Compartmentalization方式scale复制状态机
Scaling Replicated State Machines with Compartmentalization,VLDB 21'
本文是针对Multi-Paxos协议的实现方案瓶颈做的扩展性方案,主要的方法论是compartmentalization,这个词本意是分离,在这里作为一种方法论,其含义是将各个功能进行剥离分开,并分别进行扩展。
Multi-Paxos的多个模块都有一些实现方案上的瓶颈,假设读者已经熟悉Multi-Paxos协议内容,我们根据论文的思路看看各个瓶颈如何通过compartmentalization来扩展。
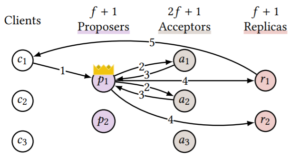
各个功能的Compartmentalization
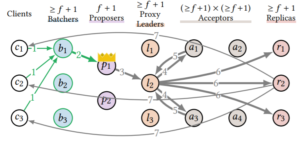
Proxy Leader
Proposer实际上有两块功能,一个是sequence,一个是broadcast。实际上这两个功能是可以拆开的,sequence本质上要求串行,但broadcast是完全可以并发起来的。基于此论文的方案是proposer和acceptor之间引入一层proxy leaders,proposer只负责sequence,一旦若干command确定了顺序,就可以由不同的proxy leader来负责broadcast。

Acceptor Grid
同flexible paxos,如图示。
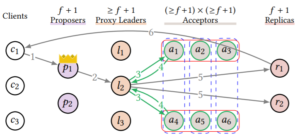
需要指出的是,虽然图中一个command被chosen只需要6个acceptor中的2个相比简单多数派的4个少很多,但该grid方式最差情况下只能容忍一个acceptor失效,而简单多数派可以容忍3个。
具体原理可以参考本站其他文章。
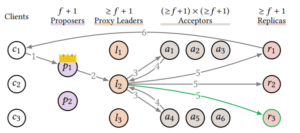
More Replica
一个已经chosen的command,在replica上执行,完成后回包给client。
扩展replica数目,可以降低每一个replica回包给client的负载,如图每个replica只需要回1/3。
Leaderless Read
Multi-Paxos读请求是发送到leader的,实际上读写路径可以剥离开。
读请求的处理类似于Paxos Quorum Reads方法,client先问read quorum,然后以最大的log index去replica上等该log index被apply然后读取数据。
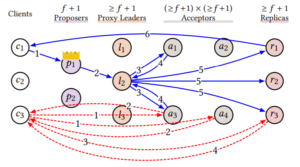
不过论文也没提发生leader change等情况,虽然解决起来应该也不麻烦。
Batch
就是常见的batch方法。专门搞了一层batcher来负责batch,减轻proposer负担。
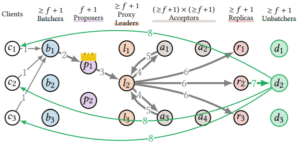
Unbatcher
Unbatcher是replica回包给client的时候,跟batch对应的一个操作,这个也可以直接scale。
分析
这篇论文的主要价值是提出了一个方法Compartmentalization,它的核心含义是分离功能并分别扩展。这是一种方法论思想,这种思想实际上在很多地方已经在用了,例如数据架构等等方面被称为disaggregation的方法也是类似的道理。
而且,Compartmentalization是基于已有方案做扩展性,思路比较直观,一看就懂,因此实现也比较简单。
但把Compartmentalization用在Multi-Paxos协议实现上这个想法也有一些需要探讨的地方。
首先,论文做的这个工作脱离业界太远,工业界真实的数据复制系统更看重复制的延迟,而不是节点的扩展性。一者论文中Compartmentalization一招鲜,文中大部分实现scalability的手段都是以牺牲延迟为代价换来的,二者即使节点瓶颈存在,整个业务大系统有各种sharding方案来扩展,着眼于复制系统的扩展性现实意义可能不大。
还有,Acceptor Grid优化思路只在比较多acceptor的情况下才有腾挪空间。业界大部分场景用的acceptor数目都是3,少量为5,除了4=2*2的情况下可以用grid(但只能容忍一个节点宕机,所以实用性有限),3和5都没用办法用。
另外,像SD-Paxos、EPaxos、Practical Fast Replication等在延迟和吞吐上做的优化相比Compartmentalization思路可能更优,当然协议比Compartmentalization更难理解,实现也更复杂。