PolarFS论文
《PolarFS : An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database》 VLDB2018
Introduction
存储计算分离:
- 存储节点和计算节点可以分别独立灵活配置硬件
- 存储池化,降低碎片、利用率不均、空间浪费,存储集群的容量和吞吐透明水平扩展
- 计算节点无状态,数据库弹性更好(迁移更容易),可靠性提升
PolarFS:
- 利用RDMA和NVMe SSD新硬件、轻量级的用户态网络和IO栈
- POSIX-like文件系统API,替换原有OS的posix接口
- 高效的IO模型:消除锁和上下文切换,减少不必要的内存拷贝
PolarFS支持PolarDB:
- PolarFS支持sync元数据,允许RO感知元数据变更
- 并发的元数据变更串行化
- 网络分区时,可以保证只有一个节点可以写共享文件
Background
- NVMe SSD(500K IOPS,<100us延迟)、3DXPoint SSD(~10us)等低延迟设备下,内核IO栈已经成为了瓶颈。
- RDMA:同交换机下4KB的包需要7us。PolarFS用混合的Send/Recv和Read/Write,大量数据用SR,小包用RW,polling CQ以避免上下文切换。
Architecture
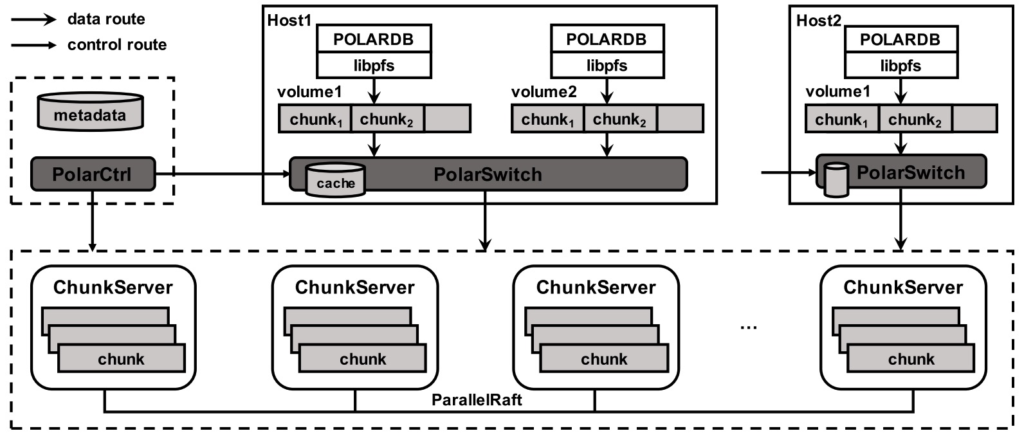
整体架构分成两层:
- 下层是storage layer:负责管理所有的磁盘资源。
- 上层是fs层:负责管理文件系统元数据,提供FS API,解决并发访问的互斥和元数据同步。
组件:
- libpfs:用户态文件系统库,提供类POSIX接口,链到PolarDB进程里面。
- PolarSwitch:驻留在计算节点,将IO请求重定向到ChunkServer。
- ChunkServer:部署在存储节点上,服务IO请求。
- PolarCtrl:控制面,由多个微服务组成,所有的计算节点和存储节点上都部署agent。
FS layer
FS层提供的是一个共享的、并行的文件系统,面向多个db实例并发访问。比如一个实例创建了文件,其他实例要能看到。
- pfs_mount:database启动的时候,将该database的volumn通过pfs_mount挂载,并初始化fs状态,读取volumn的元数据、构造内存数据结构(目录树、文件映射表、块映射表)。
- pfs_umount:database实例销毁时,pfs_umount将detach对应的volumn,释放资源。
- pfs_creat/read/write/pread/pwrite/lseek/fstat/fallocate/truncate/mkdir/readdir:类似于POSIX的接口
Storage Layer
Volumn & Chunk & Block
每个database实例对应一个volumn,每个volumn对应若干chunk。volumn可以通过追加chunk的方式扩展空间。chunk分散存储在一组存储节点上,每个chunk有三个副本以支持高可靠和高可用。
chunk大小是10G,该大小设置比GFS的64M大很多。
- 优势是chunk数量少很多,元数据管理简单,可以完全缓存到PolarSwitch内存中。
- 劣势是热点chunk无法进一步打散,不过整个系统层面看,负载还是均衡的。
Chunk会进一步划分为64K的block,block按需细粒度供应。
一个10G的chunk包含16384个block,LBA(Logic Block Address,线性地址0~10G)到block的映射表存在ChunkServer本地,映射表大概占640KB,可以完全cache在内存。
PolarSwitch
PolarSwitch部署在每一台database server上,一台server上可以有多个database实例。每个database实例的libpfs将IO请求转发给PolarSwitch daemon请求上带有地址信息(volumn id, offset, length),根据这些地址信息可以确定要访问的是哪个chunk。如果一个请求跨多个chunk,则会被拆成多个子读请求。每个请求最后都会被路由到对应chunk的leader replica上执行。路由信息在metadata中保存,本地会有一个cache,与PolarCtrl同步。
ChunkServer
ChunkServer部署在存储节点上,一个存储节点可能有多个ChunkServer进程,每个进程负责单独的一块NVMe SSD盘,并且绑定特定CPU,因此不会有ChunkServer之间的资源竞争。
ChunkServer负责存储chunk,提供随机读写。每个chunk包含一个WAL,WAL写在3DXPoint SSD buffer,不足时先回收,不能回收时WAL写到NVMe SSD。chunk数据本身始终写到NVMe SSD。
ChunkServer可能会因为瞬时失效或者永久失效暂时无法响应,瞬时失效的ChunkServer可以自己尝试重新加回来,PolarCtrl也会做一些补充策略,识别瞬时还是永久失效。
PolarCtrl
控制面,负责节点管理、volumn管理、资源分配、元数据同步和监控等服务,该服务本身也要多机高可用。
具体职责:
- 负责追踪所有ChunkServer的成员组和在线情况,启动迁移任务
- 在metadata db中维护所有的volumn和chunk的位置信息
- 创建volumn,分配chunk到ChunkServer
- 同步metadata到PolarSwitch(push & pull)
- 监控每个volumn/chunk的延迟和IOPS指标
- 周期地触发replica间和replica内的CRC校验
IO Execution Model
数据库场景下,如果pfs_fallocate预先分配好文件块,写请求基本都不需要同步元数据。
libfs根据索引映射表将文件offset映射为block偏移,并将文件IO请求拆成多个定长块的IO请求,通过shared memory发送给PolarSwitch。
具体地,shared memory上有多个ring buffer,PolarDB将写请求投入其中一个,并等待请求完成。PolarSwitch针对每个ring buffer有一个线程做polling,发现有新的请求,则将请求从ring buffer拿出来,转发到对应的ChunkServer。
ChunkServer使用WAL来保证IO请求修改数据的原子性和持久性。Log被复制到其他副本,用的是ParallelRaft协议。多副本持久化之后,该IO请求就被认为提交成功了。
大致的IO执行流程如图:
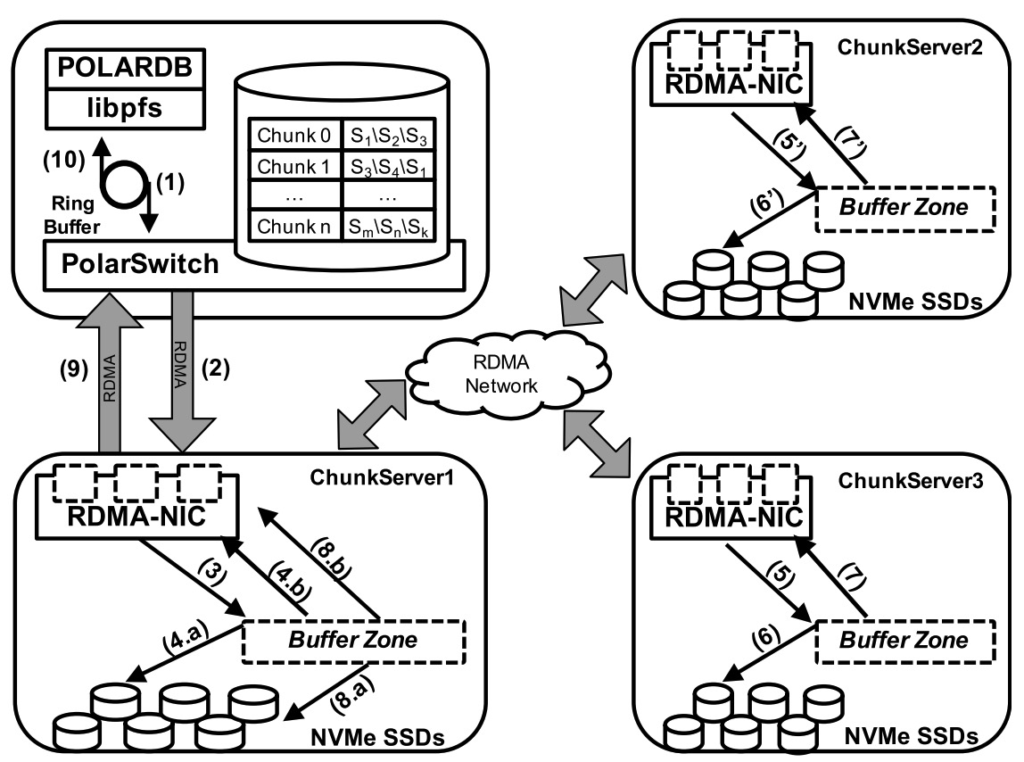
ChunkServer内部有一个IoScheduler,负责协调并发的IO请求。
ChunkServer使用一个polling模型和事件驱动的有穷状态机。IO线程polling RDMA和NVMe队列里面的请求,并在该线程中处理请求。当一个IO请求需要触发其他异步子IO请求时,线程会保存上下文,然后执行下一个polling到的请求。每个IO请求都有一个单独的cpu core和独立的RMDA和NVMe队列。总体上,IO线程不需要有任何共享数据,因此也不会有锁等待的开销。
Consistency Model
Raft的主要限制是必须顺序确认。在高并发多连接通信的情况下,请求乱序的概率大增,导致后面的请求被迫等待,整个吞吐和长尾延迟变大。
PolarFS对Raft进行了改进,允许乱序确认,并允许一定程度的乱序apply,协议称为ParallelRaft。
乱序确认带来的问题是,新选出来的leader的日志里面可能出现空洞,这时候,要先执行一个merge过程,将所有已经确认的log entry补上,然后再真正成为leader,提供读写服务。merge过程补log entry的过程跟basic paxos一致,prepare一个prepare quorum,然后取MaxVote重新投票。
乱序apply的实现方式实际上跟状态机有关,因为log entry记录的是对data file的block的修改cmd,所以如果两个log entry修改的是不同的block,实际上就可以并发。在日志有洞的情况下,如果每条日志都记录了本条日志以及它前N条日志修改的block id(论文里面叫look behind buffer),实际上就可以做到最大为N的窗口并发。这个思路实际上也是通用的,只要能萃取出本条日志以及前N条日志的冲突关系,就可以做并发apply。
FS Layer Implementation
主要是两块:
- 组织元数据,单个database节点上读写文件和目录
- 跨database节点的元数据协调和同步
Metadata organization
fs元数据包含三种:directory entry、inode、block tag。
- directory entry:包含path中的某级名字和指向inode的引用,一组dentry组织成directory tree。
- inode:可以代表一个普通文件或者目录文件。如果是普通文件,inode保存了一组block tag。如果是目录文件,inode保存了指向子目录项的引用。
- block tag:记录了file block到volumn block的映射。
三类数据类型,抽象为MetaObject。每个database实例对应一个volumn,pfs_mount时就要加载该volumn上的元数据。每个MetaObject用<metaobject_id, metaobject_type>确定,metaobject_id的高位确定所在chunk,metaobject_type确定chunk内的该类型对应的group,metaobject_id的低位用于group内唯一确定该对象。
Coordination and Synchronization
PolarFS要支持并发读写,就要处理:
- 元数据更新的原子性
- database实例间元数据同步
- 多个节点并发写(网络分区可能存在多个节点都认为自己可以写)
元数据更新原子性跟普通文件系统一样,依赖journal文件,元数据变更先原子地写入journal文件,然后再更新元数据。
database实例间元数据同步解决方法是database节点polling这个journal文件。
多个节点并发写的解决方法是使用disk paxos实现分布式锁,避免多个节点同时更新。一个节点更新时,如果加不上锁,则要等前面已经持锁的节点释放后,本节点重新加载journal文件最新的变更项,刷新本地后重试本节点元数据变更事务。
在这个场景里,Disk Paxos要达成一致的是 ' 谁是leader & journal文件写到哪了 ' 。分布式锁用完要主动释放。
Design Choices And Lessons
Centralized or Decentralized There
集中式系统,如GFS,通常依赖单个master节点来管理元数据,优点是实现简单,缺点是有单点瓶颈。
分布式系统,如Dynamo,优点是可靠性更高,缺点是实现更复杂。
PolarFS做了折中,PolarCtrl是集中式的,但ChunkServer之间是分布式的。
Snapshot from Bottom to Top
PolarFS和PolarDB两层都有自己的事务日志来支持原子性和持久化。PolarFS提供了disk outage consistency 给PolarDB/libpfs来支持数据库层面做一致性快照。disk outage consistency是指存在一个较小的时间区间![[T_0, T_{trigger\_snapshot}]](http://loopjump.com/wp-content/plugins/latex/cache/tex_470fd47db05807a38a3ce8f62241d621.gif) ,区间左侧发生的IO请求的效果均在快照内,区间右侧均不在快照内,区间内不确定。
,区间左侧发生的IO请求的效果均在快照内,区间右侧均不在快照内,区间内不确定。
实现方式:PolarCtrl发起,通知PolarSwitch,PolarSwitch给请求打标来卡区间,ChunkServer上用copy-on-write方式实现。
Outside Service vs Inside Reliability
降低恢复时间:将chunk拆成多个小的128KB的piece,复制一个chunk的任务变成了一组复制piece的子任务,整体可以提升恢复时间(也消耗了更多的资源)。