回收了。
最简单的方式就是维护一个活跃事务列表,找到列表中最小的Tid,比Tid还小的,就都不可见了。这个方式的主要问题是这个活跃事务列表是个中心化的数据结构,在多核情况下,会成为扩展性瓶颈。
另外一个方式是epoch-based回收机制,这个跟lock-free中的EBR是一样的原理,略。
两种GC粒度的模式:tuple-level 和 transaction-level。
Tuple-level GC
Background Vacuuming (VAC)
后台线程周期地扫描过期版本,这个方法扩展性不好,数据量大的场景下扫描效率会非常低。
为了解决该扩展性问题,可以在事务失效一个旧版本时,将该旧版本放到特定的高效数据结构里面。
或者可以优化为,将数据按区域划分多个区间,并且使用位图标记,只扫描那些可能需要回收的区间。
Transaction-level GC
用epoch管理transaction,transaction过期的时候,删除该事务产生的老版本。
Index Management
索引结构里面通常只索引一个版本,然后从这个版本开始访问版本链,进而找到可见的版本。
数据库索引通常有主键索引和二级索引(这个划分来自存储引擎簇集索引方式)。主键索引总是指向最新的版本,至于写请求是否需要涉及修改索引,具体情况具体分析,N2O这种需要总是更新。主键的更新会被DBMS换成DELETE & INSERT组合。
二级索引复杂一些,通常有如下两种方式:logical pointer 和 physical pointer。
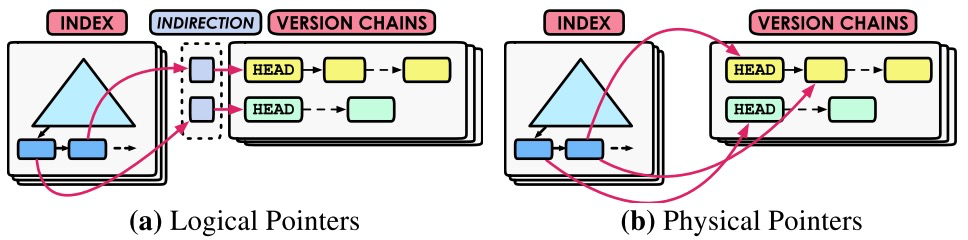
- Logical Pointer:索引指向的是一个间接的map,这个map是固定区域。
- Physical Pointer:指向版本链表。
索引管理跟其他模块关联比较多,除了索引结构本身外,单独讨论索引管理的接口似乎没什么抽象地可讨论的。
Experiment Analysis
实验环境
在CMU数据库团队的Peloton上尽最大努力实现了这几项算法。Peloton是行存,数据存放到内存堆表,内部用cuckoo hash索引,BwTree作为数据库索引,然后给Peloton搞了一些latch free的优化。实验是在Serializable隔离级别下测试的。EBR用的是40ms参数。Benchmark:YCSB(modified on oltp workload), TPCC,两个经典的benchmark。
这里有两个问题:第一个是隔离级别太高,通常互联网业务很少用Serializable隔离级别;第二个是硬件配置低,跟目前主流的服务器配置差的有点远(10核20线程)。我觉得这两个问题对可参考性影响比较大。
后面是具体的测试,我们不再逐个看了,有需要关注特定点的同学可以自行参考。
Discussion
- version storage是扩展性里面最重要的组件,以前的研究认为是并发控制协议。append-only和time-travel两种方式下,底层的内存分配对性能影响很大,将内存划分到per-core方式可以解决这个问题。Delta Storage方式可以在不需要对内存分配做优化的情况下仍然保持相当的性能,但是这种方式scan性能不行。
- 选择一个适应workload的并发控制协议可以提升性能。MVTO在很多场景下表现不错。但是论文列出来的一些业界流行的数据库产品并没有使用这个算法。
- MVCC性能跟GC关系很大,二者耦合很紧。实验发现按照事务粒度回收旧版本效果好一些,可能是因为这个方法减少了线程同步开销。GC进程可能会导致tps不稳定。
- Index management也会影响二级索引的性能。
我的一点总结
论文总结了MVCC的四个技术点,分析了几种MVCC算法,并作了一些测试。
但是我觉得这个工作有几个比较大的问题:
- 硬件配置跟目前主流服务器差距比较大(64核、DB几百线程这样的配置在17年也不少见)
- 仅测试了serializable隔离级别,但是互联网业务大部分都是RC或者RR,不同隔离级别对这个工作的影响应该是很大的。
- 仅测了In-Memory DB的情况,相对还是比较窄
- 并发控制算法效果很依赖代码实现
- 个别比较奇怪测试结果没有解释原因
这几个因素让这个测试结果的参考价值打了折扣。
1 条留言 访客:0 条 博主:0 条 引用: 1 条
来自外部的引用: 1 条