EPaxos协议解读
本篇博文主要描述了EPaxos command commit的过程,并且解释了为什么fast quorum的值如此奇怪。
相比Multi Paxos和Raft,EPaxos有着自己的优势,但是缺点也非常明显,EPaxos协议非常复杂,接口行为也不见得适应现在的软件栈,比如commit和execution的阶段划分更加的明确,execution逻辑很复杂,读取操作也很复杂。我个人认为EPaxos协议的一些想法还是比较有意思的,但是不太适合生产场合使用,毕竟能实现一个高效正确的Multi Paxos协议已属不易,而且EPaxos协议虽然吞吐量能有比较大的提高,但是容易发现协议中各种操作真正在实现时,会出现大量非常耗费CPU的代码,整体性能能提高到多少,我想并不太乐观。
引言
这是2013年SOSP的会议论文,讲述了一个leaderless的一致性协议EPaxos。不得不说的是,这篇论文写的实在是难读,一方面协议确实比Multi Paxos协议复杂很多,另一方面是行文上有些地方不通顺。我看的资料是会议论文和两个版本的EPaxos证明的技术报告。会议论文简洁但是缺乏最核心的Fast Quorum的优化证明。两个技术报告证明过程却又比较难读:比如某个版本的技术报告里面提到了phase2,但是全文没有解释phase2是那个阶段,另外一个版本的证明里面才看到phase2。再比如,有些地方引入新的记号但缺乏数学化的定义。再比如,有些执行逻辑本身就是相互依存的,很难一次看明白。本文尝试综合三篇资料,直接描述优化后的EPaxos协议,因此本文的内容可能跟会议论文有些差异,读者如果发现错误,敬请指正。
需要注意的是,要读EPaxos协议需要先解锁Basic Paxos和Multi Paxos这两个关卡,了解复制状态机RSM的概念和Basic Paxos、Multi-Paxos协议的相关内容。
为了方便读者,我们这里也简单说下Multi Paxos协议用于日志复制(paxos原始论文里面有一些介绍,读者可以参考原始论文)。Multi Paxos中,proposer一次对所有的paxos instance做prepare过程,prepare成功后,这些paxos instance共享一个proposer id,这些instance只需要做accept阶段即可,如果leader比较稳定,一个paxos instance(一条日志)就只需要一个网络来回。工程实践方面的内容还可以参考白哥的博文 使用Multi-Paxos协议的日志同步与恢复。
Mutli Paxos协议虽然高效,但是也有一些问题:
- leader上负载比较高,影响了scalability
- client跨地访问远端leader,延迟变大
- 传统Paxos变体对负载尖刺和leader的网络延迟比较敏感
- 单leader宕机会影响availability。
注:分区可以降低leader负载和leader宕机对可用性的影响,但是往往可能引入不必要的分布式事务。
OSDI之前还有一篇Mencius(孟子的英文单词)的论文也在尝试解决这个问题。在Mencius中instance space被预先划分好,replica Rid负责(i mod N) = Rid的那些instance i。这种方式需要每个副本都要获知其他副本的提交情况,否则可能导致linearizability问题。
EPaxos初步了解
EPaxos提供了另外一种没有leader的paxos变体(leaderless paxos)。EPaxos允许所有的副本都同时可以作为proposer (command leader),client可以向任何一个副本提交command。
熟悉Multi Paxos协议的读者很快就可以意识到,这种设计首先要理清楚的就是状态机和command的对应关系问题,以及command order问题。
在Multi Paxos中,command id可以是一个连续递增的整数,不管是不是发生切主(例如主宕机后选出新主),command id都可以想办法做到保持连续递增。从概念上说,状态机与连续的一片command是对应的(Raft协议里面说的commit id和apply id)。但是在EPaxos中,并不容易维护一个单调递增的整数作为command id(除非像Mencius一样),所以,EPaxos将command id定义为R.id,两维的变量,其中R是副本唯一id,id是R内连续递增的正整数。于是,EPaxos的完整状态机是包括所有N个副本的instance的。
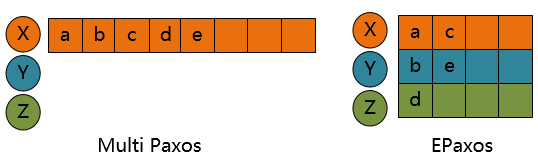
对于command order,Multi Paxos是由leader来定序的(这里不考虑并发控制部分引入的序),EPaxos中对于不冲突的命令(例如修改的是不同的对象),其顺序不是预先确定的。
另外一个需要仔细区别的问题是,Multi Paxos协议下,多条command共享一个proposal id(即Paxos原始论文里面提到的ballot number),而在这一点上,EPaxos的每条command的实例都是独立的,不共享ballot number,每个instance都有自己的ballot number(毕竟是leaderless)。接收这条command的副本L给这条command对应的instance分配一个initial ballot number: epoch.0.L。
EPaxos的性质
首先,我们要定义什么是command冲突。
Definition 1 (Interference). Two commands γ and δ interfere if there exists a sequence of commands Σ such that the serial execution Σ,γ,δ is not compatible (i.e., it produces different results than) the serial execution Σ,δ,γ。
举个例子,γ是将x改为1,δ是将x改为2。那么先执行哪一个command的结果是不同的,γ与δ是冲突的。
EPaxos协议保证了如下的性质:
- Nontriviality: 被commit的command一定是某个client提出来的(no-op除外)。
- Stability: 已经commit的command以后后不能变成未commit状态。如果在时刻t1时刻,副本R上已经在instance Q.i commit了command γ,那么在t2>t1时刻,R上Q.i γ都是commit过的。
- Consistency: 对于某个instance,任何两个不副本不能commit不同的command。
- Execution consistency: 两个冲突的命令γ,δ成功commit之后,在所有副本上,二者的执行顺序都是一样的。
- Execution linearizability: 两个冲突的命令γ,δ被client串行执行,则在所有副本上,二者执行的顺序与client串行顺序是相同的。
- Liveness:只要多数派还在线,并且消息能够在超时前送达,那么command最终会被确认。
虽然一下子罗列了6个性质,但是在实际的分布式系统中,这些性质其实还是比较弱的约束了,看过协议再回头 看,这其中多个性质还是比较容易有直观的理解。其中liveness要求网络相比比较可靠,否则根据FLP,保证safety和liveness的容错一致性协议是不存在的。
执行过程的直观解释
在正式介绍协议之前,我们先从直观上简单地了解一下EPaxos的执行过程。
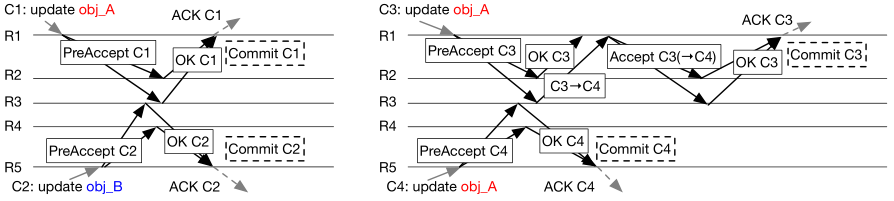
如图示,如果并发的两个客户端发起不冲突的的命令,则每个命令经过PreAccept之后即可commit。如果命令冲突,则有副本检测到冲突,并给冲突的command定序(发送给其他副本的请求带有额外的属性),之后再commit。
读者可能发现了,关键仍然是command定序。比较容易想到的定序方式是PreAccept发送给多数派,多数派交集的副本(图中为R3)可以检测到C3实际应该在C4之后,并将该信息反馈给R1,R1再处理这个定序结果。
那么PreAccept发送给多数派就够quorum了么?并非如此,我们看一个例子。

如图示,7个副本,大于等于4即为多数派。假设副本1提出command A,副本2提出B,并且并发发送给3、4、5、6、7五个副本。假设4、5先收到A后收到B,6、7相反。如果3先A后B,那么A就收到1、3、4、5四个副本的相应,A就可以commit并响应客户端了。相反,如果3先B后A,则B就可以commit了。不管3是哪种情况,假设此时集群宕机且1、2、3无法恢复,则剩余多数派4、5、6、7在线但是却无法区分到底是A commit还是B commit了。
带着这几个性质和如何定序、如何恢复的问题,我们来看协议的描述。EPaxos论文中描述了基本EPaxos和优化EPaxos两个,后者是在前者基础上做了优化,将fast quorum从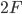 降低到了
降低到了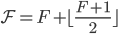 。基本EPaxos只能容忍一个节点失效,所以也无法用到实际,优化EPaxos中,fast path在N=3,5时,消息数目是最优的。我们直接看优化EPaxos。
。基本EPaxos只能容忍一个节点失效,所以也无法用到实际,优化EPaxos中,fast path在N=3,5时,消息数目是最优的。我们直接看优化EPaxos。
EPaxos用到的几个概念
在描述前,先描述几个概念。
在EPaxos中,每一个command γ都附带attribute,其中包括deps和seq。deps记录了跟γ冲突的command的instance id,γ依赖这些instance id对应的command。deps中维护的依赖关系就是定序用的关系,γ要排在deps中 的command后面。seq是一个序列号,用来在execution阶段打破循环依赖。
接收client请求的副本称之为这个command 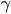 的command leader,记作
的command leader,记作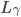 。每个副本都会持久化记录到cmds中,通过
。每个副本都会持久化记录到cmds中,通过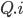 这种instance id来索引并读写。
这种instance id来索引并读写。
协议分成两个部分,首先是正常处理客户端请求的处理过程,这个过程包括三个阶段:(1) Phase1 Establish ordering constraints (2) Paxos-Accept Phase (3) Commit Phase。其中一个命令可能走Phase1 + Paxos-Accept Phase + Commit Phase,或者Phase 1 + Commit Phase,前者称之为slow path,后者称之为fast path。
需要提前指明的是,优化EPaxos采用的是thrifty模式,fast quorum是 ,其中F为系统容忍的少数派,command leader向 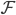 个副本发送pre-accept请求,而不是向 2F+1 个副本发送请求等待 个回应。
个副本发送pre-accept请求,而不是向 2F+1 个副本发送请求等待 个回应。
协议详细介绍
接收命令并尝试commit的过程
(注意协议描述中每个请求都应该带着proposal id,这里为了描述简单忽略了):
Phase 1: Establish ordering constraints
- 副本L收到客户端的请求γ(2,3,4原子执行):
- 递增L的instance id
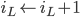
![seq_\gamma \leftarrow 1 + max(\{cmds_L[Q][j].seq | Q.j \in Interf_{L,\gamma}\} \cup \{0\})](http://loopjump.com/wp-content/plugins/latex/cache/tex_928be495703b257866797b0d3f1a3a47.gif) ,其中
,其中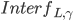 是cmds(持久化的记录集合)中记录的跟γ有冲突的instance的集合。
是cmds(持久化的记录集合)中记录的跟γ有冲突的instance的集合。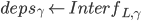
![cmds_L[L][i_L] \leftarrow (\gamma, seq_\gamma, deps_\gamma, pre\text{-}accepted)](http://loopjump.com/wp-content/plugins/latex/cache/tex_cdecd3403a950966d17fad9ce5de2b45.gif)
- 发送
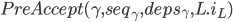 给所有中的节点(L自己除外)。
给所有中的节点(L自己除外)。
- 副本R收到(6,7,8原子执行):
![seq_\gamma \leftarrow max(\{seq_\gamma\} \cup \{1+cmds_r[Q][j].seq|Q.j \in Interf_{R,\gamma}\})](http://loopjump.com/wp-content/plugins/latex/cache/tex_f0b21d72a4c8061577d50b7711b3a716.gif)
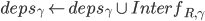
![cmds_R[L][i] \leftarrow (\gamma, seq_\gamma, deps_\gamma, pre\text{-}accepted)](http://loopjump.com/wp-content/plugins/latex/cache/tex_9bb42f21a2e4a84ac4633154eef16b27.gif)
- 向L回复
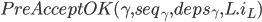
- 副本L收到至少F个副本回应的PreAcceptOK响应之后:
- 如果从
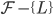 收到的
收到的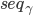 和
和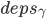 没有变化,并且FP-deps-committed条件满足,那么在
没有变化,并且FP-deps-committed条件满足,那么在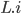 上对
上对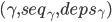 执行Commit Phase
执行Commit Phase - 否则
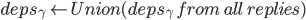

在上对执行Paxos-Accept
其中,FP-deps-committed:当前command得deps中所有command都在某些回应中被标记为Committed了。
Phase 2: Paxos-Accept
- Command Leader L对于instance id为的:
![cmds_L[L][i] \leftarrow (\gamma, seq_\gamma, deps_\gamma, accepted)](http://loopjump.com/wp-content/plugins/latex/cache/tex_05e6568a98a70de06de054a5ed283bea.gif)
- 将
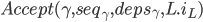 发送给至少
发送给至少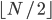 个其他副本
个其他副本
- 副本R收到
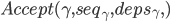 之后,
之后,
![cmds_R[L][i] \leftarrow (\gamma, seq_\gamma, deps_\gamma, accepted)](http://loopjump.com/wp-content/plugins/latex/cache/tex_9802784b91bfe0a437a7d9c1911fd478.gif)
- 向L回应
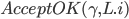
- Command Leader L在收到至少个AcceptOK之后:
- 在上执行Commit Phase
Commit Phase
- Command Leader L对于instance id为的:
![cmds_L[L][i] \leftarrow (\gamma, seq_\gamma, deps_\gamma, committed)](http://loopjump.com/wp-content/plugins/latex/cache/tex_c74059aa92c807575019eb0408e92ceb.gif)
- 向client回应 已经commit成功了
- 向所有其他副本发送
 消息
消息
- 副本R收到消息:
![cmds_R[L][i] \leftarrow (\gamma, seq_\gamma, deps_\gamma, committed)](http://loopjump.com/wp-content/plugins/latex/cache/tex_cb5ff62070621cd469e58d98eb4200d7.gif)
恢复阶段Explicit Prepare
- 副本Q怀疑L失效,尝试去恢复L.i这个instance。
- 递增ballot number:设Q知道的最大proposal id是
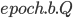 ,则使用新的proposal id
,则使用新的proposal id 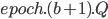
- 向所有副本(包括自己)发送
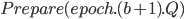 ,等待至少多数派的回应。
,等待至少多数派的回应。 - 假设所有回应中最大ballot number的是
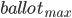 ,定义
,定义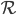 是所有回应中ballot number等于的响应的集合。
是所有回应中ballot number等于的响应的集合。 - 如果没有关于这个instance id的任何信息,那么推出恢复阶段,副本Q对L.i实例尝试去commit no-op。
- 如果中包含了至少一条
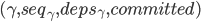 ,则对L.i实例执行Commit Phase。
,则对L.i实例执行Commit Phase。 - 如果中包含了至少一条
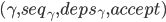 ,则对L.i实例执行Paxos-Accept Phase。
,则对L.i实例执行Paxos-Accept Phase。 - 如果至少
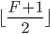 个副本回应了pre-accept,并且它们回应的
个副本回应了pre-accept,并且它们回应的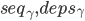 都与L.i的epoch.0.b那轮PreAccept请求中记录相同,那么就进入TryPreAccept阶段,否则就回到slow path重新来一遍commit。
都与L.i的epoch.0.b那轮PreAccept请求中记录相同,那么就进入TryPreAccept阶段,否则就回到slow path重新来一遍commit。
TryPreAccept阶段
副本Q发送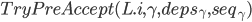 给中未回应过pre-accept response的副本。
给中未回应过pre-accept response的副本。
- 副本R收到之后,如果R现在记录了command
 ,同时满足如下三个条件:
,同时满足如下三个条件:

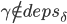
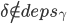 或者
或者 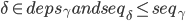
就回应NACK,并带上冲突command的一些信息(包括的instance id、command leader、instance的状态如pre-accepted/accepted/committed),否则就回应ACK。
- 副本Q在收到TryPreAccept的响应之后,顺序进行如下的条件判断:
- 如果pre-accepted的副本数目已经大于等于F+1,则Q退出恢复过程,开始对L.i实例
 执行Paxos-Accept阶段。
执行Paxos-Accept阶段。 - 如果某个TryPreAccept NACK中反馈了存在一个已经committed的冲突command,则退出恢复阶段,从头开始slow path来在L.i实例上重新尝试提交。
- 如果某个TryPreAccept NACK中反馈了一个实例,其中并且
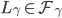 ,则退出恢复阶段,从头开始slow path来在L.i实例上重新尝试提交。
,则退出恢复阶段,从头开始slow path来在L.i实例上重新尝试提交。 - 如果存在command
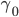 ,Q是先尝试恢复,但因为发现可能需要先恢复跟冲突的。在这种情况下,如果发现的command leader是的fast quorum中的一个,那么就退出的恢复,从头开始slow path来重新提交。
,Q是先尝试恢复,但因为发现可能需要先恢复跟冲突的。在这种情况下,如果发现的command leader是的fast quorum中的一个,那么就退出的恢复,从头开始slow path来重新提交。 - 如果前面的条件都不满足,Q就推迟defer 的恢复,先恢复与冲突的某个command。
协议的部分解释和证明
这个过程比较复杂,要先梳理清楚核心思想。EPaxos首先尝试将一条command通过Fast Path提交,Fast Path提交时,command leader将已知的依赖属性(用于确定order)连同command自身多播到Fast Quorum,如果Fast Quorum中没有副本反对这个order,那就commit成功。如果达不到Fast Quorum,而只是简单的多数派,那就走Paxos的两阶段。
根据协议的内容,我们能够琢磨出这样一个结论:在某个副本R上,针对某个instance L.i,其状态可能是pre-accepted、accepted、committed。这三个状态代表了不同程度的确定性。
- pre-accepted状态:表示R已经持久化了L当时发现的顺序关系,此时R仅根据自身无法得知更多的信息。
- accepted状态:表示R已经持久化了至少多数派认可的依赖关系。
- committed状态:表示R已经知道L.i已经commit了,尘埃落定,甚至可能已经应答了客户端。
由此,再看恢复阶段的逻辑,就会简单一些。
Explicit Prepare中发起prepare请求和收集多数派响应,以及查看最大ballot number的响应集合(Basic Paxos中提到的MaxVote)都是跟Basic Paxos协议一致的,这里不再解释。
Explicit Prepare中24行(多数派没见过该command)、25行(确定已经commit了)、26行(依赖关系已经不会被推翻了)也比较容易理解。
我们重点描述27行的条件“如果至少个副本回应了pre-accept,并且它们回应的都与L.i的epoch.0.b那轮PreAccept请求中记录相同”的操作。相比前面24行、25行、26行的条件,这种情况的结果是不确定的。有可能只多播了个副本,也可能已经达到了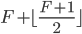 ,所以要经过TryPreAccept阶段。
,所以要经过TryPreAccept阶段。
在TryPreAccept阶段,我们要坚持一个原则:除非已经确定没有commit,否则就要假设已经commit,在恢复阶段就要尽力把 commit掉。后面的优化和证明都是这个原则引申出来的。
接下来我们逐个看TryPreAccept阶段各个场景。
第28行如果pre-accepted的副本数目已经大于等于F+1,表示至少多数派已经认可了这一顺序关系,此时直接走Paxos-Accept即可。
第29行如果某个TryPreAccept NACK中反馈了存在一个已经committed的冲突command,那么根据FP-deps-committed条件,确定是未commit的。此时从头开始走slow path。
第30行如果某个TryPreAccept NACK中反馈了一个实例,其中并且,因为协议使用的是thrifty模式,因此可以确定没有commit,则从头开始slow path。
第31行如果存在command ,Q之前先是尝试恢复,但因为发现可能需要先恢复跟冲突的。在这种情况下,如果发现的command leader是的fast quorum中的一个,同样是因为thrifty模式,一定是没有commit的,所以可以从头开始slow path。
只剩下最后一种情况,第32行,如果前面的条件都不满足,Q就推迟的恢复,先恢复与冲突的某个command。
从上面的描述,我们可以看到,当我们尽可能根据已有的信息判定出来可以走Paxos-Accept或者确认未commit直接从头开始slow path。除此之外,我们仍然有可能无法推断出确定的信息,此时的恢复就被defer了。 那么问题来了,有没有可能我们一直在推迟某几个instance?答案是不会的。
接下来我们就要一步步理解为什么EPaxos的fast quorum是一个如此奇怪的值。
试想,如果我们让足够大,比如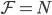 ,那么我们很容易推断出一个command是不是通过fast path来commit了:恢复阶段只要有一个副本反馈说没有记录过pre-accept就足够确定是没有通过fast path来commit了。如果太小也不行,我们已经看过了,N=7的情况下,至少得超过多数派。
,那么我们很容易推断出一个command是不是通过fast path来commit了:恢复阶段只要有一个副本反馈说没有记录过pre-accept就足够确定是没有通过fast path来commit了。如果太小也不行,我们已经看过了,N=7的情况下,至少得超过多数派。
那么,为什么是合适的呢?我们接下来证明一下为什么这个值就可以避免TryPreAccept过程处于一直推迟的状态。需要注意的是,虽然我们是拿着这个值去证明不会推迟,但是证明在该值下不会推迟可以简单地转化为证明在不会推迟的前提下求这个值至少是多少。
我们只证明一个简单的情况:不存在和两个command的恢复过程互相等待对方。更大的循环等待证明过程我也没看,读者感兴趣可以参考证明的技术报告。我们用反证法,假设二者互相defer。
首先定义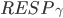 是的fast quorum(记作
是的fast quorum(记作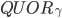 )中回应了TryPreAccept的副本的集合。类似地定义
)中回应了TryPreAccept的副本的集合。类似地定义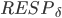 。
。
R在恢复和时,可以得出如下的几个结论:
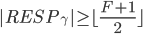
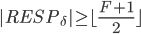
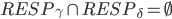
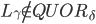
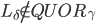
前两个是因为无法确定是不是经过fast path才会推迟恢复,如果这两个条件不满足,容易推断出少于的节点记录了pre-accept。第3个结论是因为不可能有副本记录了两个冲突的pre-accepted command,这个副本一定更新了冲突中的某一个deps。同样的原因可以推出第4和第5个结论(注意协议是thrifty模式)。
接下来还有一个重要的结论。因为Explicit Prepare至少收到了多数派的响应之后才会做判断,所以最多还有F个副本没有回应。因为副本R在推迟转而尝试确定,所以一定在F个未回应的副本中,否则回应了R,那么R就得知了的状态,因为只有才会通过fast path来commit 。又因为,所以 。
。
注意因为假设了和的过程互相defer,所以结论中和互换仍是成立的。接下来,我们注意到一个事实:和和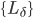 三个集合是disjoint的,然而三者的基数加起来至少是
三个集合是disjoint的,然而三者的基数加起来至少是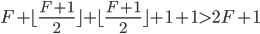 。这是不可能的,因此互相defer而推进不了的假设是错误的。
。这是不可能的,因此互相defer而推进不了的假设是错误的。
Execution & Read
这部分内容简单了解了下,没有仔细看。
执行算法
对于R.i的instance command ,其execution算法如下:
- 等待i instance变为committed
- 构建dependency graph:command作为节点、依赖作为有向边,从开始,反复处理所以来的command,以及所依赖的command所依赖的command…
- 求出图的强连通分支
- 对强连通分支的反向拓扑顺序依次执行如下操作:
4.1 一个连通分支内的节点按照seq大小排序
4.2 按从小到大的顺序执行每一个尚未被执行的command
如果带着command order的问题看协议,直观上这个协议是容易理解的。这里之所以可能有连通分支,是因为并发commit的两个command在不同的节点上建立了不同的依赖关系。
Execution的性质的证明没有看,感兴趣的读者可以参考原始证明文章。
读取过程
要读取一个对象,客户端发起Read(obj_id)然后等待ReadReply。可以将读取操作视为跟更新obj_id冲突的no-op command。论文还讲了Read Lease相关的内容,另外还有一篇论文,不过我也没读过。
一点总结
本篇博文主要描述了EPaxos command commit的过程,并且解释了为什么fast quorum的值如此奇怪。EPaxos允许多点提交command,总是先尝试通过一阶段直接commit,并通过约束quorum等方式确保一阶段执行失败后的恢复。
相比Multi Paxos和Raft,EPaxos有着自己的优势,但是缺点也非常明显,EPaxos协议非常复杂,不合适冲突多 的场景,接口行为也不见得适应现在的软件栈,比如commit和execution的阶段划分更加的明确,commit成功和执行成功对客户端是两个不同的回应(应该也可以在系统内部等待成一个),commit顺序和execution顺序也可能不一样,execution逻辑很复杂,读取操作也很复杂。此外冲突的命令在replication层面解决,可能会影响上层并发控制逻辑,很可能会引入一些耦合。
我个人认为EPaxos协议的一些想法还是比较有意思的,但是不太适合生产场合使用,毕竟能实现一个高效正确的Multi Paxos协议已属不易,而且EPaxos协议虽然吞吐量能有比较大的提高,但是容易发现协议中各种操作真正在实现时,会出现大量非常耗费CPU的代码(比如cmds这个数据的存取),整体性能能提高到多少,我想并不太乐观。而Multi Paxos或者Raft的一些缺陷在现有业务系统或者中间件的设计中也并不突出。
请教博主,能细说以下这三个条件吗?我不太明白这三个条件的含义和意义
γ~δ
γ∉depsδ
δ∉depsγ 或者 δ∈depsγandseqδ≤seqγ
是指TryPreAccept阶段的这三个条件吗?
这三个条件是指:R发现了γ和δ冲突这一事实,但Q在尝试恢复γ的时候并不知道,所以R收到Q的TryPreAccept时,将这一冲突告知Q。
第一条表示γ和δ冲突。
第二条表示δ被propse时并不知道有γ。
第三条表示γ被propse时并不知道有δ,或者知道但认为依赖关系未被多数派确认。
文中seqδ≤seqγ应该是写反了,应该是 seqγ ≤ seqδ
seqδ≤seqγ 这个条件确实奇怪,与δ∈depsγ会互斥。但是我看到论文中也是这样写的,在网络上却找不到关于这一错误的观点。
另外还要一个疑问,这三个条件是and关系,副本R需要同时满足了这三个条件,但是明显,这三个条件也是互斥的。
条件二、三,博主说的是发送时的情况,因为R收到消息时会更新deps,因此γ∉depsδ和δ∉depsγ的情况,R收到时的状态包含了Q发送时的状态,那么得出:
条件二,说明R收到δ时,未收到γ。条件三(仅先讨论第一个条件),说明R收到γ时,未收到δ。这两个条件同时满足时,说明R不会同时记录γ和δ。但是需要满足条件一,却只有在R同时拥有γ和δ时才能知道γ和δ是否干扰啊。
我不清楚我理解是否正确,还得麻烦博主再帮忙指点一下。
seq这个问题不是太清楚,需要再分析下。除了seq问题外,其他三个条件是合理的吧。
注意到这里是Q正在recover γ,当时的情况可能是γ是在节点A上propose的,δ是在节点R上propose的,两个命令可能是几乎同时开始propose。
第一个条件是指command本身是冲突的,比如两个请求都是执行某业务的库存减一操作,这个是propose前就客观存在的冲突。
第二和第三个是指EPaxos内部的若干节点各自是否发现该冲突,并将其纳入自身依赖集合。
干扰的概念、γ和δ由两个副本同时propose,我能理解,我的疑问在于,这三个条件是针对R本地数据而设立的。
我们假设γ和δ都是更新objA,从上帝视角我们知道γ和δ是干扰的。但是R一定是先后收到了γ和δ,才能知道这二者是否干扰。另外,同时满足γ∉depsδ和δ∉depsγ,这不是意味着γ和δ不干扰嘛,因为干扰的话,一定满足γ∈depsδ or δ∈depsγ。
“但是R一定是先后收到了γ和δ,才能知道这二者是否干扰”
这里是Q正在recover γ,R本地已经持久化了δ,然后收到Q广播的TryPreAccept(γ),这时R发现收到γ与本地已持久化的δ有冲突。
“另外,同时满足γ∉depsδ和δ∉depsγ,这不是意味着γ和δ不干扰嘛,因为干扰的话,一定满足γ∈depsδ or δ∈depsγ。”
deps最初是command leader根据自己本地信息构建的。
恢复阶段Explicit Prepare,中 22 . ,
> 向所有副本(包括自己)发送Prepare(epoch.(b+1).Q),等待至少多数派的回应。
在技术报告中,16 页,6.2 , 表示为:
> Each replica replies with the information recorded for Q.i, if any. R waits for at least F + 1 replies (including itself).
等待至少 F + 1 的 replies
这里F+1应该就是至少多数派。
总的副本数目是2F+1。
请教博主,thrifty模式是什么意思?
这里是我博客里面没有说清楚。
在 A Proof of Correctness for Egalitarian Paxos (August 2013) Section 6.1里面有描述,你可以参考下。
Instead of sending PreAccept messages to every replica, a command leader sends PreAccepts to only
those replicas in a fast-path quorum that includes itself. We call this mode of operation thrifty. The fastpath
quorum can be static per command leader, or it can change for every new command—depending on
inter-replica communication latency and dynamic load assessment.
谢谢博主,
还有问题请教,
为什么 QUORγ和RESPδ 是不相交的呢,我也看了原论文,但还是不是很明白。
QUORγ RESPδ Lδ 三者 两两不相交,才有下面的>2F+1的推论。
请指点迷津
首先,这里是我写的有问题。
这里的QUORγ(proof文章里面记成QUORγ上加横线符号)应该是指 QUORγ 再加上 { 没有响应副本R recovery δ的那些副本(最多F-1个) } 这两个集合的并集。因为已经确定QUORγ肯定超过F+1,所以可以假设这F-1个都恰好在QUORγ里面,对于计算quorum大小下限应该没有影响。
.
.
然后,如果 QUORγ和RESPδ 相交,则R可以知道γ当时并没有通过fast path完成commit。
这里互相defer的原因是R既不确定γ当时有没有通过fast path完成commit,也不确定δ当时有没有通过fast path完成commit。
如果可以确定其中一个没有通过fast path完成commit,则这个command的恢复就通过slow path重新走两阶段完成commit。
A Proof of Correctness for Egalitarian Paxos 貌似有两个版本,你可以先参考更新的那篇。
谢谢,对于原paper理解的很深刻,能读到中文版的,收益良多。
握手
正在读paper,希望能从您的博客中获得启发