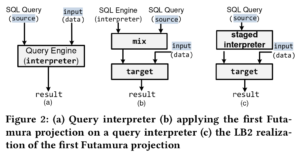
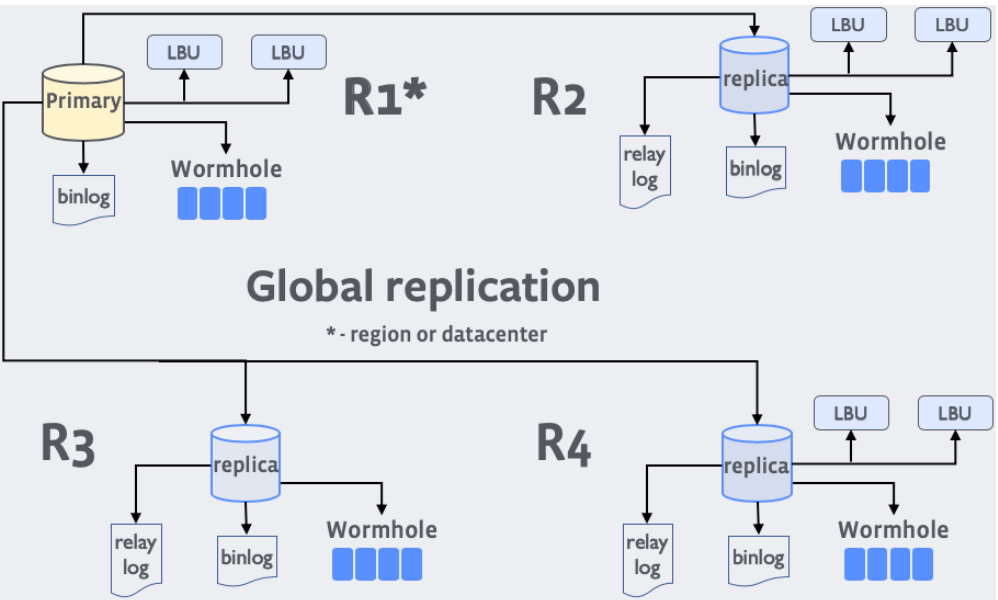
How to Architect a Query Compiler, Revisited》 SIGMOD'168
数据库执行一个查询的流程包括前端语法解析、优化器以及后端解释执行。语言编译器的流程与之类似,除了最后一步会编译成机器码执行,DBMS一般还是解析执行的。
在相当长一段时间内,硬盘IO是主要的性能瓶颈,计划的解释执行有利于移植,因此将解释执行替换成编译执行没有太大必要。但NVM硬件发展和业务对AP型查询需求增多,使得很多时候查询是...
Bitcask是由Basho公司搞的一个产品。
技术设计
数据顺序追加到磁盘上的active data file,并在内存中建立hash索引。
active data file文件长到一定程度就切成old data file,新的数据写入新的active data file。
old data files定期merge成一个merged data file,merge过程中同时会生成一个hint file来索引这个merged data file。
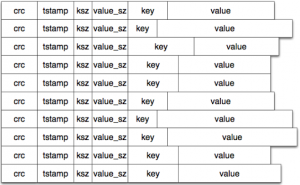
data file存放格式
内存keydir
是一个key -> <file_id, valu...
《An Overview of Query Optimization in Relational Systems》PODS 1998, Microsoft Research
优化器的输入是用户查询,负责生成一个高效的执行计划,优化过程是一个比较复杂的过程。
优化器主要包含三个部分:
Search Space:搜索空间包含足够好的计划
代价估计:代价估计足够精确
枚举算法:枚举算法要足够高效
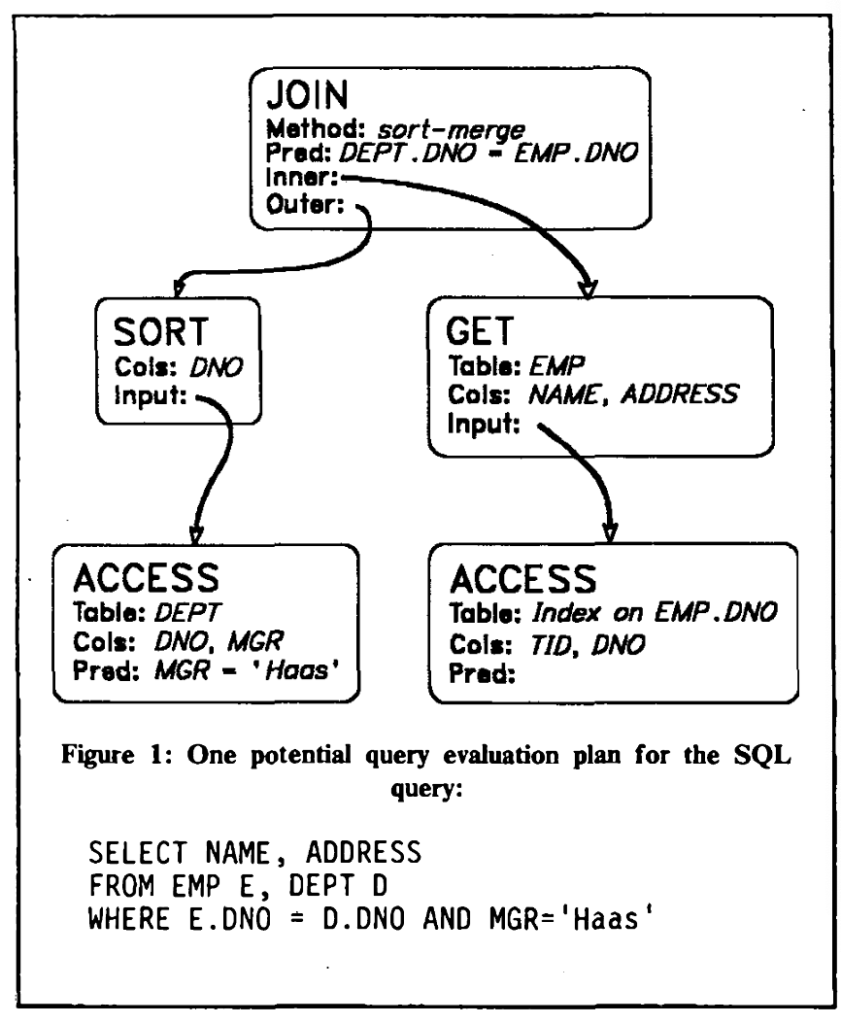
System R优化器案例
以System R为例来初步看下优化器的这三部分,通过这一节,对优化器...