再读Bigtable论文
bigtable论文解读。介绍了基本概念、设计实现和一些细节优化。
本文是Bigtable论文的阅读笔记,比较简略。
1 基本概念介绍
Bigtable本质上是GFS之上对GFS文件数据的一层索引。
1.1 Bigtable的数据模型
一个稀疏的分布式的持久化的多维度的排序的map。所谓map,就是key-value对。
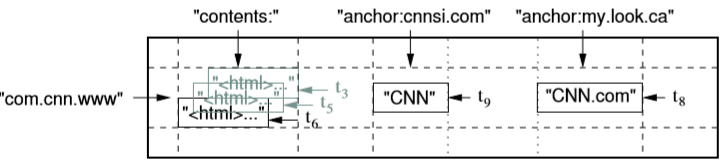
如图示,bigtable的数据模型是:
(row:string, column:string, time:int64) => value:string
即,行+列+时间戳作为key来索引value。
行可以是任意的字符串。单行的读写是原子的。
列分为两级,column family和qualifier。要求family的字符串可打印,qualifier可以是任意字符串。通常column family数目有限,qualifier可以很多。列是访问控制和访问磁盘的单位。
时间戳可以由bigtable指定或者用户指定。时间戳相当于数据的版本号。Bigtable会回收过于旧的数据,用户可以指定保存多少个版本的旧数据,或者指定一个时间戳,该时间戳之前的数据不要了。
1.2 API
API比较简单,不再赘述。如例。
写操作
|
1 2 3 4 5 6 7 8 |
// Open the table Table *T = OpenOrDie("/bigtable/web/webtable"); // Write a new anchor and delete an old anchor RowMutation r1(T, "com.cnn.www"); r1.Set("anchor:www.c-span.org", "CNN"); r1.Delete("anchor:www.abc.com"); Operation op; Apply(&op, &r1); |
读操作
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Scanner scanner(T); ScanStream *stream; stream = scanner.FetchColumnFamily("anchor"); stream->SetReturnAllVersions(); scanner.Lookup("com.cnn.www"); for (; !stream->Done(); stream->Next()) { printf("%s %s %lld %s\n", scanner.RowName(), stream->ColumnName(), stream->MicroTimestamp(), stream->Value()); } |
1.3 Tablet
所谓bigtable大表,是说行数非常多。Bigtable将表按行进行范围分区(range partition),每个分区就是tablet(子表)。
每个tablet由若干个SSTable文件组成,SSTable(Sorte Static Table)文件是一种格式设计良好的用于保存key-value的文件。每个SSTable文件保存的key-value按顺序排好,数据不可修改(只能merge形成新的SSTable,后详)。SSTable的一个优点是文件包含一个对自身数据记录块的索引。索引通常一直缓存在内存,所以指定SSTable文件读数据时,通常只需要一次磁盘操作。关于SSTable的格式,读者可以参考leveDB,文末附有一个地址,供参考。
1.4 Chubby
Bigtable非常依赖Chubby。Chubby是google的分布式协调系统。读者可以参考ZooKeeper。
这里对ZooKeeper做一个简单介绍。ZooKeeper是一个分布式协调系统,多个机器通过Zab协议(类Paxos)对外提供一个一致的树状的文件系统的界面视图,与一般的文件系统不同的是,ZooKeeper可以监听客户端的连接,监听数据变化。 例如,客户端可以阻塞地监听一个文件,直到该文件被删除时被唤醒(常用来实现分布式锁)。文末有几个链接,供参考。
2 实现
Bigtable包含三个部分,客户端lib,master server,tablet server。架构类似于GFS。
2.1 Master Server
Master server的功能
1.将tablet分配到tablet server。
2.检测tablet上下线。
3.负载平衡。
4.垃圾回收。
5.处理schema change。
Tablet到tablet server的映射信息,即location信息,也是作为表保存起来的,这个特殊的表称之为METADATA表。METADATA表的每一行记录了一个用户的tablet的位置信息,其内容大致如下:
< (tablet_id, end_rowkey), location_info, other_info >
METADATA表作为一个表,也会分为tablet。它的第一个tablet比较特殊,称为Root tablet。Root tablet的每一行记录的是METADATA的其他tablet的位置信息。Root tablet的位置信息保存在Chubby的一个文件中。因此,我们可以从Chubby中这个文件开始找到所有的tablet。
三级的索引结构能管理多少数据呢?假如tablet大小是128M,一行记录1K。那么能管理的tablet数目是:(128M/1K)^2 = 2^34个tablet,约2^61字节的数据。应该是很大了。
有了location的索引结构,客户端lib在实际运行时,会cache一些结果。一开始启动时,需要从chubby file开始访问三次拿到location信息。如果一段时间后发现location cache失效了(根据location cache查找tablet server失败),此时最多6次访问可以更新locaion cache(三次向上逐级发现location cache失效,三次更新正确的location cache)。
2.2 Tablet assignment
每个tablet server启动后会在Chubby的serves目录下建立一个标识本server的文件,然后在该文件上加锁。加上锁标表示该tablet server能够服务。Master周期性地问每个tablet server的lock状态。如果master发现锁被释放了(tablet server宕机或者网络分区了),master就尝试加锁,加锁成功后删除该文件。文件被删除,意味着这个tablet server不能服务了,此时master负责重新分配tablet到其他tablet server。
Master server是如何知道所有的tablet server的呢?因为每个tablet server都会在servers目录下建立一个文件节点。Master只要扫描这个目录就能知道所有活跃的tablet server了。如前所述,根据METADATA,能够获知所有的tablet。然后Master问所有的tablet server分别服务了哪些tablet,进而建立映射关系。
Master server一启动就做这些事。当然,考虑到不能启动多个master server实例。Master启动时要先抢锁(chubby实现的分布式锁)。
Tablet集合的改变:创建、删除、合并、分裂。前三个都是master负责发起的。分裂是由tablet server发起的。因此分裂成功之后要告知master。
2.3 Tablet serving
下面说下tablet上的读写操作实现。
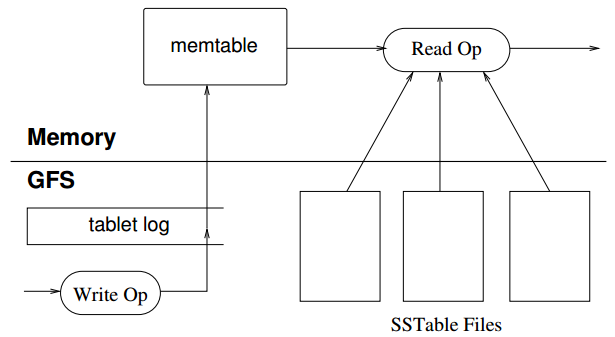
执行读写涉及到memtable,tablet log,sstable。
当新写一个key-value时,会先追加到tablet log(WAL,write ahead log)。Tablet log是类似于数据库redo log一样的日志文件。tablet log写成功了,本次写操作就已经被持久化了。此时插入memtable中。Memtable是一个排序的key-value序列(levelDB中实现为跳表skip list)。此时写操作成功。由于tablet log是追加写,因此写性能很高。
读操作比较复杂。如图示,读操作实际上看到的是memtable和若干SSTable。读操作需要从这些数据中读取想要的那条(考虑到新旧数据,要先读memtable,然后读最新的sstablet,以此类推)。读操作涉及到Cache,ScanCache是缓存KeyValue对,BlockCache缓存SSTable的block,是不同层次的缓存。
当memtable逐渐变大时,可以dump到磁盘上形成sstable文件。这个操作被称为minor compaction。
多次minor compaction之后,形成了多个sstable,会发起merge compaction。即将几个sstable做一次merge,形成一个sstable,减少sstable数目(提高读性能)。
此外,还有一个操作叫major compaction。即将所有的sstable做merge,最后形成一个sstable。
3 优化
3.1 Locality group
Locality group优化是说,将若干个column family在物理上存放在一起。不在同一个localilty group的column family会存放在不同的sstable文件中。这样,每个sstable存放的key-value条数更多,读性能更好。
3.2 Compression
3.3 Cache for read performance
两种cache。Scan cache是key-value数据级别的缓存。Block cache是sstable文件块的缓存。
3.4 Bloom filter
Bloom filter是个有趣的优化。它本质是bitmap的扩展(使用了多个hash function来标记多个bit)。Bloom filter可以高效地确定一个给定的key是否可能落在指定的sstable中。这样读取时,就能很大程度上避免扫描不必要的sstable。关于bloom filter见文末参考。
3.5 Commit log implementation
一台tablet server中只有一个commit log,这台tablet server上的所有tablet产生的log都混合写入该log文件。要不然会产生大量的并发写GFS文件的情况,而且减少了group commit(多个写操作合成一次写操作)的概率。
混合写的情况下,如果tablet迁移,则会导致每个tablet都要读取所有的commit log。对于这个问题,可以先对commit log排序(按照<tablet_id, rowkey, log_id>),排序之后每个tablet来读取时,只需要读取自己所属的那段就可以了,而且是连续读取,性能会好很多。当然,排序也有很多细节问题。为了提高排序性能,需要由master来协调并发排序。也只有当tablet server意识到需要从commit log中恢复memtable时才需要开始排序。
此外,还有一个优化。考虑到GFS追加写commit log时,可能因为网络抖动写不下去(GFS要将数据写到三个不同的机器上做备份),因此,bigtable创建两个log writer线程,每个log writer线程写自己的log文件。一个线程写不下去的时候,切换到另一个线程写(两个文件写流程很大概率走不同的网络线路)。
3.6 Speeding up tablet recovery
优化要点是迁移时避免回放日志。所以迁移前将metable先做一次minor compaction转为sstable静态数据。这里为了彻底避免回放日志,会做两次minor compaction。第一次时允许继续提供服务,第一次做完之后,停止服务,将第一次开始到现在时刻所产生的memtable再做一次minor compaction(这次数据量很小)。通过两次minor compaction,避免了长时间的不可用。
3.7 expoiltin immutability
这一节非常有意思。这一节实际探讨的是LSM(log structure merg tree)设计和实现上的一些特点。
因为sstable是静态数据,因此,对sstable的并发控制就很简单(平时不会被修改,不需要控制~~~)。对于memtable,有可能并发读写,因此实现的时候可以用copy-on-write的方式实现读写互不阻塞。
此外,tablet 分裂实现很简单,因为parent tablet和child tablets基本上是共享sstable的,很多sstable根本不会因为分裂带来任何修改。
4 Lession
几个经验教训:
1.分布式系统遇到的failure更多。
2.实现一个feature之前要明白使用需求(意思是有些需求可能不必要,比如跨行事务)。
3.恰当的系统级监控
4.简单设计。
Reference
Zookeeper
http://zookeeper.apache.org/doc/r3.3.2/recipes.html
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
http://www.searchtb.com/2014/03/zookeeper-in-offline-computing.html
leveldb
http://www.samecity.com/blog/Index.asp?SortID=12
Bloom filter
https://en.wikipedia.org/wiki/Bloom_filter
leveldb 的参考链接网址挂了
sigh,好可惜,这个链接的内容非常好。