SDPaxos 优雅的折中
SDPaxos在Strong Leader和Leaderless中间做了一个优雅的折中,使得协议远比EPaxos清晰,但又支持了损失很小的多点并发复制。
// 大半夜on-call没事干,写点东西。
《SDPaxos: Building Efficient Semi-Decentralized Geo-replicated State Machines》(SOCC18')
有幸跟作者赵汉宇博士做了一次交流,我也仔细读了一遍论文原文,读完最大的感受是,SDPaxos在Strong Leader和Leaderless中间做了一个优雅的折中,使得协议远比EPaxos清晰,但又支持了损失很小的多点并发复制。
SDPaxos in design spectrum
这里仅描述下SDPaxos的设计选择。协议的细节和大量的分析,有感兴趣的同学,可以直接看原始论文,论文写得很清晰(真是比EPaxos写得清晰太多了),读完应当很有收获。

从对Leader的依赖这个角度看,SDPaxos在Design Space/Spectrum中选择了中间的一个折中位置。
在图中:
左一Raft协议强依赖leader,例如在选举时必须选择在某个多数派中拥有最新日志的节点。
左二Multi-Paxos协议的liveness/progress依赖stable leader,但协议正确性不依赖。
跳过SDPaxos,右二Mencius让每个节点轮流propose command,例如三副本configuration下,replica 0 propose slot 1,4,7...3x+1...的command。
最右EPaxos最极端,任意节点propose command,冲突的command在replication过程中检测并确定顺序。
SDPaxos的折中是,command order仍由单点确定,但各副本都可以propose和replicate command。
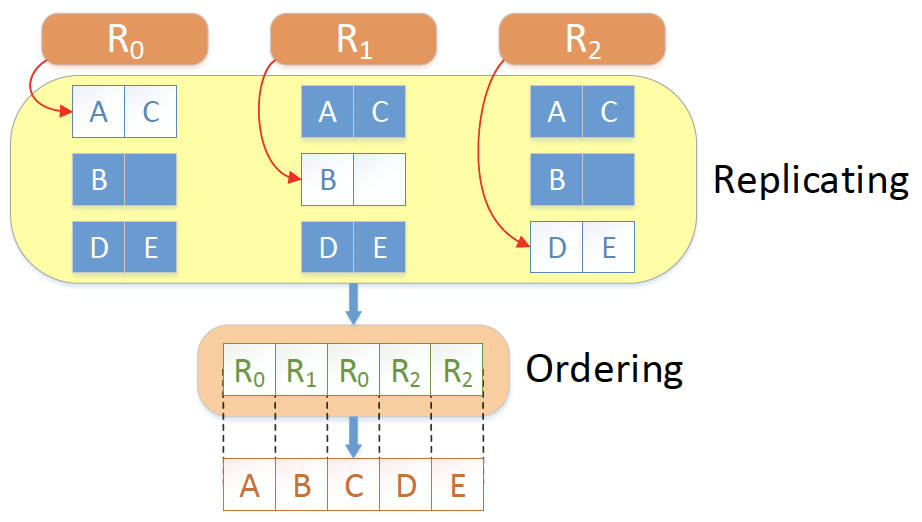
我们做个比喻:
Raft就像是苏联的社会主义计划经济,ordering/replicating都由中心节点来管理;
EPaxos就像资本主义市场经济,各个replica充分竞争,自行解决ordering问题;
SDPaxos就像是社会主义市场经济,ordering由单点的sequencer来确定,replicating由各个副本来做。
SDPaxos优点
SDPaxos相比EPaxos的优点,简单地说,SDPaxos相比EPaxos清晰太多,因此优势非常显著:
(1) 协议可理解性:SDPaxos清晰的多。这里举几个EPaxos中很不直观的地方:EPaxos fast quorum是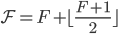 ;采用的是thrifty模式,只能向特定几个replica发送accept request;accept request要携带dependency信息。
;采用的是thrifty模式,只能向特定几个replica发送accept request;accept request要携带dependency信息。
(2) 协议CPU开销:SDPaxos CPU开销低,基本跟Raft/Multi-Paxos所需的开销接近。EPaxos有大量处理dependency的key检测,会消耗大量的CPU。
(3) 落地实现难度:同样是因为复杂性,EPaxos协议在工程上很难落地,就EPaxos的recovery逻辑,几乎很难实现一个生产环境可用的正确版本,但SDPaxos就容易的多。
(4) 正确性直觉:虽然EPaxos也经过了论证和TLA+证明,但考虑到TLA+证明过程本身的可靠性,要说EPaxos协议没有正确性bug,并不能容易结接受。相反,受益于SDPaxos协议的清晰,接受SDPaxos正确性在直觉上容易的多。
补充:Practical Fast Replication
NSDI 2019有篇论文 《Exploiting Commutativity For Practical Fast Replication》,介绍了另外一种放松order的思路。
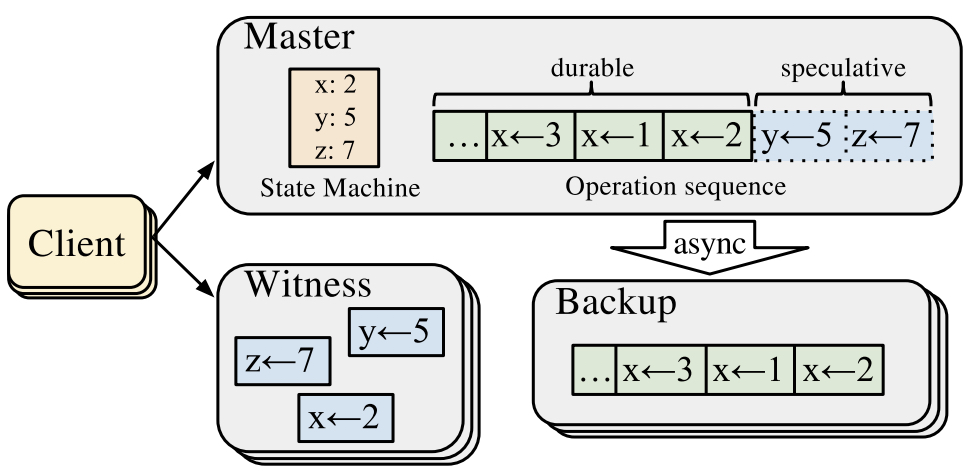
如图,client向master同步entry的时候,同时向一组witness同步,witness维护了最近一批entry的冲突信息(即论文中说的Commutativity性质)。如果witness说没有冲突,并且master本地同步成功,client即可认为entry已经被确认。否则,client通知master做一次sync,将master本地数据同步到backups上。
事实上,这个思路也放松了全局有序order这一约束。考虑master crash,由于master将entry异步同步到backups,所以backups上并没有全部的确认entry,但是backups + witness上有全部的entry,不过在witness上的那些entry本身的顺序是被relax过的,恢复过程中曾经有序的entry在恢复时等于是丢掉了(丢掉的序关系是满足Commutativity性质的,所以不会有正确性影响)。
简言之,就是顺序提交,乱序恢复(crash-recovery)。
如果要将Practical Fast Replication(PFR)放到Design Space/Spectrum中呢?
跟Raft/MultiPaxos这类strong leader方案相比,PFR实际上是将leader定序的能力拆到了master+witness两个角色上,但注意,拆分按阶段的。提交阶段仍是master负责定序。
简单对比下。
跟EPaxos相比,PFR只在master crash recovery的场景下才有真正的乱序,而且这个乱序是不会被用户感知的。
跟Mencius相比,Mencius本质上是按command id做了partition,replica轮流作为proposer,顺序是预先定义的。
跟SDPaxos相比,PFR在稳定leader的情况下,也是leader定序。
所以仅从leader定序的角度看,PFR大约勉强可以放在SDPaxos和EPaxos之间(Mencius有序空间的partition,所不太好安置位置)。