Percolator论文阅读笔记
Percolator论文解读,Google用于替换MapReduce做页面索引的系统。
Percolator是Google在2011年发的论文,用于替换MapReduce做索引。核心是分布式事务和观察者通知机制。
概述
Google搜索引擎建立网页索引:通过处理网页库,会建好一个索引库。之后爬虫会新抓下来少量页面(相比于原始网页库的数量)。对于新抓来的页面,如何处理?有两种方式。两种方式差异如图示:
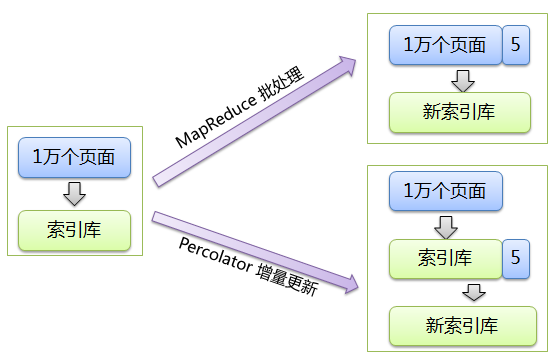
MapReduce批处理方式是新旧网页合并在一起,作为新网页库,通过MapReduce批处理建立新的索引库。Percolator采用了新的增量更新的方式,将新抓来的页面增量地更新到原来的索引库,形成新的索引库。显然,如果旧库很大,增量更新方式更优。这也是为何Google能更快地显示最新的搜索结果(论文后面说平均一个网页的处理延迟降低了100倍)。
论文Introduction一节第一段介绍了搜索引擎处理网页建立索引的一些特点。处理新抓取的网页时,系统会维持一些索引库的不变量(invariants),例如如果多个url对应的内容是一样的,那么只有PageRank最高的url出现在索引库中。如果一个链接指向一些重复的页面(不是很理解是个啥情况,跪求懂搜索引擎的同学指导一下),这个链接应该被转而指向PageRank最高的页面。
虽然我们不是特别清晰这个处理过程,不过基本懂个大概就差不多了。我们要注意的是,建立索引的过程是一个有特定数据约束的过程(即上文所说的invariant),我们要多线程并发地把索引库从一个满足一定约束的状态转换到另一个满足约束的状态。说到这个问题,可能我们就能明白为何题目large-scale incremental processing using distributed transaction and notifications中有transaction了。将一个数据集从一个一致的状态修改变为另一个一致的状态,这中间恰是事务Transaction要解决的问题。

关于这个问题,我们多解释一下“一致”这个说法。计算机领域有若干“一致”的说法,比如1) Paxos是一个一致性协议(consensus protocol)、2) Cache一致性(cache coherency)、3) CAP里说的Consistency、4) 数据库事务ACID中的一致性(Consistency)等。几个术语略显混乱,英文里面是不同的东西,中文全部翻译成“一致”,所以我们看到“一致”的时候要小心理解其含义。
Percolator跟几种系统的对比:
Percolator VS MapReduce:增量和批处理的区别;
Percolator VS Bigtable:支持强一致性的ACID事务和仅支持单行事务的区别。
Percolator VS RBDMS:能处理的数据量大小的区别。
分布式事务
Percolator的设计包含两个相对独立的要点,即论文题目中说的分布式事务和观察者机制实现的通知。分布式事务是为了支持应用通过事务方式方便地访问数据,观察者机制是为了组织增量计算。
在解释这两个设计要点之前,我们先看Percolator的软件栈及其对设计的影响。
Percolator是建立在Bigtable上的系统,也就是说Percolator使用Bigtable提供的API接口实现自身的功能。而Bigtable又建立在GFS之上。所以,当Percolator实现分布式事务时,会调用Bigtable的API,Bigtable又调用GFS的接口(例如append record)。这个调用层次比较深,可以想象,Percolator做一次调用,系统中各种层次的RPC穿梭的场景。所以性能必然不太好。例如,Percolator一个事务的提交延迟可能有几十秒。这在OLTP的场景下完全不能接受。然而,Percolator的性能好坏是跟MapReduce比,所以,增量vs批处理,Percolator妥妥地胜出(还记得100倍么?)。
也正是由于Percolator的这种软件栈,Percolator实现2PC(2 Phase Commit两阶段提交)协议来支持分布式事务时,其实现过程与我们所见过的直接构建在OS之上的2PC实现差别非常大。比如,传统RDBMS实现时可以使用OS提供的锁来控制并发访问临界资源。而Percolator是构建在Bigtable上,它能够使用的接口都是读写Bigtable中key-value的内容。另外一点,Percolator作为Bigtable的客户端,任何Percolator都可以发起请求,也没有一个合适的地方用于截获消息流、安置变量来作为协调进而实现锁。所以,Percolator不得不自己持久化锁,这样的话,Percolator需要再依赖另外一个支持持久化的锁服务,或者直接通过Bigtable实现持久化的锁(可以使用Bigtable的in-memory column实现高效的锁),也即将锁作为数据写入Bigtable。这也是理解Percolator所使用的数据表的schema的关键。
除了依赖支持持久化的锁服务,Percolator还依赖一个时间戳服务,这个服务用于支持快照隔离级别。在Percolator的实现中,论文中称之为Timestamp Oracle Server。名字叫啥不用太关心,我们要明确的是该时间戳服务器能够不断地产生严格递增的时间戳,而且要容忍宕机,需要注意的是,这个时间戳服务器是全局共用一个的,这也就极大地简化了设计。当然,由于是全局共用,系统中的每个事务都要多次访问该服务。为了性能,该服务实现时,可以实现为批发零售方式。比如,现在的已经持久化的时间戳是1000,服务器将时间戳改为1500并持久化,然后慢慢分1001~1500这500个时间戳。此外,另一个性能优化点是获取时间戳的请求可以成组地打包后发给时间戳服务器。
解释完Percolator所依赖的服务之后,我们看下Percolator的事务接口,也是执行一串语句之后COMMIT。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
bool UpdateDocument(Document doc) { Transaction t(&cluster); t.Set(doc.url(), "contents", "document", doc.contents()); int hash = Hash(doc.contents()); // dups table maps hash → canonical URL string canonical; if (!t.Get(hash, "canonical-url", "dups", &canonical)) { // No canonical yet; write myself in t.Set(hash, "canonical-url", "dups", doc.url()); } // else this document already exists, ignore new copy return t.Commit(); } |
我们下面正式进入Percolator的分布式事务解读。
先明确下Percolator的隔离级别。Percolator使用了MVCC(多版本并发控制),实现的是快照隔离(Snapshot Isolation)的隔离级别。关于快照隔离级别,读者可以参考本博客之前的博文浅谈数据库隔离级别。这里我们简单重述一下。
在快照隔离级别下,每个事务能够看到数据库的一个确定的快照。修改了同一数据的并发事务提交时,最多只有一个能提交。快照隔离级别低于Serializable的隔离级别,区别在于A5B Write Skew这种异常现象。
Percolator实现分布式事务的时候,对于参与事务的列,都额外增加了新的附加信息(换言之增加了Schema信息)。 例如,列除了数据之外,还有write和lock两个附加的信息(还notify和ack_O两列,是观察这机制有关的列,我们暂时忽略它们)。形如:

论文在正文中附带了半页的代码。还给了个转账的例子。不得不贴一下这个重要的代码,下面我们的解读就全部依赖这几十行代码了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
01 class Transaction { 02 struct Write { Row row; Column col; string value; }; 03 vector<Write> writes_; 04 int start_ts_; 05 06 Transaction() : start_ts_ (oracle.GetTimestamp()) {} 07 void Set(Write w) { writes_.push back(w); } 08 bool Get(Row row, Column c, string* value) { 09 while (true) { 10 bigtable::Txn T = bigtable::StartRowTransaction(row); 11 // Check for locks that signal concurrent writes. 12 if (T.Read(row, c+"lock", [0, start_ts_])) { 13 // There is a pending lock; try to clean it and wait 14 BackoffAndMaybeCleanupLock(row, c); 15 continue; 16 } 17 18 // Find the latest write below our start timestamp. 19 latest write = T.Read(row, c+"write", [0, start_ts_]); 20 if (!latest write.found()) return false; // no data 21 int data_ts = latest write.start timestamp(); 22 *value = T.Read(row, c+"data", [data_ts, data_ts]); 23 return true; 24 } 25 } 26 // Prewrite tries to lock cell w, returning false in case of conflict. 27 bool Prewrite(Write w, Write primary) { 28 Column c = w.col; 29 bigtable::Txn T = bigtable::StartRowTransaction(w.row); 30 31 // Abort on writes after our start timestamp . . . 32 if (T.Read(w.row, c+"write", [start_ts_, ∞])) return false; 33 // . . . or locks at any timestamp. 34 if (T.Read(w.row, c+"lock", [0, ∞])) return false; 35 36 T.Write(w.row, c+"data", start_ts_, w.value); 37 T.Write(w.row, c+"lock", start_ts_, 38 { primary.row, primary.col }); // The primary’s location. 39 return T.Commit(); 40 } 41 bool Commit() { 42 Write primary = writes_[0]; 43 vector<Write> secondaries(writes_.begin()+1, writes_.end()); 44 if (!Prewrite(primary, primary)) return false; 45 for (Write w : secondaries) 46 if (!Prewrite(w, primary)) return false; 47 48 int commit_ts = oracle .GetTimestamp(); 49 50 // Commit primary first. 51 Write p = primary; 52 bigtable::Txn T = bigtable::StartRowTransaction(p.row); 53 if (!T.Read(p.row, p.col+"lock", [start_ts_, start_ts_])) 54 return false; // aborted while working 55 T.Write(p.row, p.col+"write", commit_ts, 56 start_ts_); // Pointer to data written at start_ts_. 57 T.Erase(p.row, p.col+"lock", commit_ts); 58 if (!T.Commit()) return false; // commit point 59 60 // Second phase: write out write records for secondary cells. 61 for (Write w : secondaries) { 62 bigtable::Write(w.row, w.col+"write", commit_ts, start_ts_); 63 bigtable::Erase(w.row, w.col+"lock", commit_ts); 64 } 65 return true; 66 } 67 } // class Transaction |
Percolator的事务提供的公开接口是Get/Set/Commit。
事务开始时,会从全局时间戳服务器拿取一个时间戳(L6),这个时间戳start_ts_ 就是该事务的快照点。事务读取数据时,能够读取到该时间戳之前提交的事务的数据。
Set接口很简单,将要写的数据缓存在Transaction这个类的成员writes_中,并不实际写盘。
Commit接口用于提交事务。提交过程是按2PC协议走的。
第一个阶段,所有的参与者prewrite(L27)然后抢占commit point。各个参与者prewrite时先尝试加锁。加锁过程中会检测冲突。第一个冲突是在本事务的快照点之后有事务提交了,那么,本事务不能提交(L32)。避免该冲突是快照隔离级别锁要求的,也即first-commit-win原则,先提交的事务能够提交,后提交的事务提交失败,只能回滚。第二个冲突是说,如果本事务看到Cell上有任意时间段内的锁,本事务prewrite也失败。这个是因为可能前面某个事务已经提交了,但是没有来得及释放锁(这种按说不会出现,论文也说we consider this unlikely, so we abort),我们也视为本事务prewrite失败。如果都没有冲突,本事务的该参与者就写入data和lock(36~48),表示加锁成功。注意,上述检测和写入data / lock都是在Bigtable支持的单行事务下做的。另外一个需要注意的是,Prewrite函数实际有两个参数Pwrite(Write w, Write primary),其中第一个参数w是当前参与者,primary我们后面会描述其作用。pwrite成功,意味着更新了数据并加了锁。
当执行到L47时,说明所有的参与者都prewrite成功了,也即2PC协议中所有参与者都prepare成功。通常的2PC协议实现中,如果所有参与者都prepare成功(例如相关log持久化成功),那么意味着事务一定会提交。但在Percolator中却不一定。这也是为何Percolator这段代码说L60开始第二阶段,论文原文中说L48开始第二阶段。Percolator的两阶段中prepare之后事务未必提交,可能会被其他事务清理导致回滚。真正标志本事务能够提交的,是L50的commit point。
在解释这个commit point之前,首先看看读数据是怎么读的。
读数据的接口是Get(Row row, Column c, string* value)。当调用Get读取该Cell的值时(L8),我们希望读取到该事务所拿到的快照点之前的数据。首先先去看这个Cell上有没有被加锁(L12),如果有锁,要等待该锁或者清理该锁(L9~L16)。清理锁跟commit point有关,后详。如果没有其他事务对该Cell加锁,那么,很好,我们可以去读数据了。读数据是个间接的过程,首先去读取write列的内容,根据write列的内容去找data数据。Write的存在原因是,data中没有标记标明该数据是否已经提交,因此使用write标明已提交的数据。
现在我们来解释这个commit point,这个比较复杂。
Percolator的节点作为Bigtable的client,可能发生client failure。我们要处理这种情况。假如client failure发生在Commit过程,那么,可能导致prewrite写下的锁被遗留在Bigtable中,进而后续事务读取时会死等在这个锁上。所以因为client failure导致的遗留锁必须要被清理掉。Percolator采用的是lazy方式清理。如果事务A发现跟事务B有锁冲突,那么,A可能要确定B已经发生client failure,那么A就要负责清理B遗留的锁。然而,A其实不太容易确定B的锁是因为client failure导致的遗留的锁还是B正在正常提交时的锁。
解决问题的方法是使用一个标记flag明确区分这两种情况。因为B提交时会担心自己锁是不是被A清理了,换言之,B能不能提交,其实并不决定于是否所有的参与者都prewrite成功了,而是flag标记是否允许提交。这样的话,A在清理前,也应该明确地检查flag。如果flag表明B已经提交了,A就不能执行清理。考虑到检查和修改Flag应该保证原子性,我们选择Bigtable的一个cell作为flag,对flag的检查和更新放在Bigtable的单行事务下执行就行了。
现在存在的一个问题是,如何确定flag保存在哪里?注意,我们的需求是B中任何参与者的锁被A清理时,都应该能顺藤摸瓜找到flag。因此,我们选出一个primary的参与者(这个随意选),在每一个参与者的持久化的锁中都记录该参与者的锁位置。该锁就是flag。于是当A打算清理锁,B打算提交,都会先去修改这个primary的lock(Erase这个lock),也就是L51~58代码。如果B成功修改了primary lock,那么标记着A无法清理该锁,事务最终会被提交,否则A抢到了primary lock锁,A会清理掉该事务。对primary lock的检查和修改都是在Bigtable单行事务下做的(L52),该事务是否成功提交标志了事务最终的commit/rollback状态,这就是为何L58被称为commit point。
一旦抢到了commit point,事务就可以逐个让参与者提交了。事实上,L55~L57就是第一个参与者的提交。
提交时先写write记录,再删除lock记录。write记录的作用是记录提交时间戳commit_ts,同时指示data的时间戳start_ts。一旦write写下lock删除,其他事务就可以读取到data内容(参见Get函数实现)。
我们看下关于清理锁的优化问题。
根据上面的分析,清理锁的操作是安全的,即使被清理的是一个活跃的事务。但是带来的问题是本来可以提交的事务被迫回滚了。为了减少误伤的情况,Percolator做了些优化,清理者只有判断事务死了或者卡住了(dead or stuck)才清理。如何才能让事务A判断事务B的状态?Percolator中事务执行时,会在Chubby中注册一个token,token在说明事务没死。为了解决事务没死但是卡住了(执行不下去)的情况,事务提交过程中要不断地更新token的时间戳(类似于watch dog喂狗)。如果事务卡住了,它的token的时间戳就会很旧,后续事务发现这个问题,就会执行清理。
通知机制
这节是讲Percolator的使用方式,即如何组织计算。
用户要做的是给感兴趣的列注册监听,当这些列发生变化时,就会执行用户预先定义好的代码(叫observer)。用户将所有的observer代码打包到一个Binary中。Observer之间可能串成了链,observer1在column1发生变化时被通知调用,observer1执行过程中会更新column2,此时column2上的监听到变化,并通知调用observer2,类推。
Percolator保证如果一列发生变化,最多只有一个因此而发生的事务能够提交(可能会出发多个事务,跟通知机制有关)。
下面解释下具体实现Notification的方法。
为了实现通知机制,每个被监听的列都会配置一个伴随的列acknowledgement列,里面记录了一个时间戳,用以表示这之前的变化都已经被通知了(observer启动时将自己的启动时间戳更新上去)。所以当一个observer尝试去更新时,会先看有没有别的线程已经启动事务了。这里还有并发问题,即两个线程同时启动各自的事务,此时两个事务会在更新ack列时发生冲突,最终只有一个能提交。
为了实现高效的监听机制,需要一个高效的扫描方法。数据可能有几十亿行,但是实际被修改的行可能只有几百万,所以将这些被修改改的脏行的key单独存放到notify表。扫描时,只扫描这个表就可以了。
具体扫描方法:一组扫描线程随机选择一个位置开始扫描。如果某个线程1卡住了,另外一个线程2追上了它,线程2就重新选一个位置再扫。
这里一直没搞清楚为什么Percolator选择随机的位置开始扫,而不是每个线程扫描一个固定的key range。随机找位置开始扫描,并不能确保每个key都能被扫描到,例如如果扫描使用均匀分布的随机数发生器,那么最小的key应该就很难被扫描到。
后来邮件问了下作者,作者的意思是there is no guarantee, but it worked well enough for us。Percolator之前尝试过确定性的方法,也会遇到straggler的问题。
我猜想可能是有特殊的线程为概率上不容易扫到的key做补偿,或者概率发生器就是修改后的。因为Percolator并不是为低延迟而设计的,短时间内通知不到并没有什么问题。